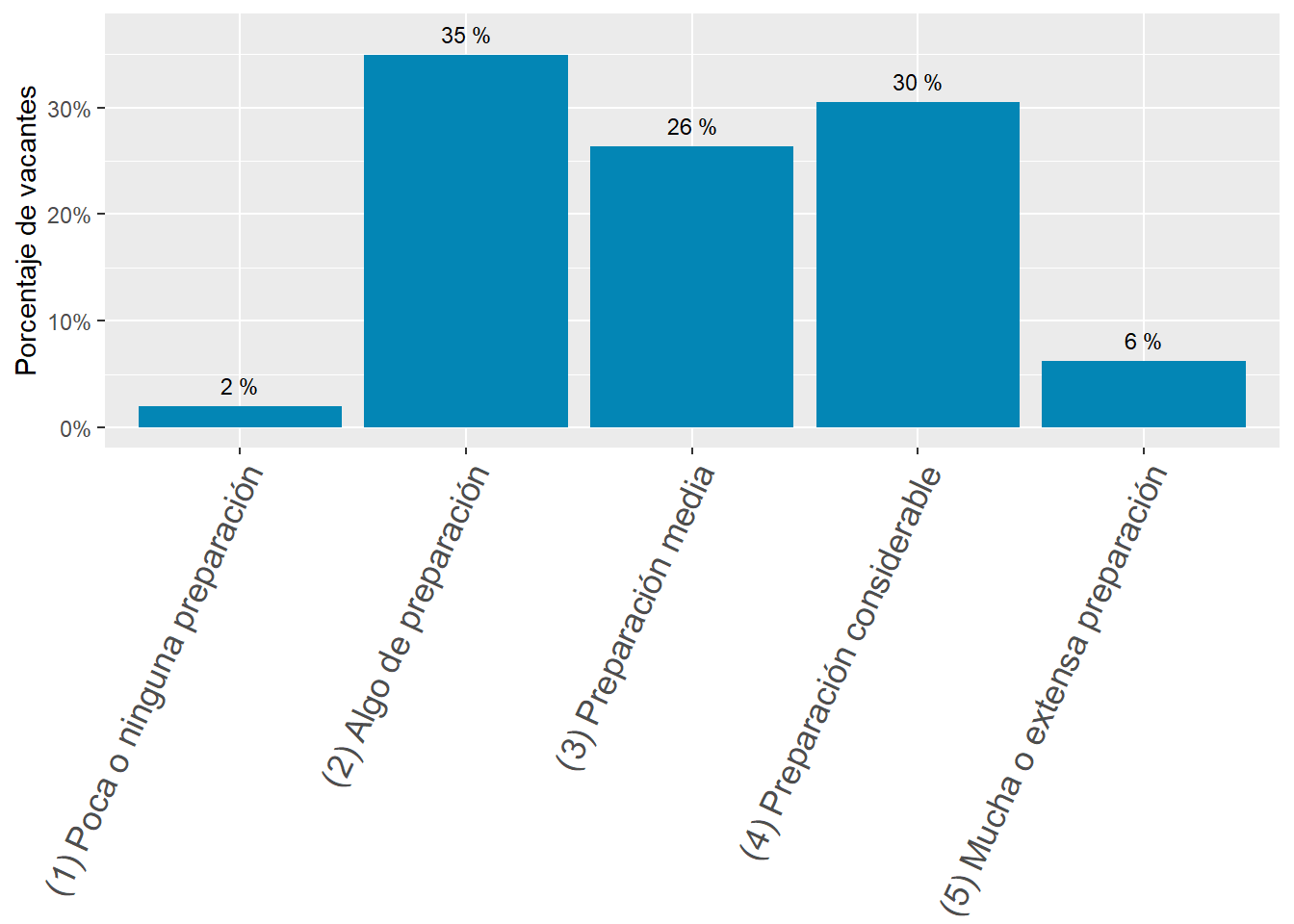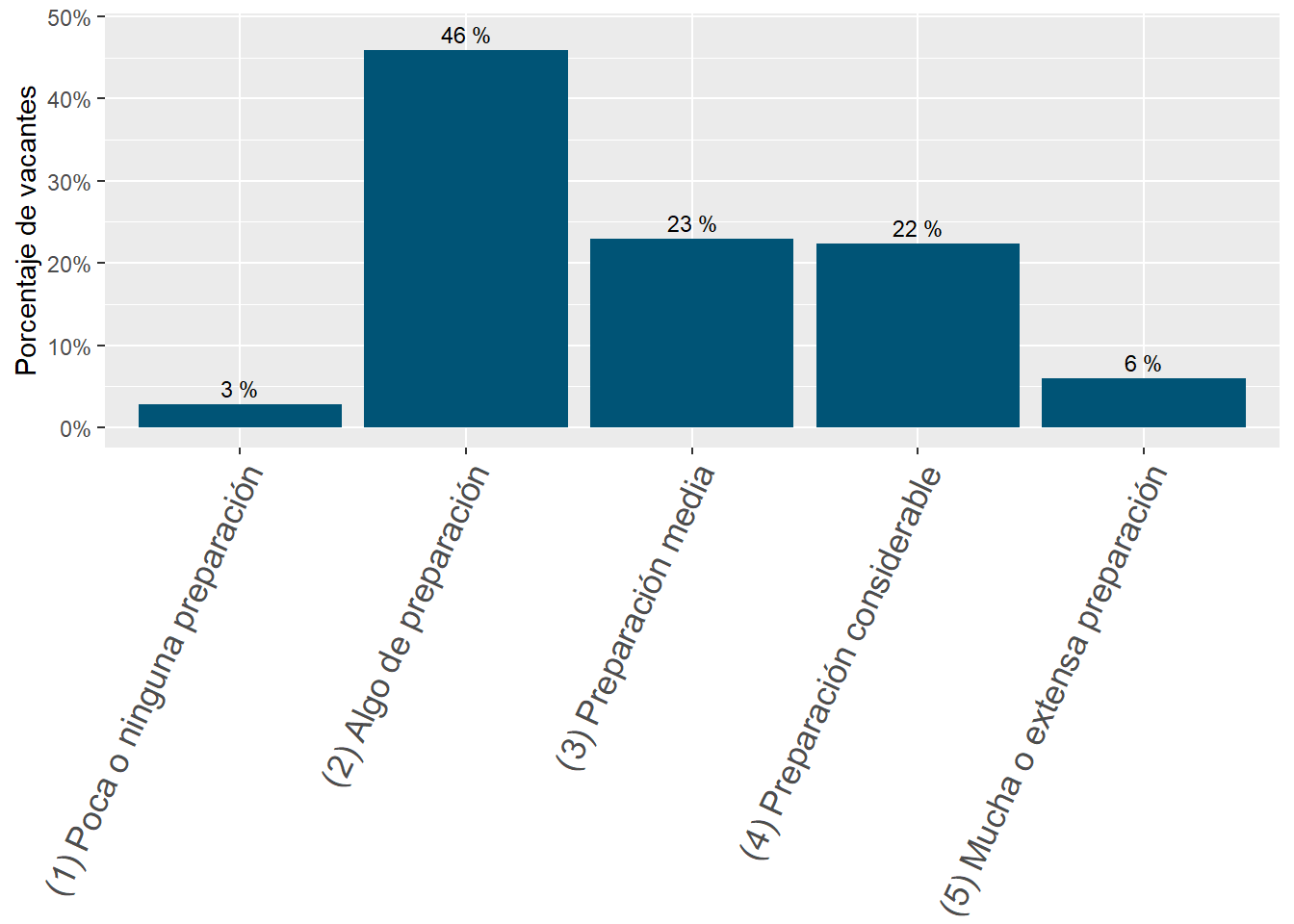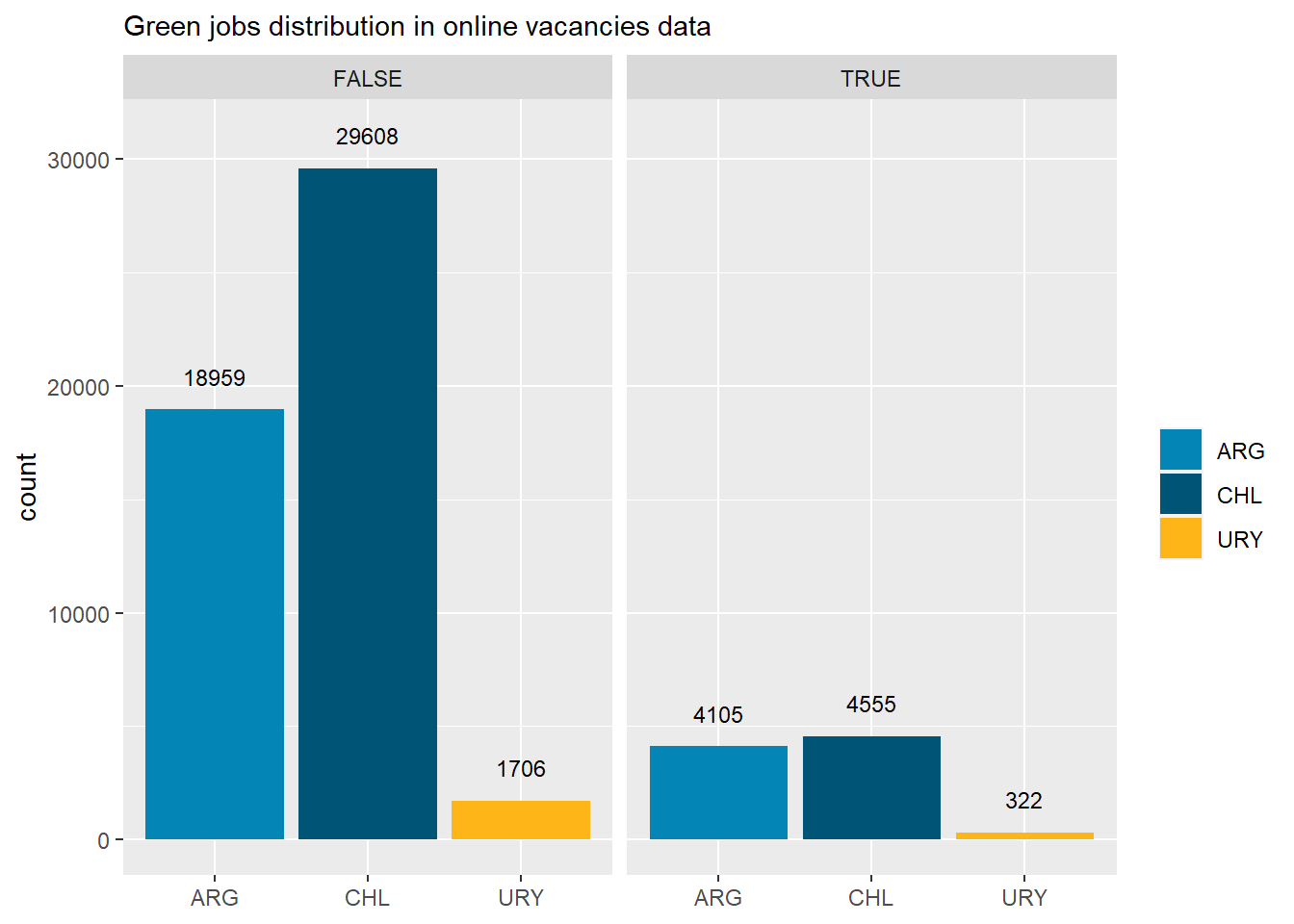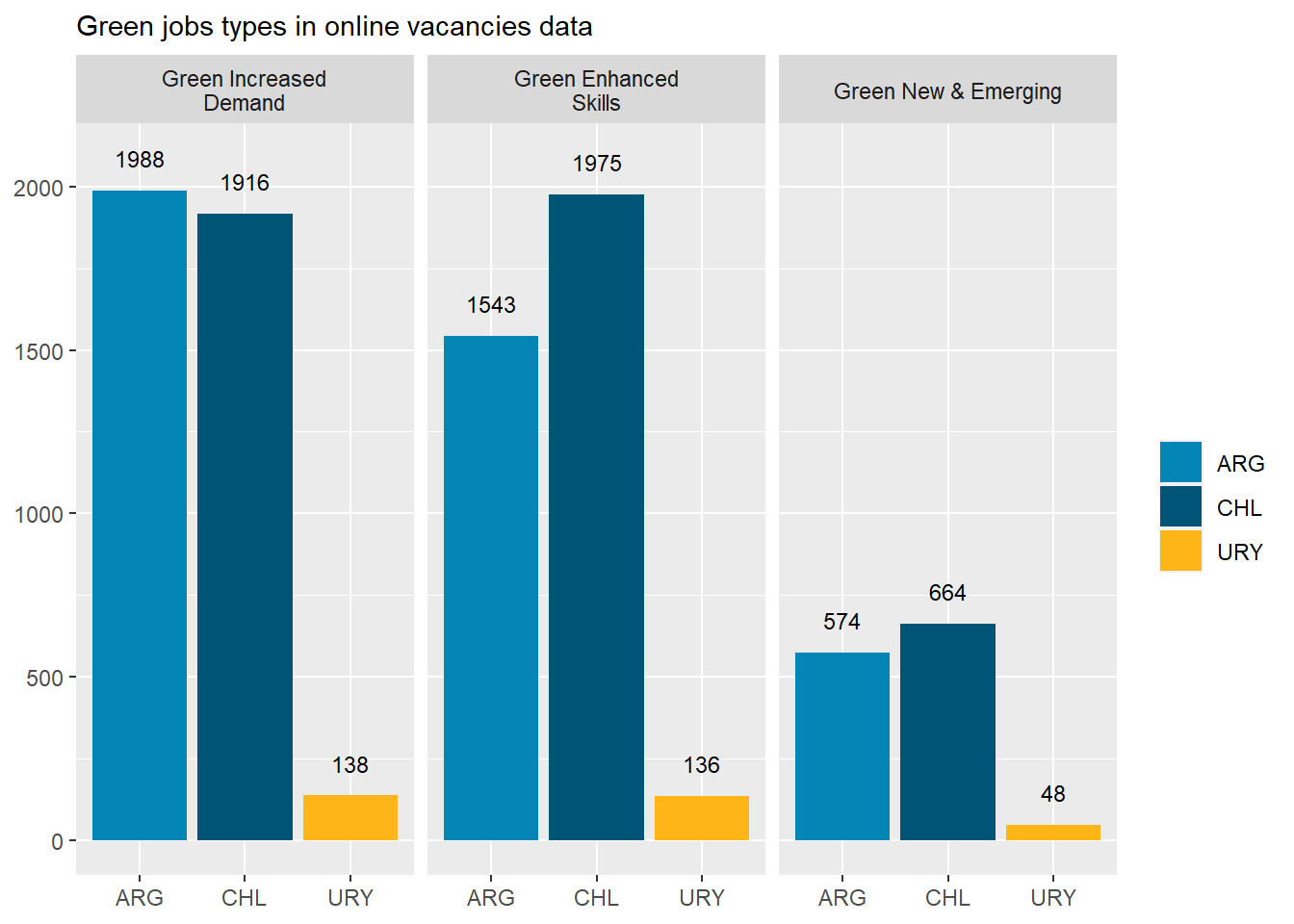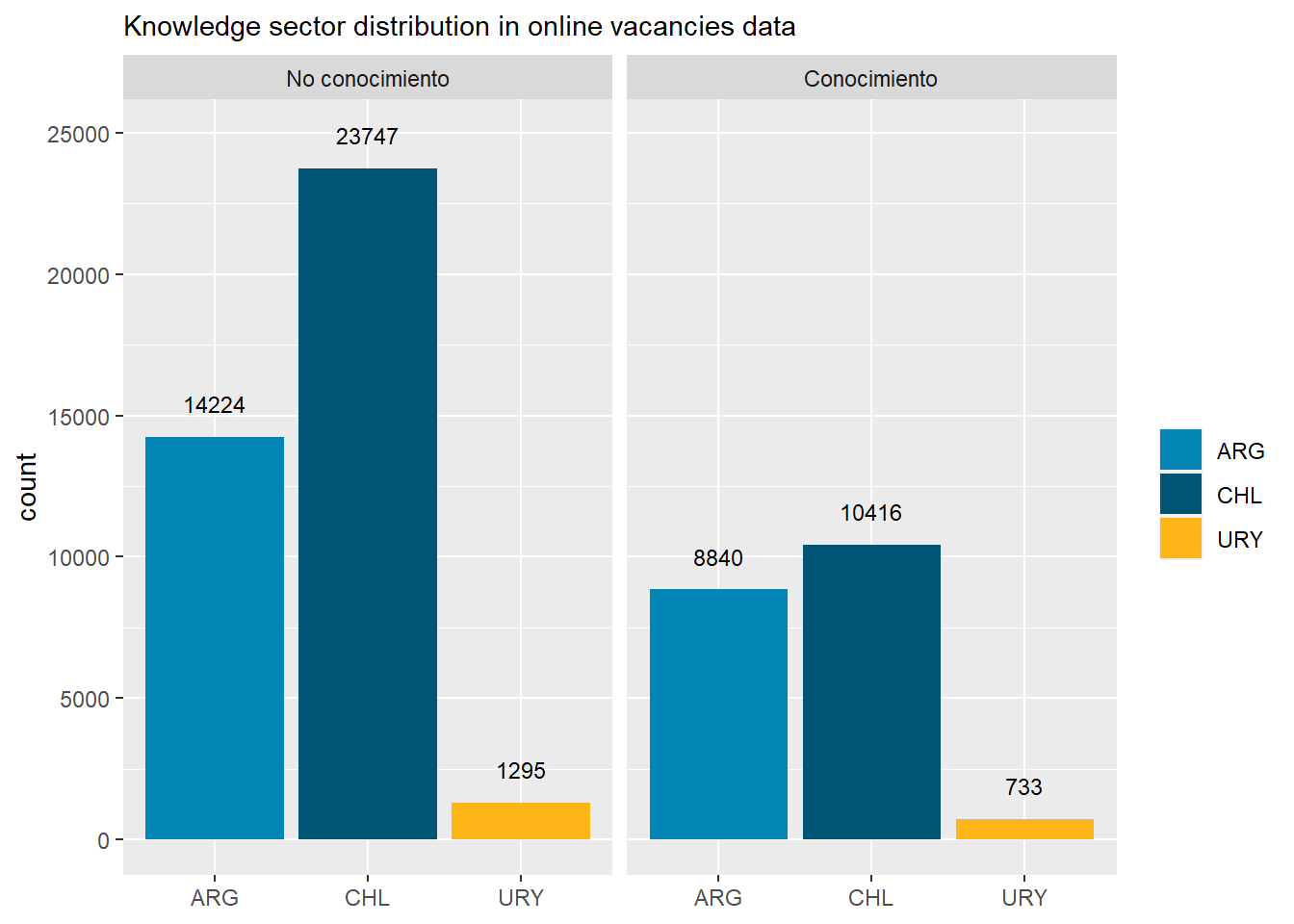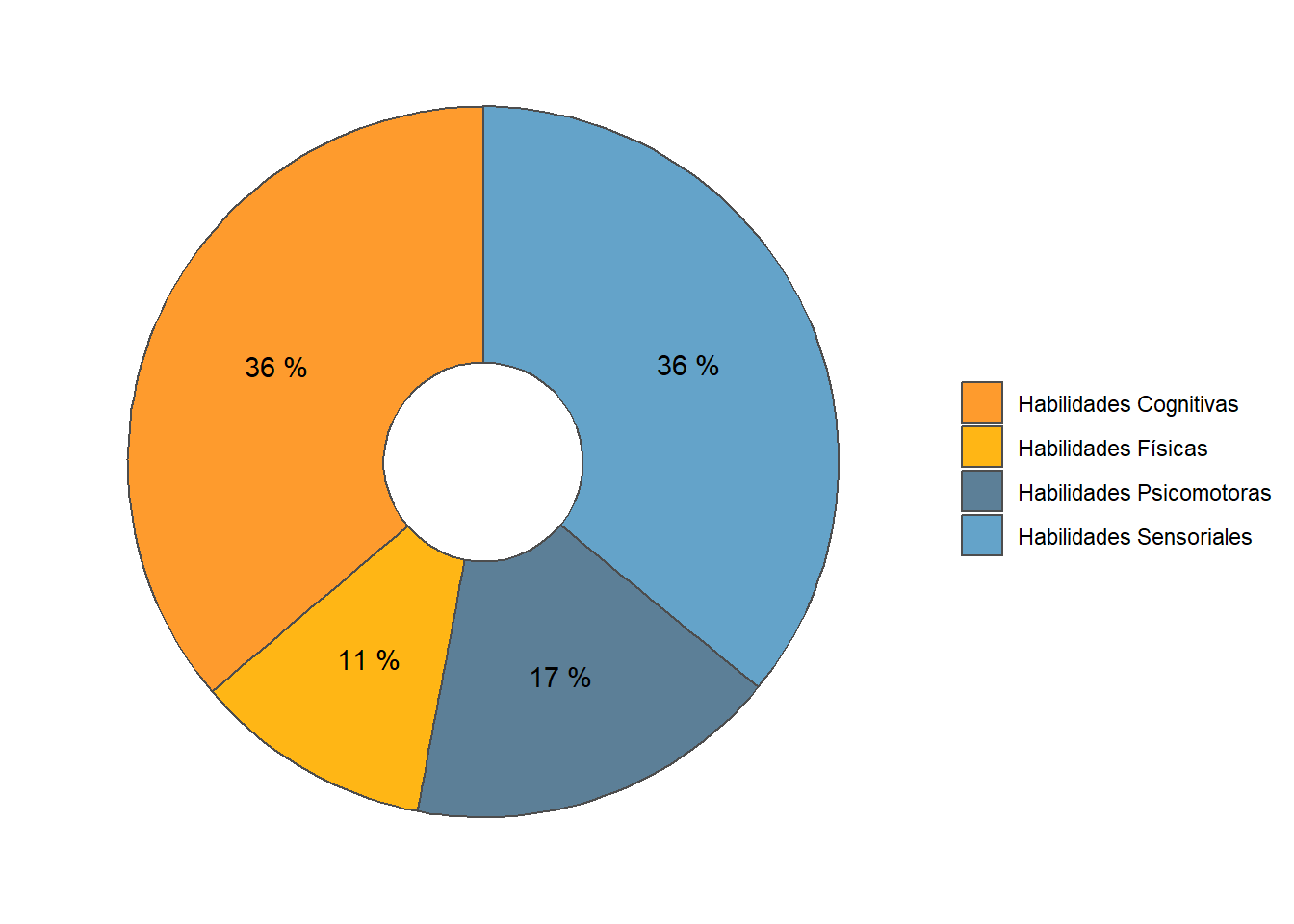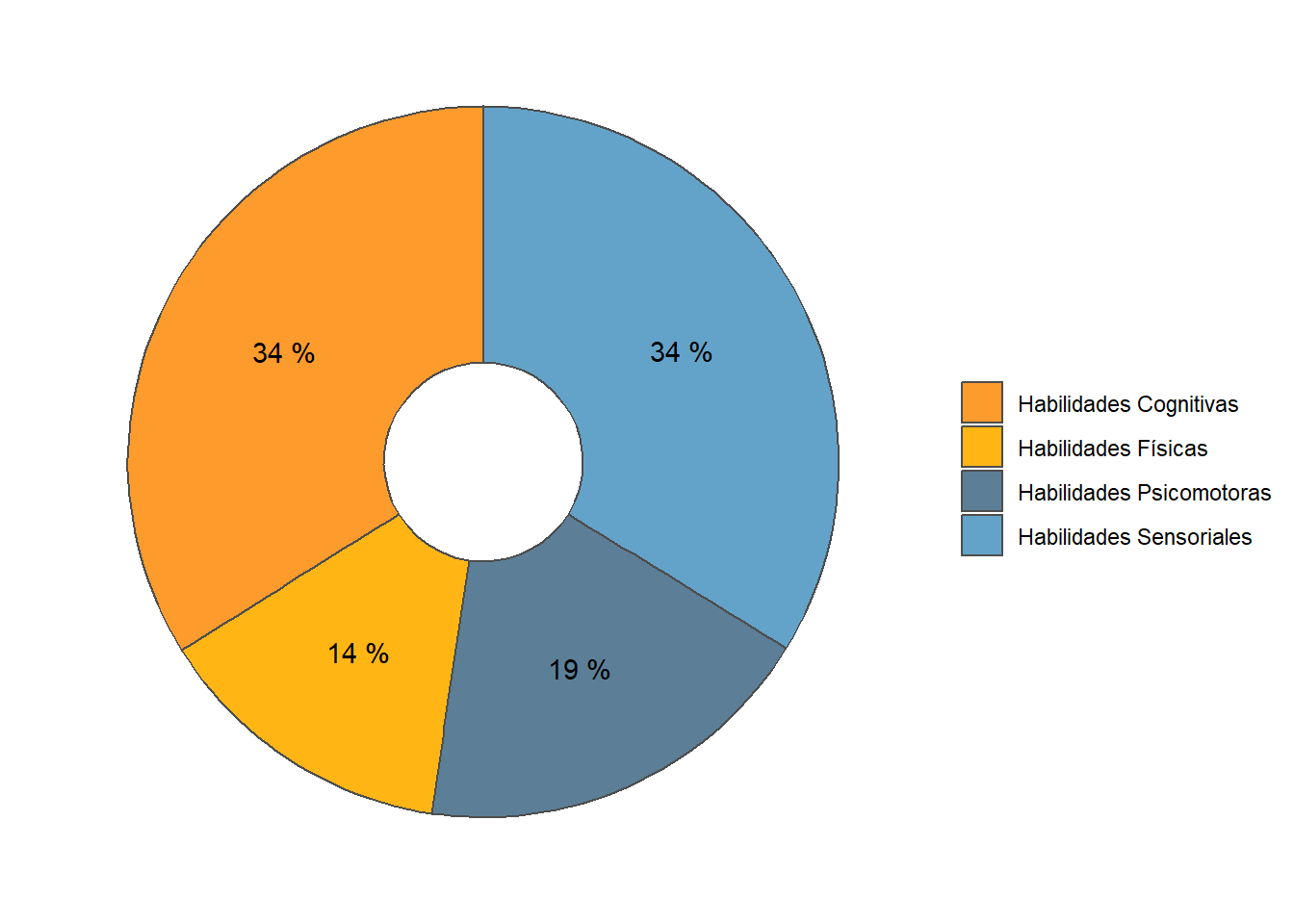A whiteboard to understand the data, test ideas, and shape our deliverables
Author
Carlos Daboin Contreras
Code
# librarieslibrary(arrow)library(readr)library(dplyr)library(tidyr)library(ggplot2)library(ggrepel)library(stringr)# source file with recurrent functionssource("etl_and_viz_functions.R")# Set colors for plotsGrey<-"#9c938e"#18.7%Yellow<-"#fdb517"#8.9 %Blue<-"#005476"#7.9 %Blue_2<-"#0386b5"Yellow_2<-"#fcecb3"#1.4 %Yellow_3<-"#f1c259"#1.4 %Blue_3<-"#b0cbd2"#1.2 %Blue_4<-"#45788c"#1.2 %#country colorscountry_colors<-c("ARG"=Blue_2,"CHL"=Blue,"URY"=Yellow)binary_colors<-c(Blue_4,Yellow_3)sector_vars<-c('accommodation_and_food_services','administrative_and_support_services', 'agriculture_forestry_fishing_and_hunting','arts_entertainment_and_recreation', 'construction', 'educational_services','finance_and_insurance','government' , 'health_care_and_social_assistance', 'information', 'management_of_companies_and_enterprises', 'manufacturing','mining_quarrying_and_oil_and_gas_extraction', 'other_services_except_public_administration','professional_scientific_and_technical_services','real_estate_and_rental_and_leasing', 'transportation_and_warehousing', 'utilities','wholesale_trade', 'retail_trade')work_vars<-c('occupation','onet_job','schedule', 'zones', 'remote','green_job','area')origin_vars<-c('doc_id','date_posted','country_code','firm','source','rm','city','city_name')ability_vars<-c('Cognitive Abilities','Sensory Abilities','Physical Abilities','Psychomotor Abilities')subability_vars<-c('Arm-Hand_Steadiness', 'Auditory_Attention', 'Category_Flexibility','Control_Precision', 'Deductive_Reasoning', 'Depth_Perception', #'Dynamic_Flexibility','Dynamic_Strength', 'Explosive_Strength', 'Extent_Flexibility', 'Far_Vision', 'Finger_Dexterity', 'Flexibility_of_Closure', 'Fluency_of_Ideas', 'Gross_Body_Coordination','Gross_Body_Equilibrium', 'Hearing_Sensitivity','Inductive_Reasoning', 'Information_Ordering','Manual_Dexterity', 'Mathematical_Reasoning','Memorization', 'Multilimb_Coordination','Near_Vision', 'Night_Vision','Number_Facility','Oral_Comprehension', 'Oral_Expression','Originality', 'Perceptual_Speed','Peripheral_Vision', 'Problem_Sensitivity' ,'Rate_Control', 'Reaction_Time','Response_Orientation', 'Selective_Attention', 'Sound_Localization', 'Spatial_Orientation','Speech_Clarity','Speech_Recognition','Speed_of_Closure', 'Speed_of_Limb_Movement','Stamina', 'Static_Strength','Time_Sharing', 'Trunk_Strength','Visual_Color_Discrimination','Visualization','Wrist-Finger_Speed','Written_Comprehension', 'Written_Expression')sectors_focus<-c("Professional Scientific And Technical Services","Health Care And Social Assistance","Transportation And Warehousing","Construction","Information","Agriculture Forestry Fishing And Hunting","Mining Quarrying And Oil And Gas Extraction")south_cone_df<-rbind(read_parquet("raw/arg_new_dict.parquet")|>select(origin_vars,work_vars,sector_vars,ability_vars,subability_vars),read_parquet("raw/chl_new_dict.parquet")|>select(origin_vars,work_vars,sector_vars,ability_vars,subability_vars),read_parquet("raw/ury_new_dict.parquet")|>select(origin_vars,work_vars,sector_vars,ability_vars,subability_vars))south_cone_df %>%summarise_at(sector_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=sector_vars)%>%mutate(total=sum(value))south_cone_df %>%summarise_at(ability_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=ability_vars)%>%mutate(total=sum(value))south_cone_df %>%summarise_at(subability_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=subability_vars)%>%mutate(total=sum(value))total_sector<-south_cone_df %>%select(doc_id,sector_vars)%>%pivot_longer(cols=sector_vars)%>%group_by(doc_id)%>%summarise(total_sector=sum(value,na.rm =TRUE))%>%mutate(total_sector=ifelse(is.nan(total_sector),1,total_sector))total_ability<-south_cone_df %>%select(doc_id,ability_vars)%>%pivot_longer(cols=ability_vars)%>%group_by(doc_id)%>%summarise(total_ability=sum(value,na.rm =TRUE))%>%mutate(total_ability=ifelse(is.nan(total_ability),1,total_ability))total_subability<-south_cone_df %>%select(doc_id,subability_vars)%>%pivot_longer(cols=subability_vars)%>%group_by(doc_id)%>%summarise(total_subability=sum(value,na.rm =TRUE))%>%mutate(total_subability=ifelse(is.nan(total_subability),1,total_subability))# Modificacion de datos inicialsouth_cone_df<-south_cone_df%>%## Modificacion de variables binariasmutate(area_bin=ifelse(area=="Conocimiento",TRUE,FALSE),green_job_bin=ifelse(is.na(green_job),FALSE,TRUE)) %>%## Modificacion de variables categoricasmutate(zones_label=case_when(zones==1~'(1) Poca o ninguna preparación', zones==2~'(2) Algo de preparación', zones==3~'(3) Preparación media', zones==4~'(4) Preparación considerable', zones==5~'(5) Mucha o extensa preparación')) %>%## Variable alternativa de sector: Sector de mas peso o Main Sectorleft_join(south_cone_df %>%select(doc_id,sector_vars) %>%pivot_longer(cols = sector_vars,names_to ="sector",values_to ="wt") %>%# keep max chances sectorgroup_by(doc_id) %>%filter(wt==max(wt)) %>%# remove duplicates in case there is a tie. Keep the first coming updistinct(doc_id,.keep_all = T) %>%ungroup() %>%mutate(sector=str_replace_all(sector,"_"," "),sector=str_to_title(sector)) %>%rename(main_sector=sector,main_sector_wt=wt), by="doc_id")%>%## Normalizar sectoresleft_join(total_sector, by="doc_id")%>%mutate(across(sector_vars,~./total_sector))%>%## Normalizar habilidadesleft_join(total_ability, by="doc_id")%>%mutate(across(ability_vars,~./total_ability))%>%## Normalizar subabilidadesleft_join(total_subability, by="doc_id")%>%mutate(across(subability_vars,~./total_subability))south_cone_df %>%summarise_at(sector_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=sector_vars)%>%mutate(total=sum(value))south_cone_df %>%summarise_at(ability_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=ability_vars)%>%mutate(total=sum(value))south_cone_df %>%summarise_at(subability_vars, ~mean(.,na.rm = T))%>%pivot_longer(cols=subability_vars)%>%mutate(total=sum(value))
Overview
This document can be considered a whiteboard or a catalog gathering all the insights and ideas we can think of as reflecting on Labor Demand in the South Cone via Online Job postings. Half the effort falls on understanding the data set nuances, while the other half is focused on collecting insights around the Energy Transition, Remote Work, Knowledge Sectors, Gender Inclusion, The Silver Economy, Immigrant labor assimilation, and Regional Economies.
It’s a work in progress.
Use the table of contents on the right to travel between document sections: TBD stands for To Be Done, while WIP stands for Work in Progress.
I’ve examined occupational, sector, abilities, sub-abilities, job zones, work schedules, regions, cities, and firm distributions of online job vacancies. I’ve also looked at the distribution of binary categories like green jobs, remote jobs, and knowledge jobs.
Overall, I can say that:
The figures presented here are based on a month of data. It goes from September 25 to October 26.
That amounts to 60.000 job postings. Chile accounts for about 58%, Argentina for 38% and Uruguay for 4%. Remember that Chile, Argentina, and Uruguay account for 39%, 54%, and 7% of formal employment in the South Cone, respectively. See Table 1
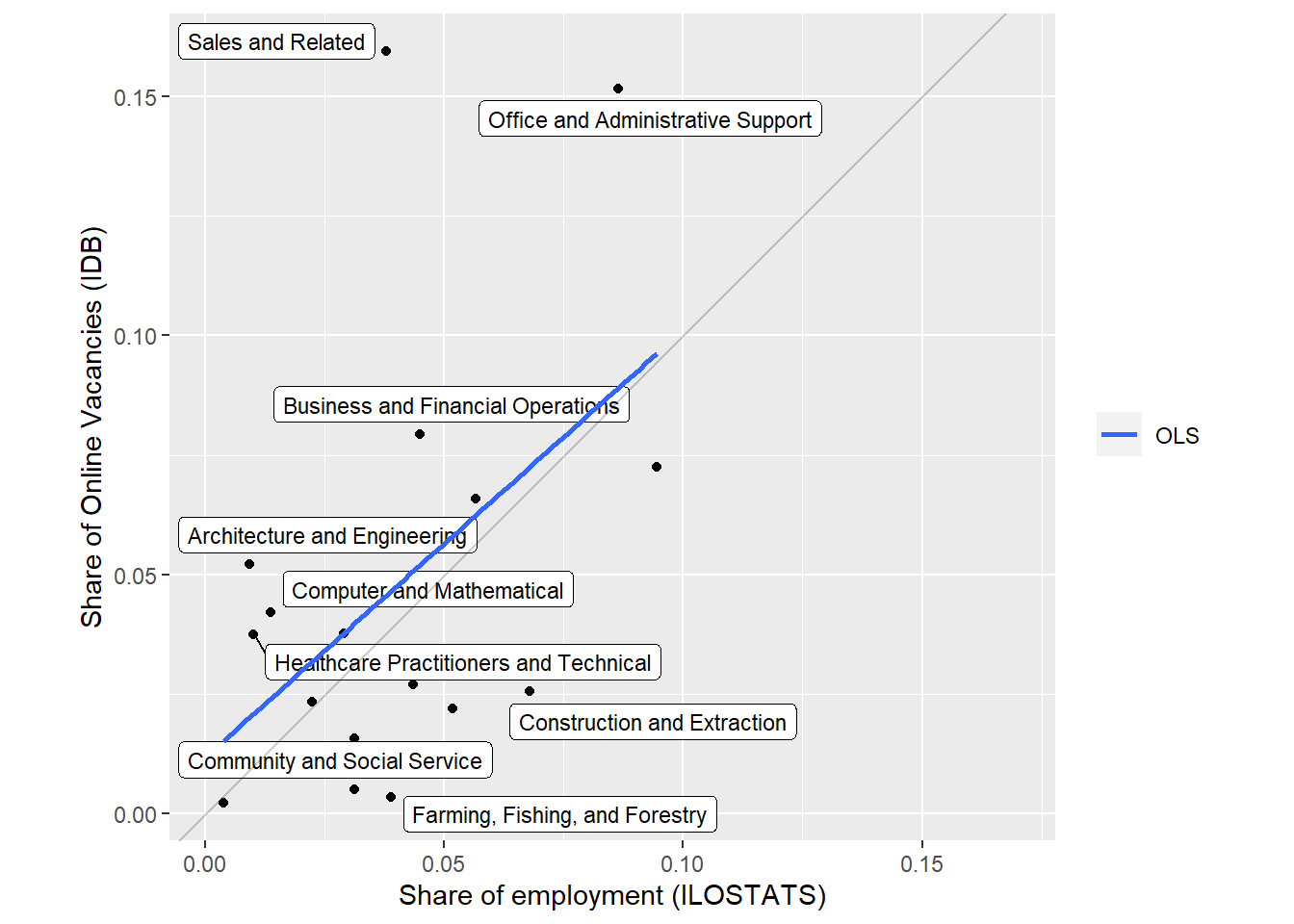
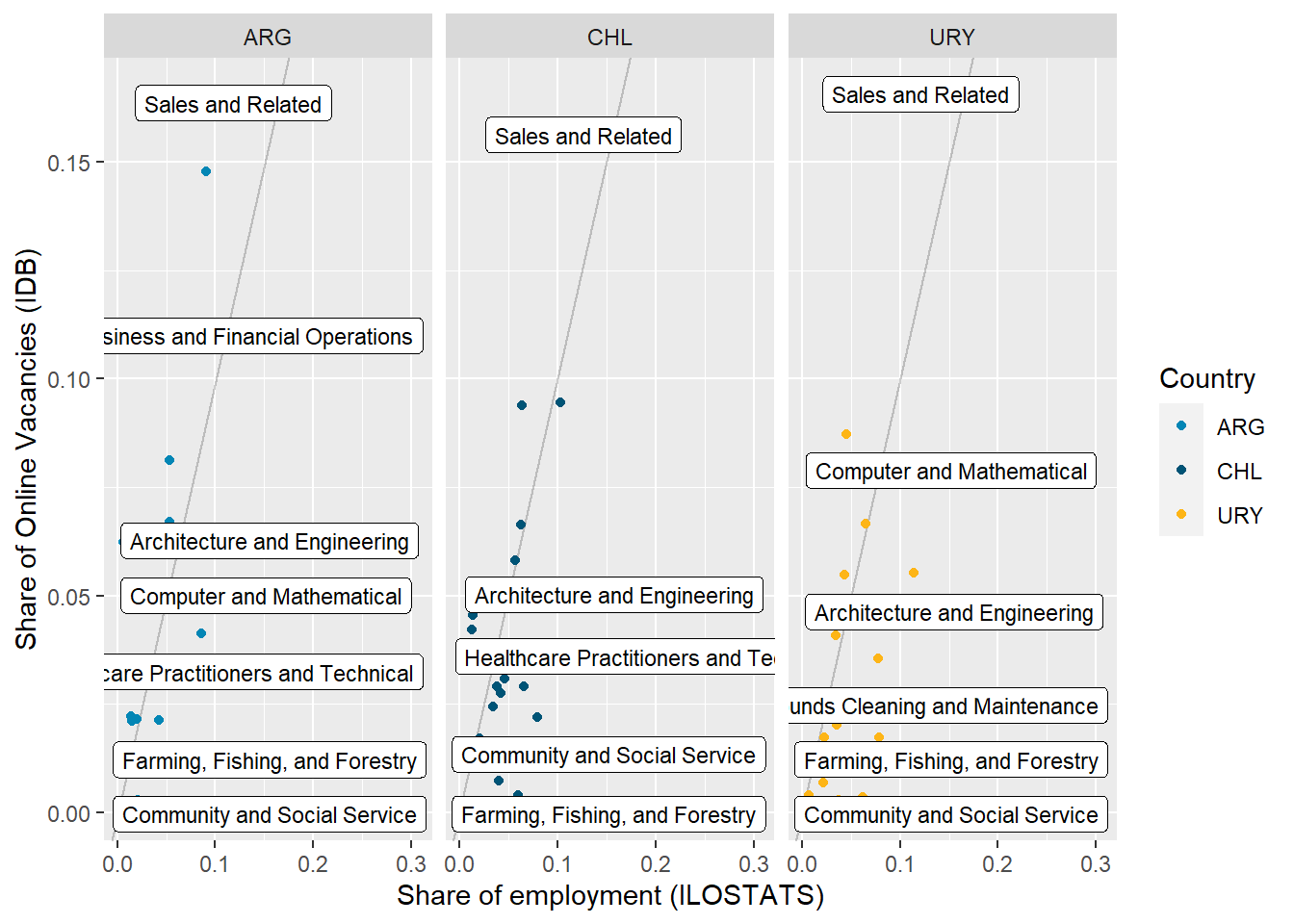
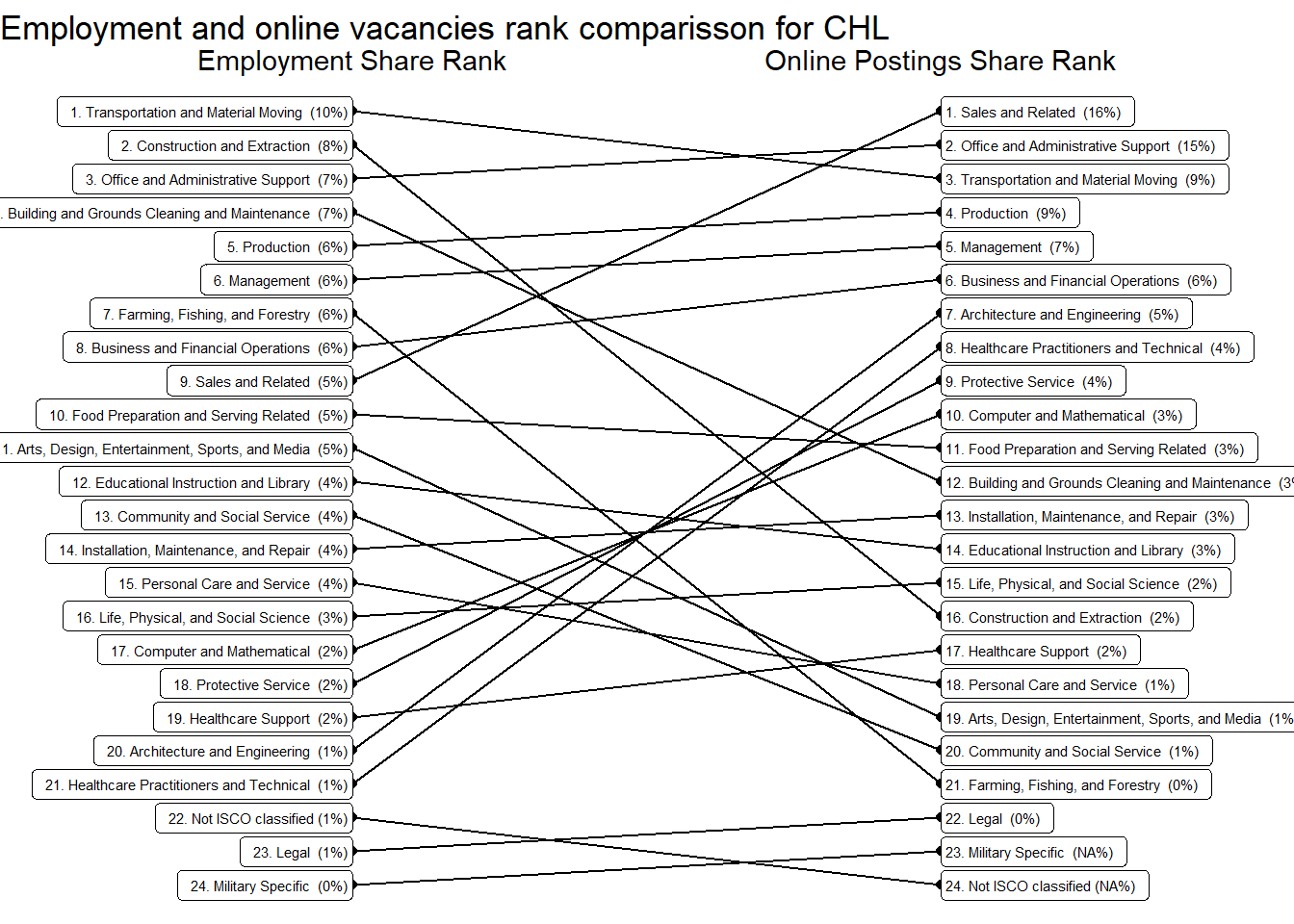
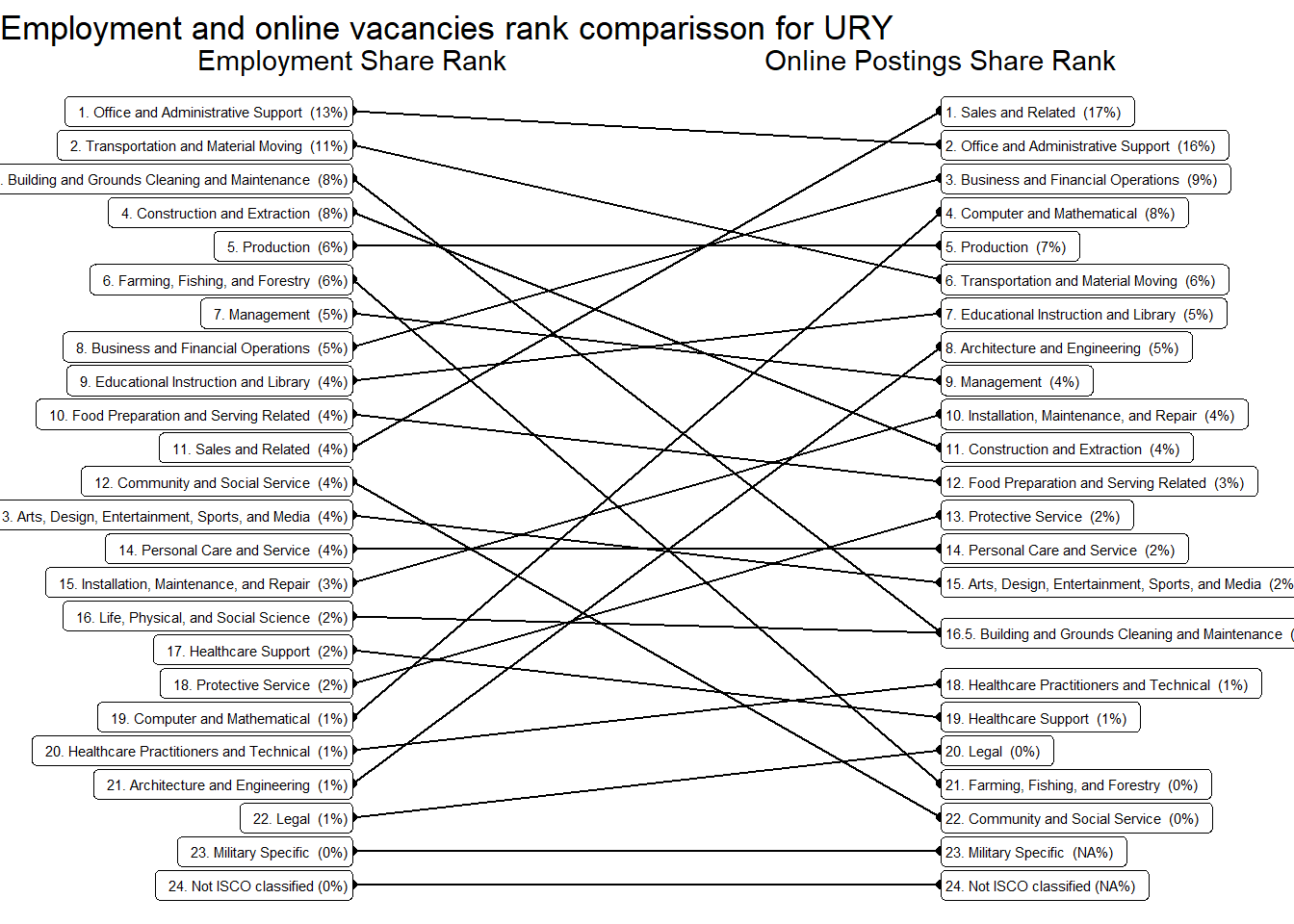
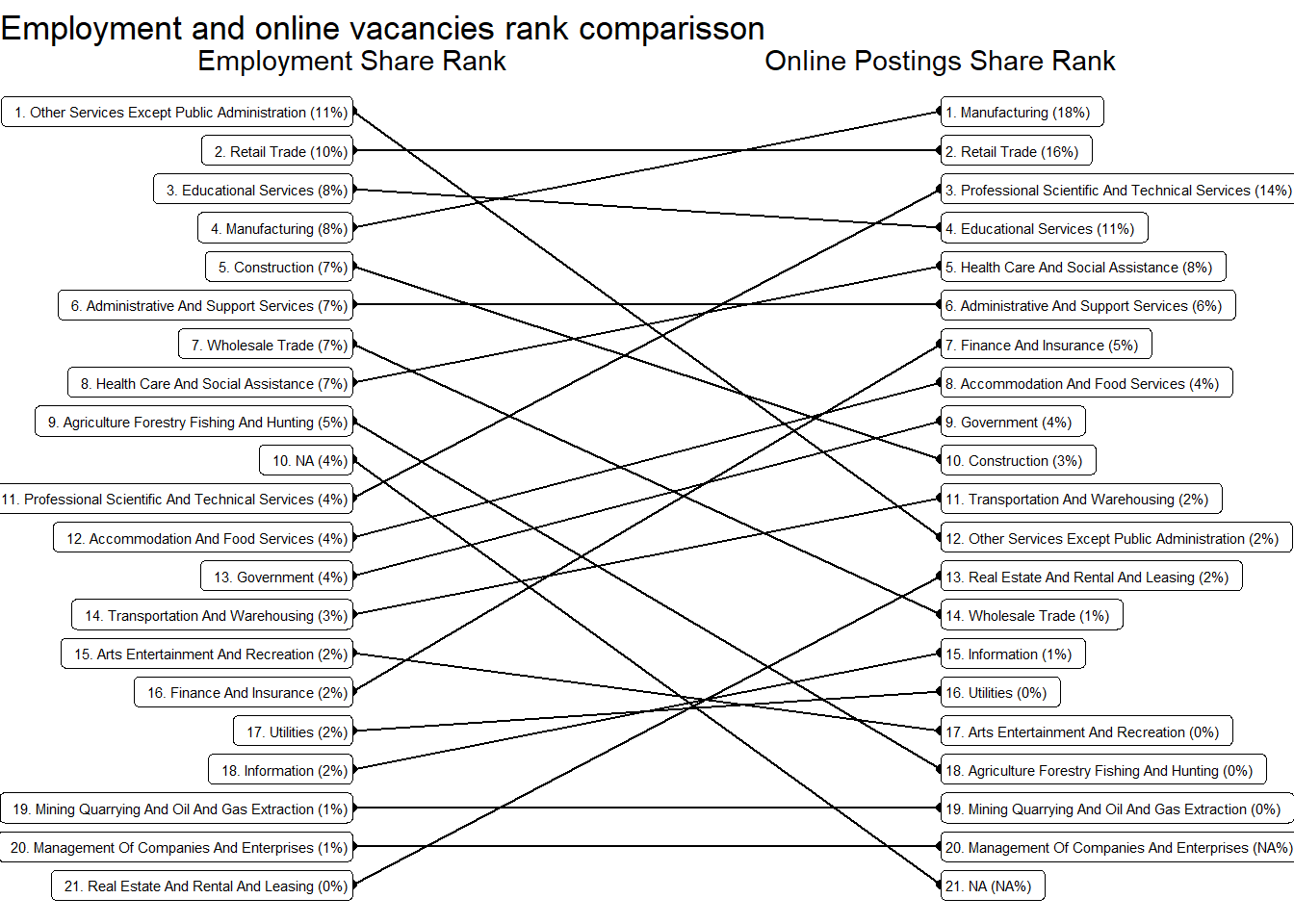
We compared occupations shares in total employment with their share in online job vacancies. The following major occupational groups are over-represented in the latter: “Sales and Related Occupations”, “Healthcare Practitioners and Technical Occupations”, “Architecture and Engineering Occupations”, “Office and Administrative Support Occupations”, “Protective Service Occupations”, “Computer and Mathematical Occupations” , “Production Occupations”, “Management Occupations”, “Business and Financial Operations Occupations,” in that order. See Table 12.
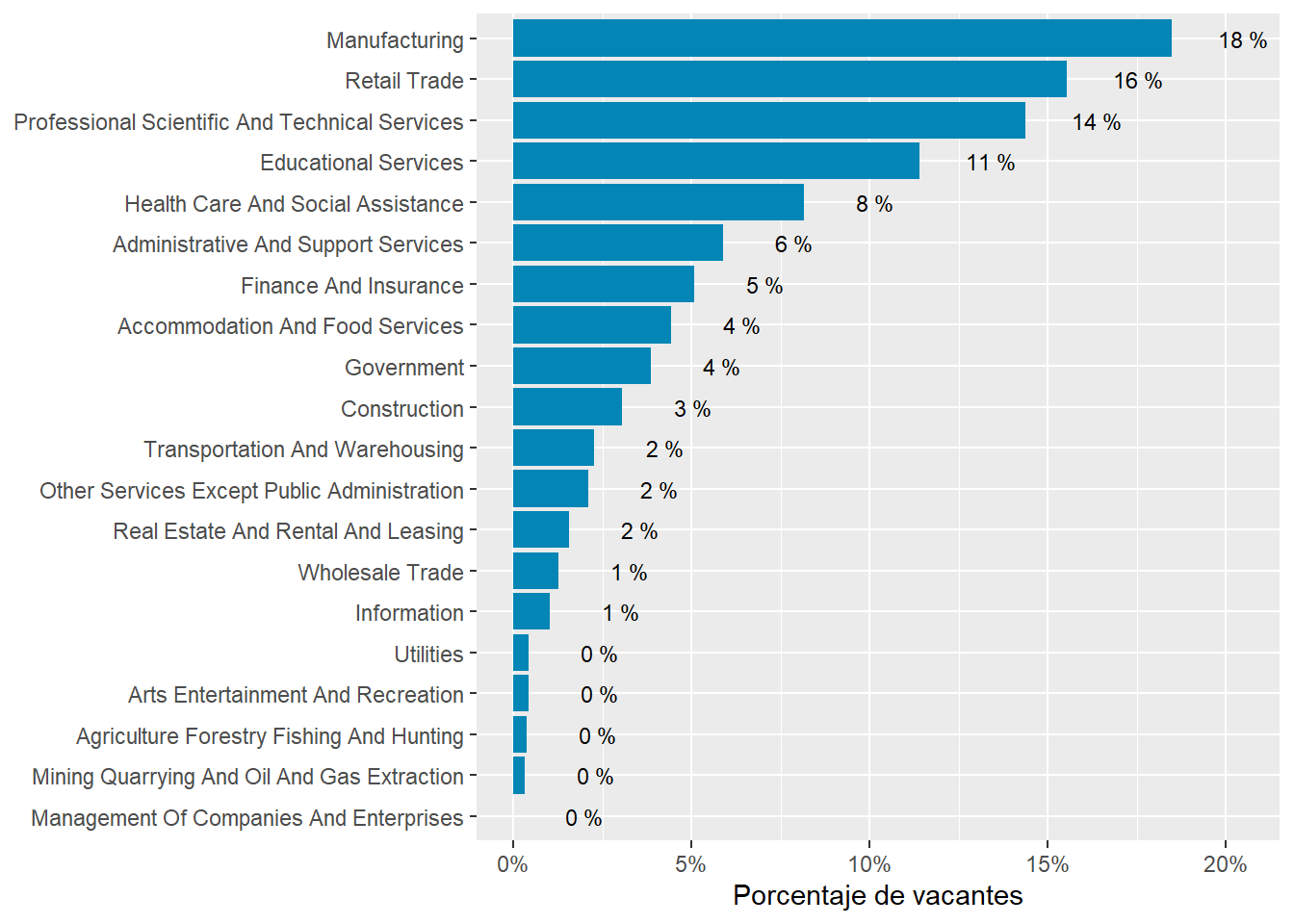
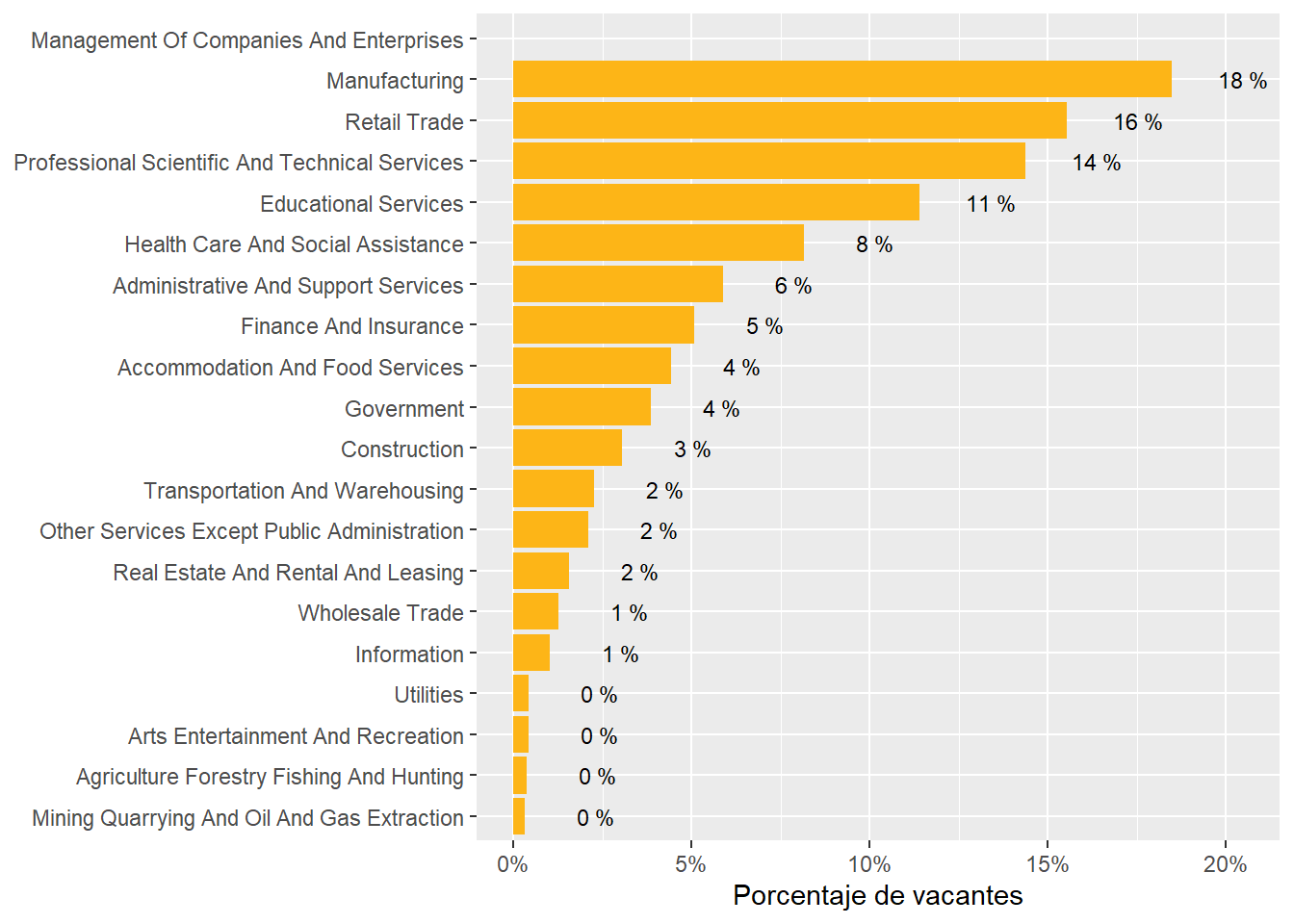
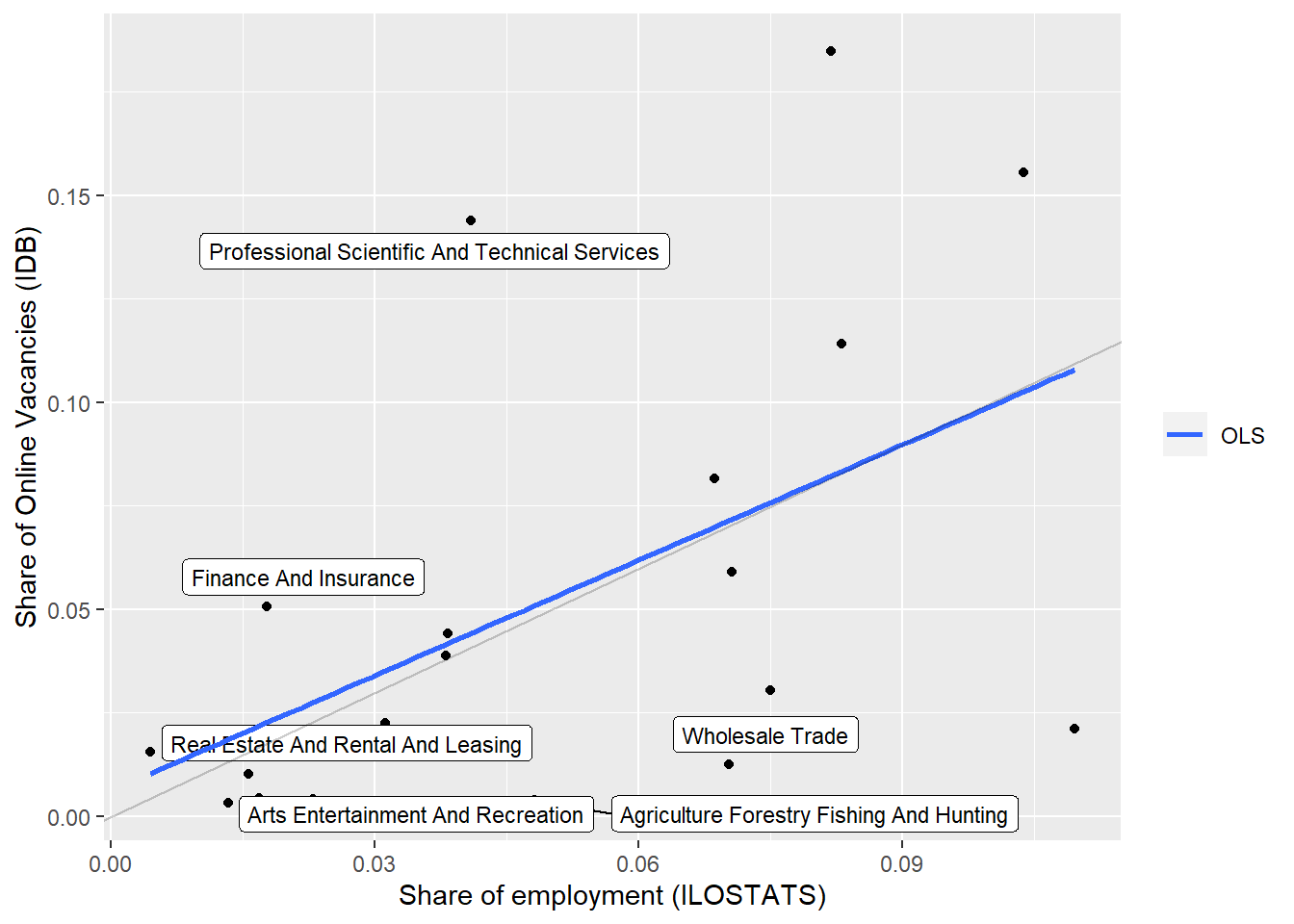
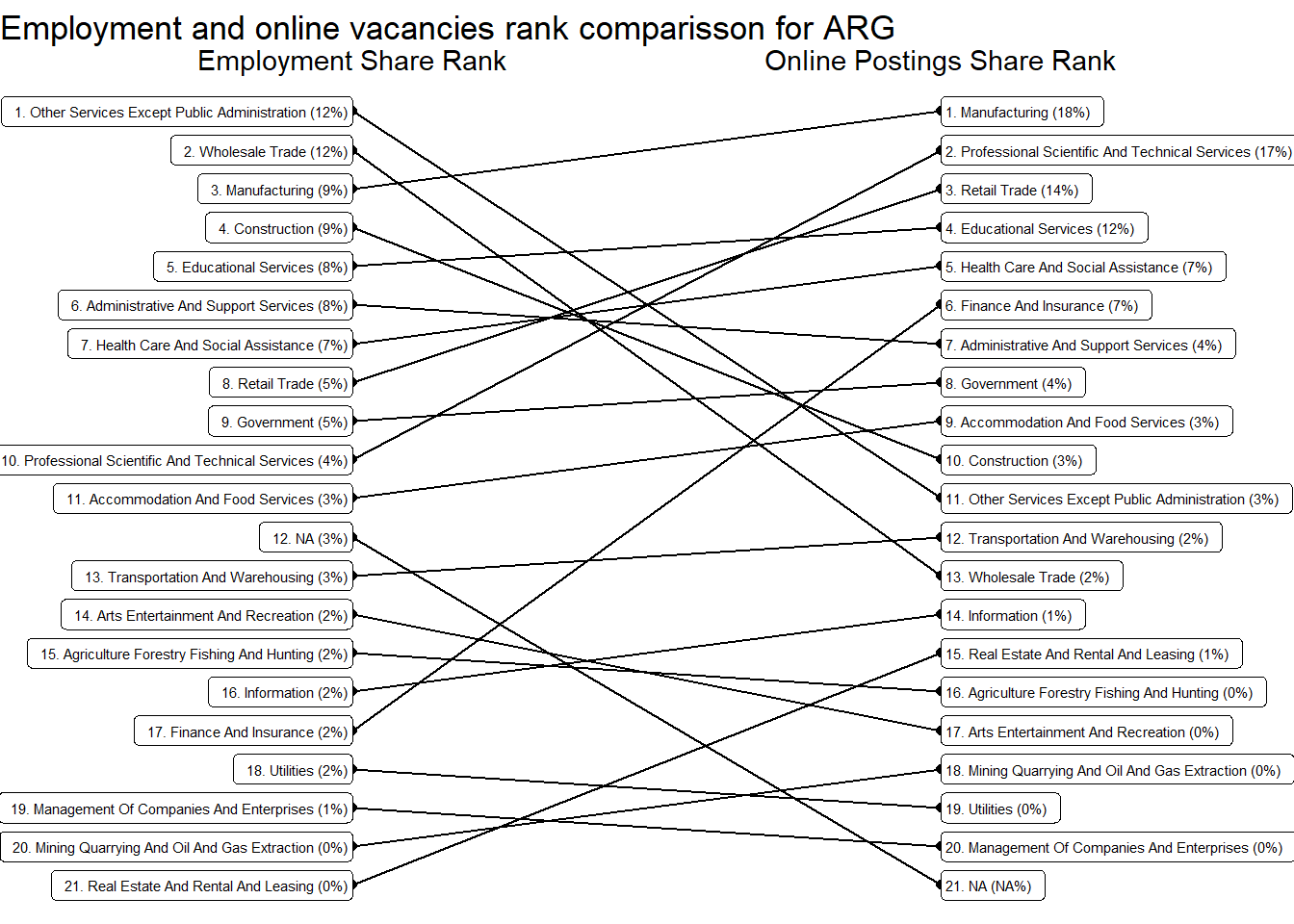
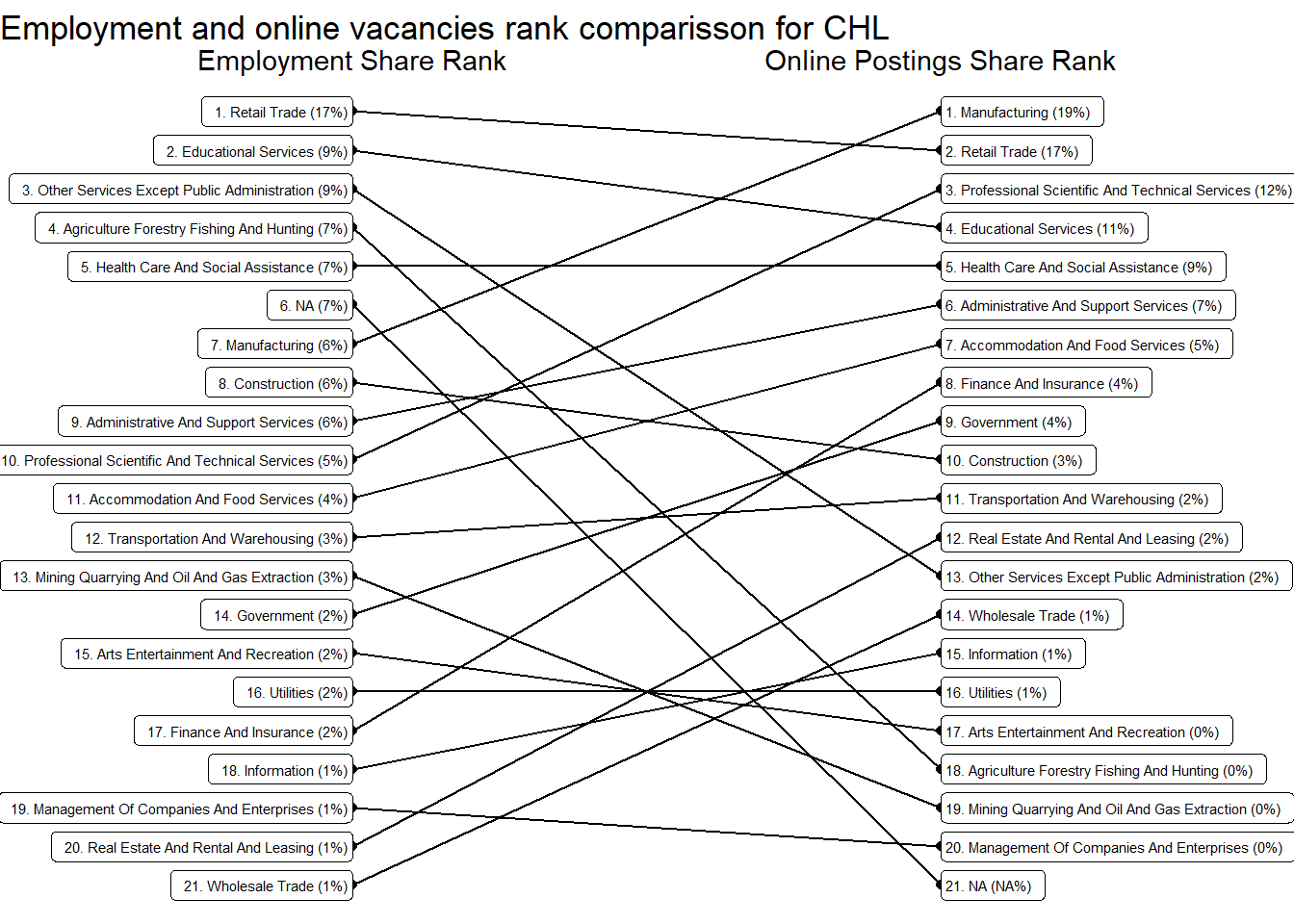
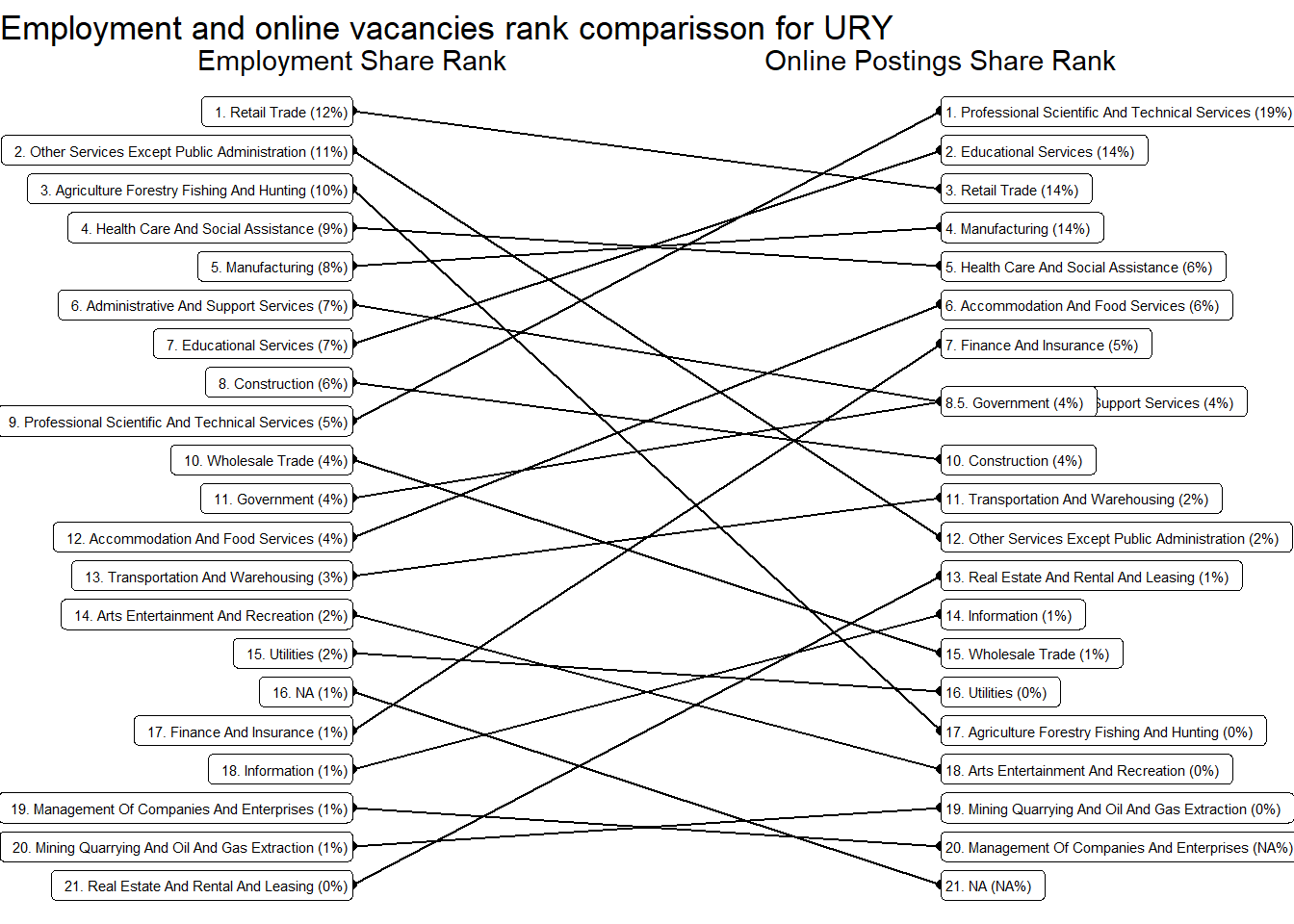
We obtained similar conclusions at the sector level. The following sectors are over-represented in online job postings: “Real Estate And Rental And Leasing”, “Professional Scientific And Technical Services”, “Finance And Insurance”, Manufacturing, “Retail Trade”, “Educational Services”, “Health Care And Social Assistance”, and “Accommodation And Food Services”. See Table 13. Note that over represented means more common that would be expected by their share of employment.
Regions like Santiago (13000), Buenos Aires (9300), Valparaiso (4900), Concepcion (3774), Rosario (2316), and Gran Temuco (2125) have more online vacancies than Uruguay (2060). See Table 10
Differences between countries:
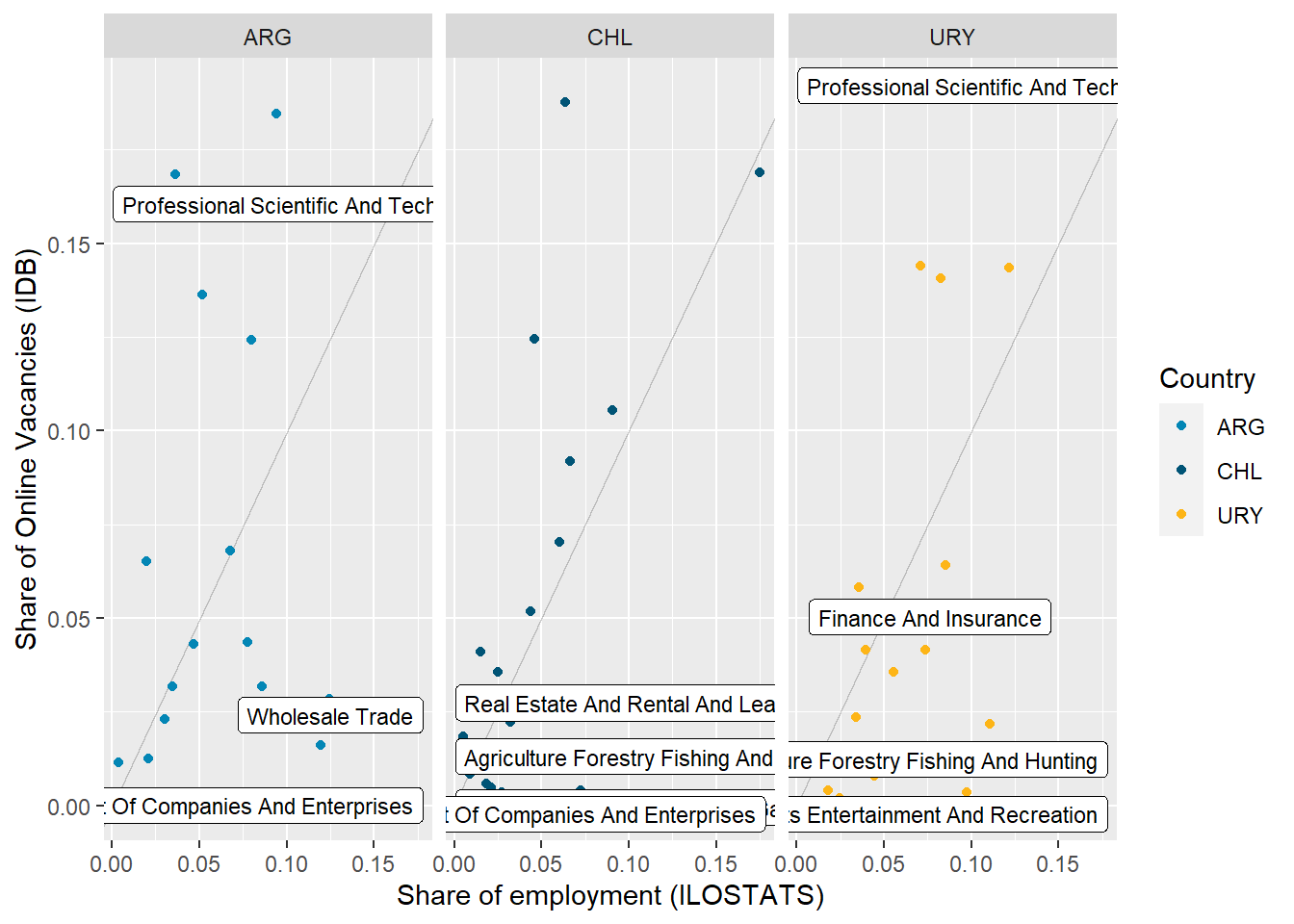
Argentina’s online job demand aims towards more educated, trained, and technical workers than Chile. This is evident in the job zones, and abilities distributions (see Figure 23 , Figure 12), but also foreseeable from the sector and occupational distributions alone (see Figure 9 , ?@fig-occupation_country). Uruguay mimics that in many ways, but we’re always less sure due to its narrow sample size.
Despite being 1.5x outsized by its’ andean neighbor, Argentina has more vacancies in “Financial Operation Occupations” and a similar number of vacancies in “Architecture and Engineering,” “Computer and Mathematical,” “Educational,” and “Construction and extraction” occupations (see ?@fig-occupation_country). It’s also remarkably close to Chile in the number of vacancies with “Considerable preparation” (Job Zone 4.)
When compared with it’s region neighbor, Chile has an extraordinary high number of openings asking for “Some Preparation” (Job Zone 2.) Indeed, these account for about 46% of all the sampled vacancies, 10 points more than URY and 11 points more than ARG.
Abilities and sub-abilities
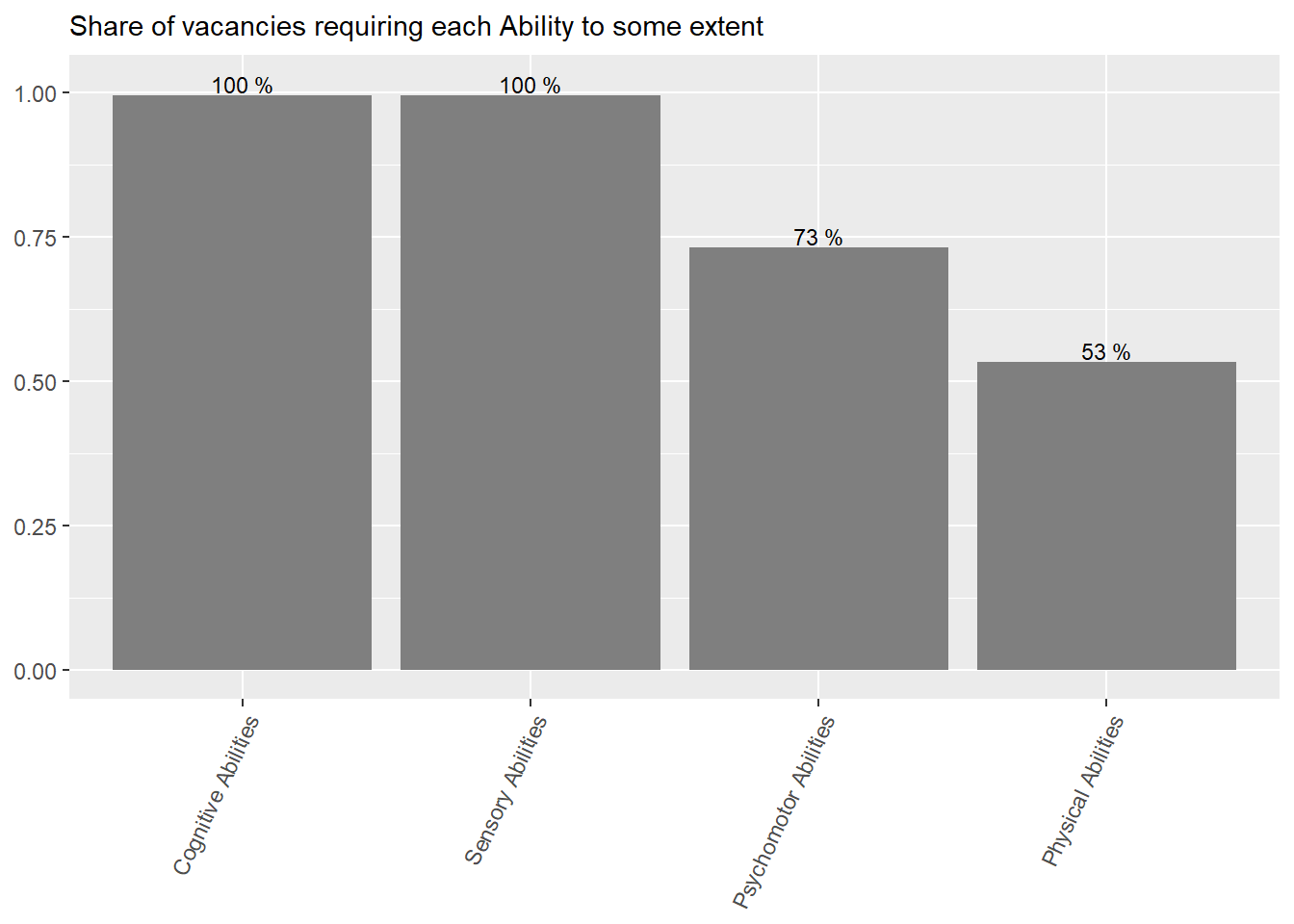
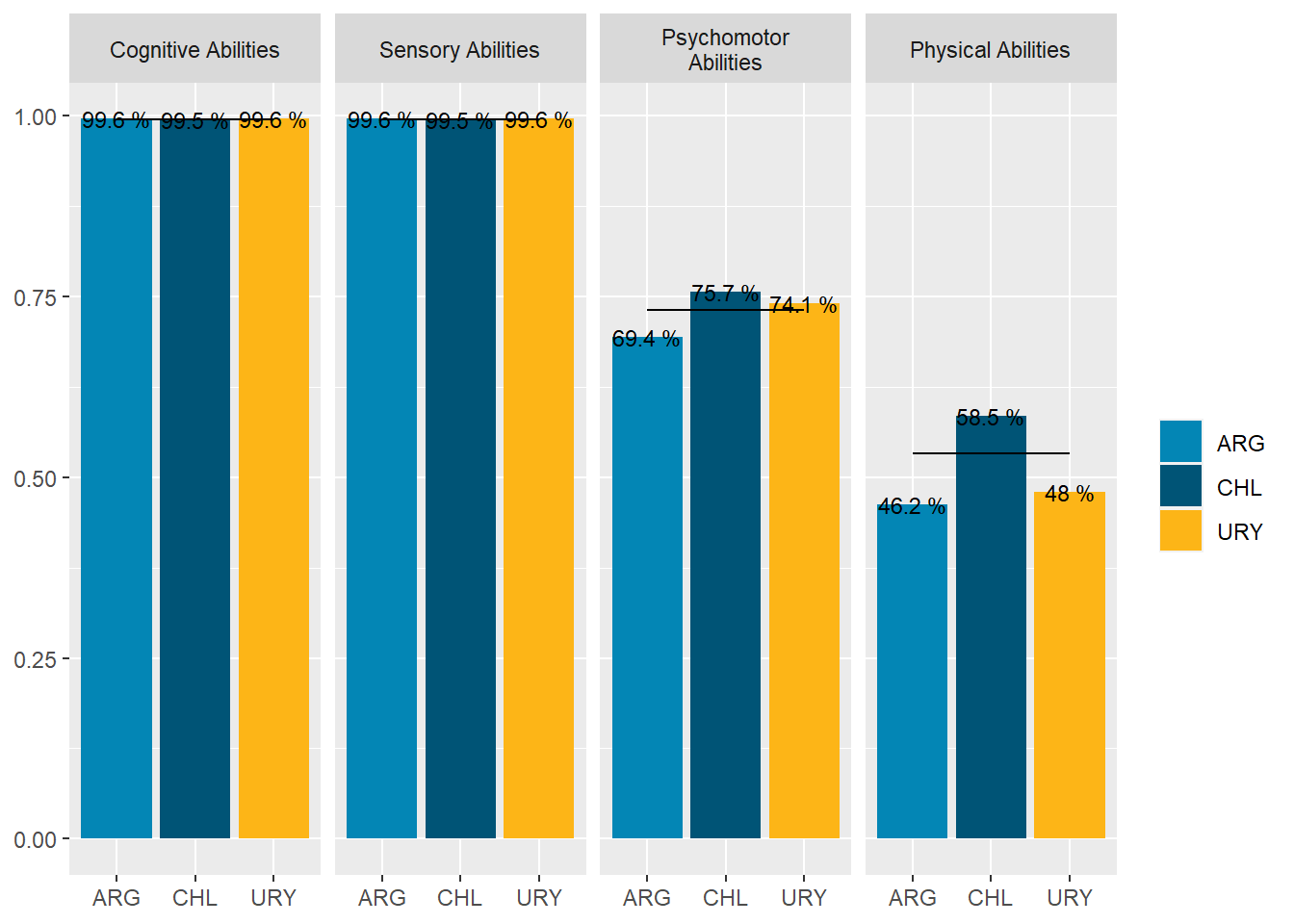
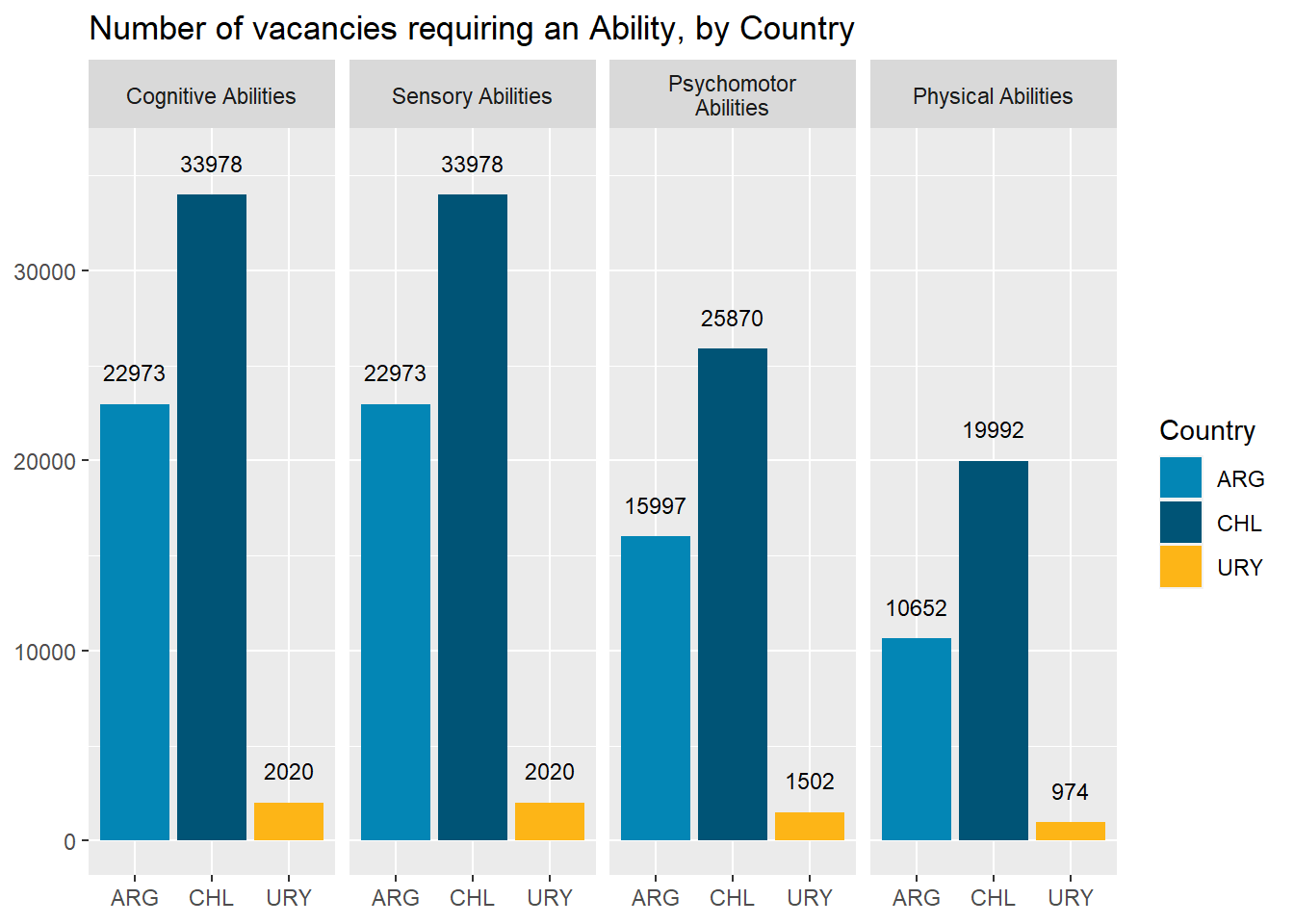
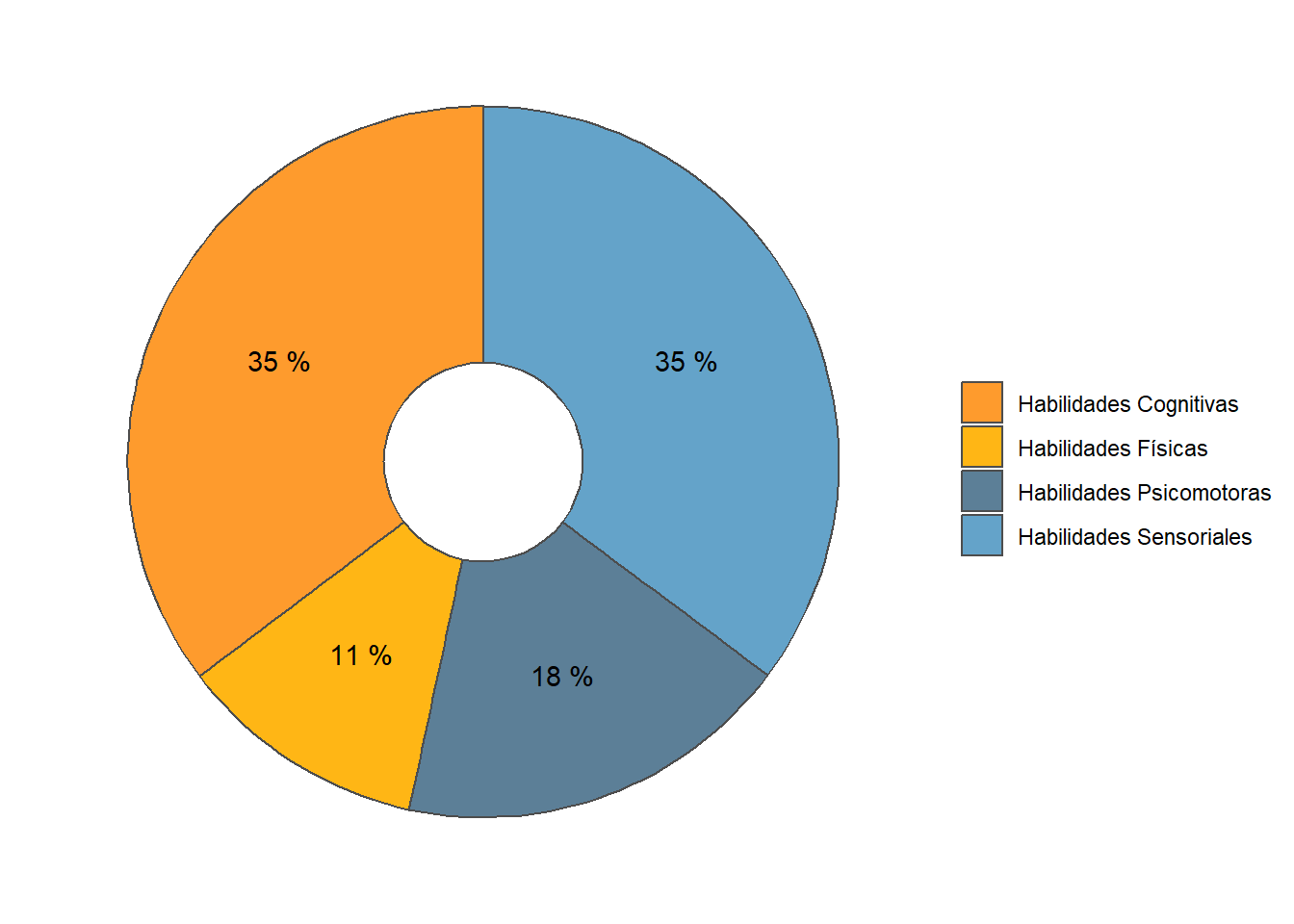
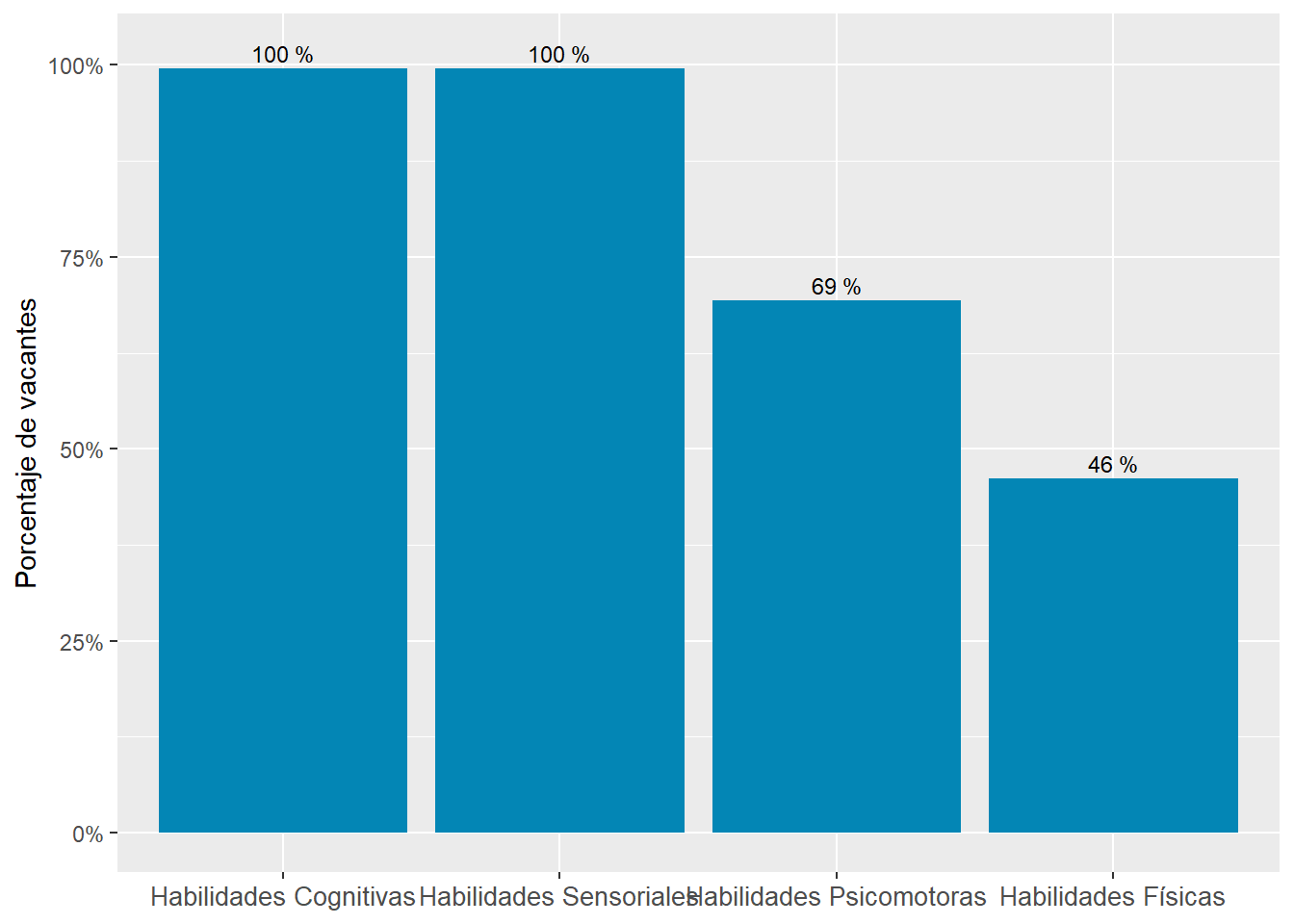
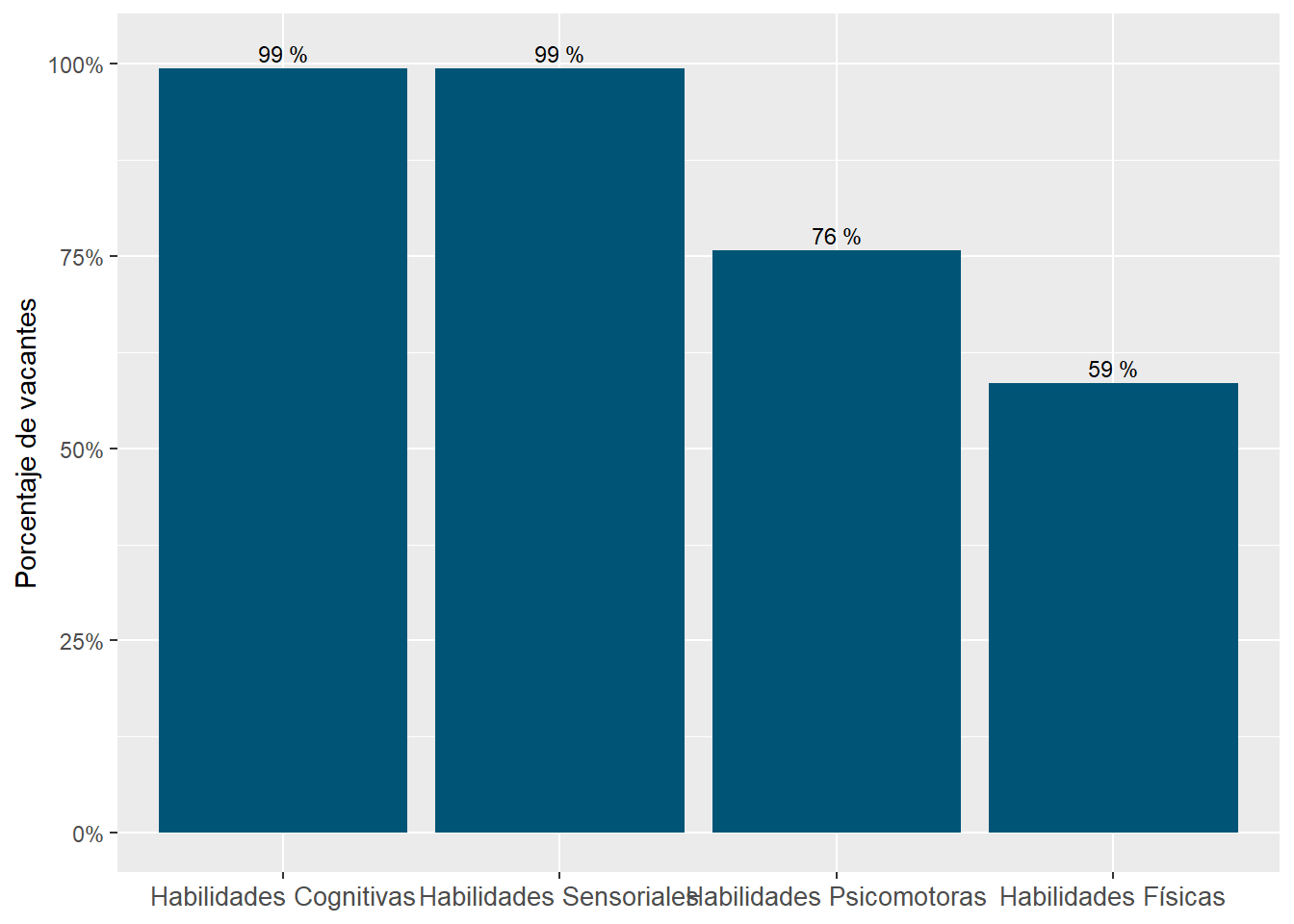
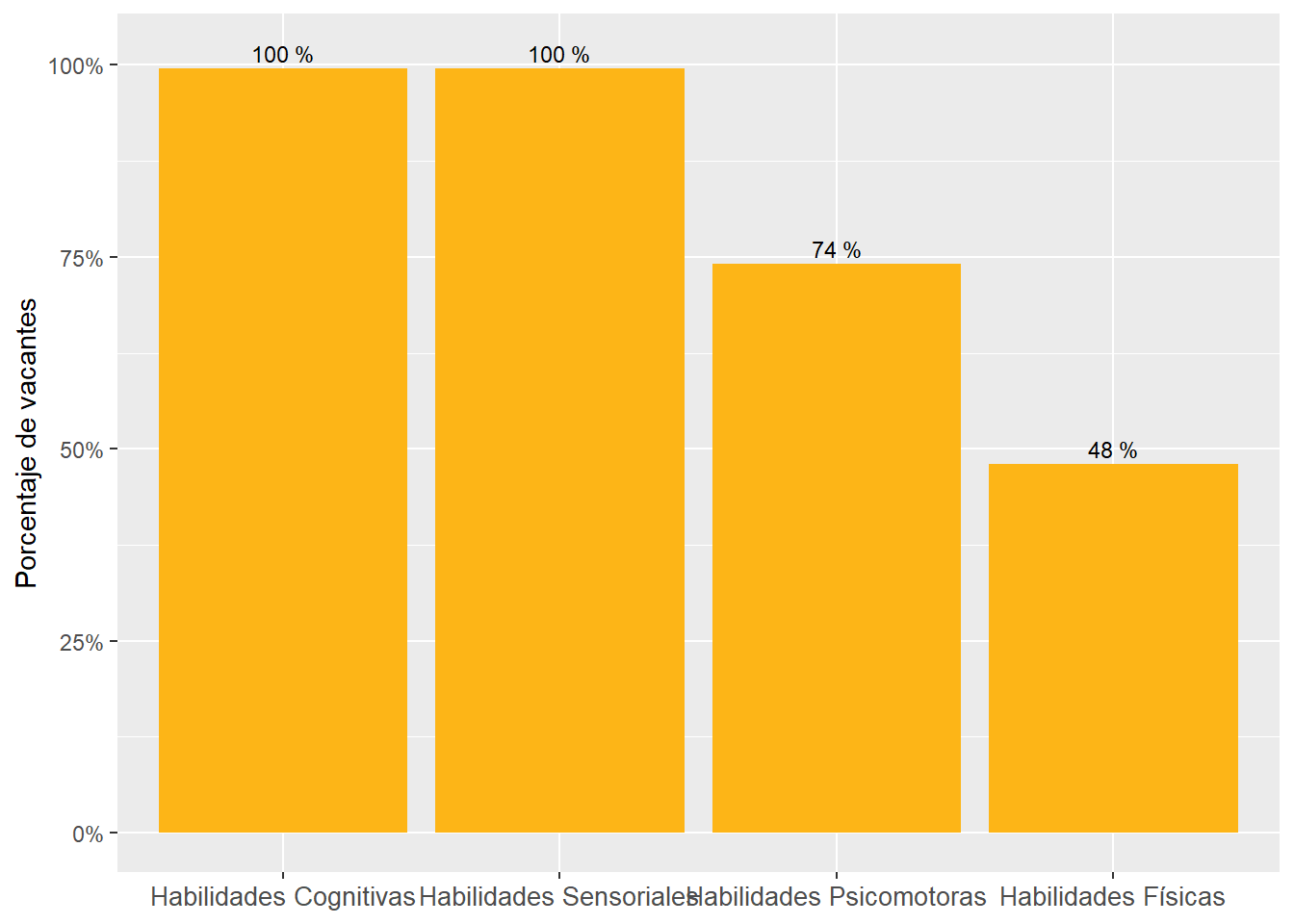
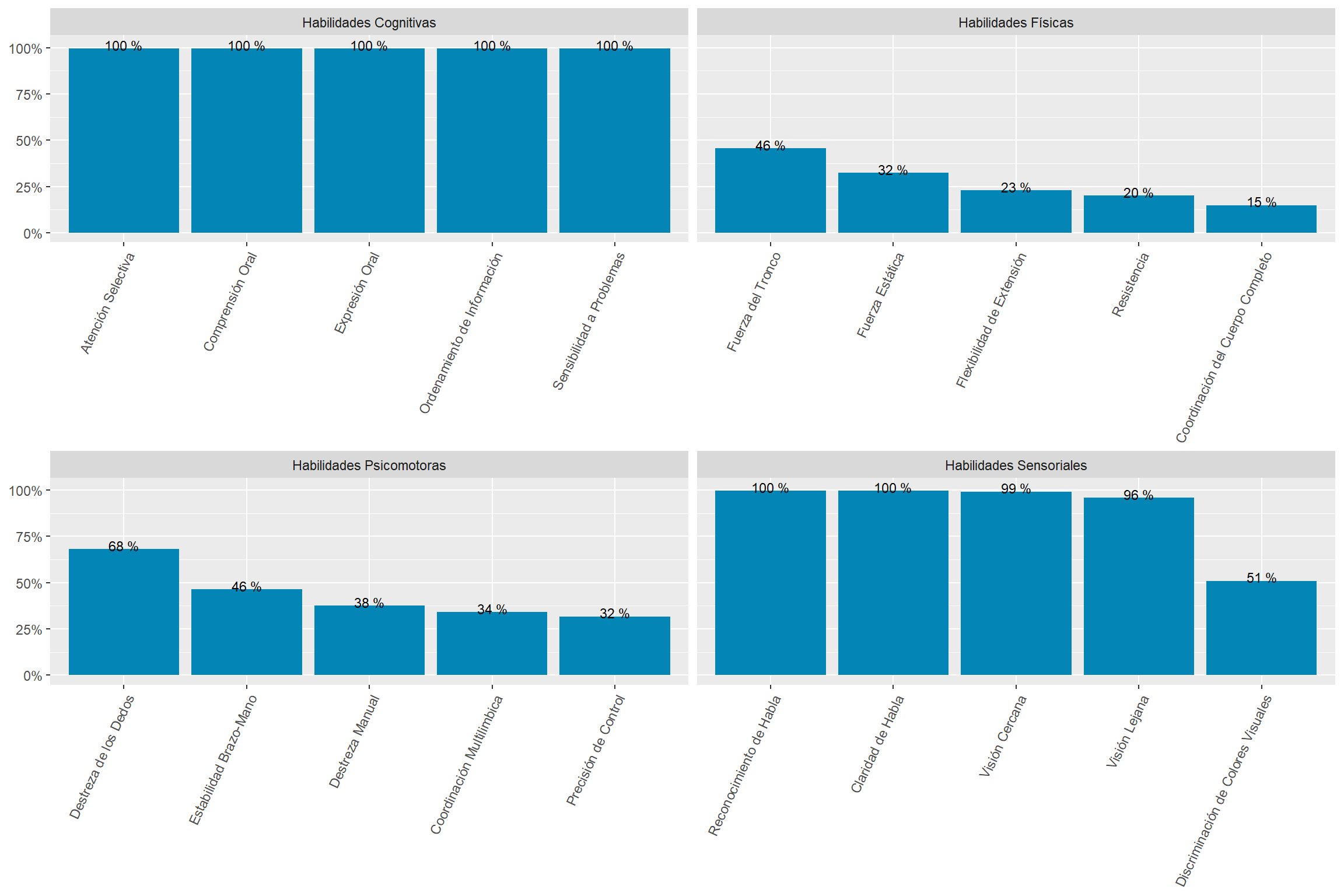
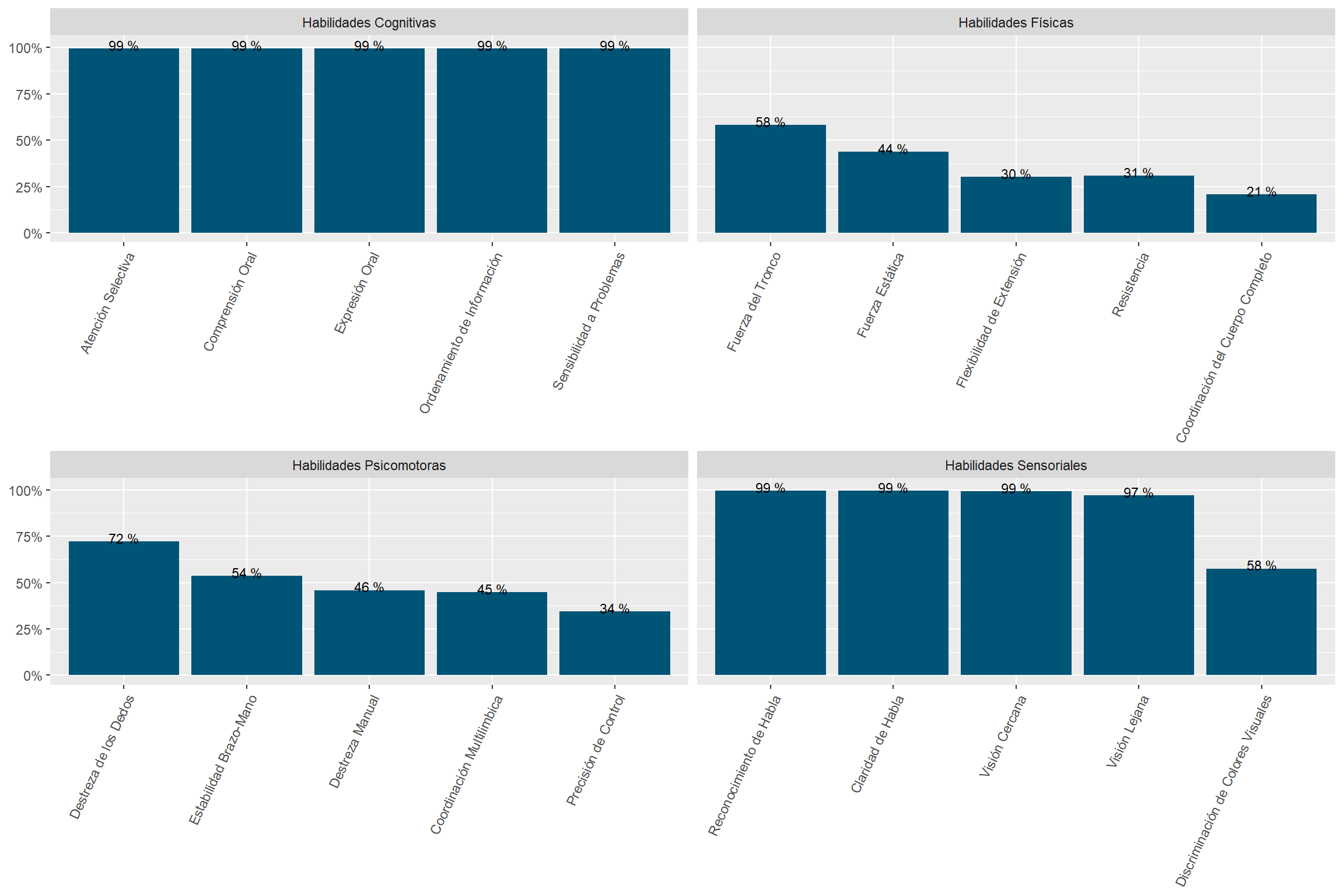
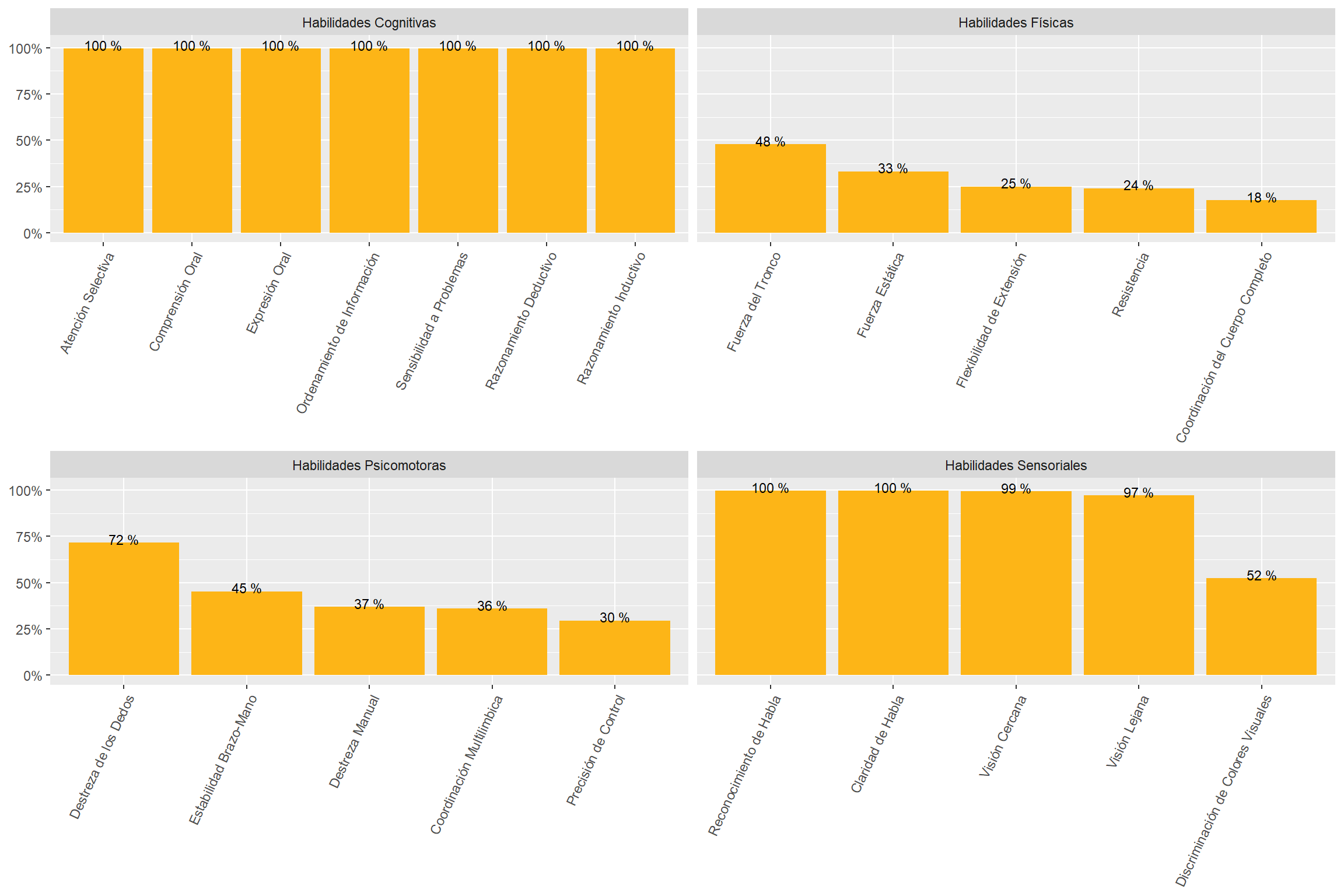
“Cognitive” and “Sensory” abilities are the most prevalent in online job postings. “Physical” and “Psychomotor” abilities are almost half as required. See Figure 11.
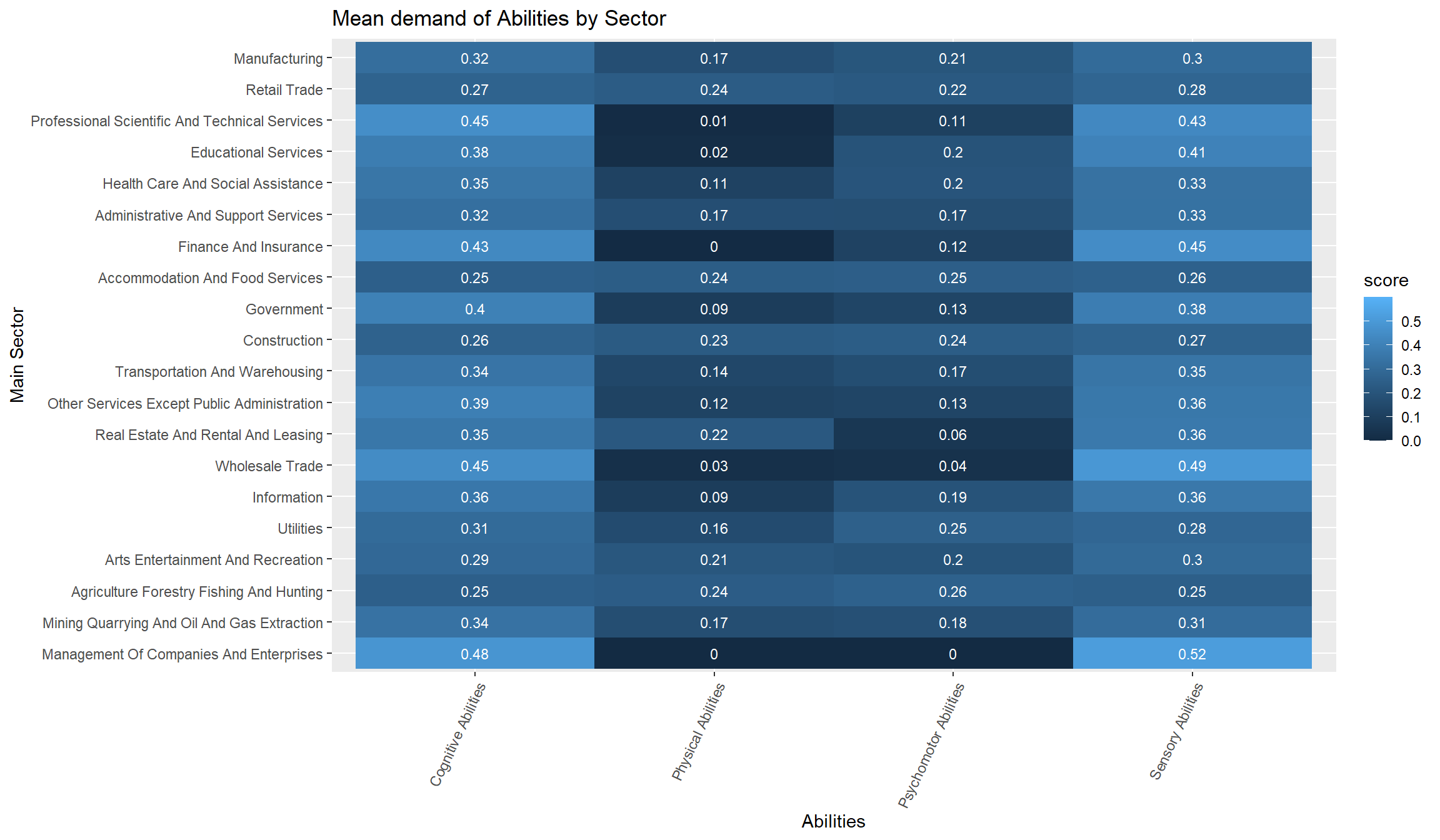
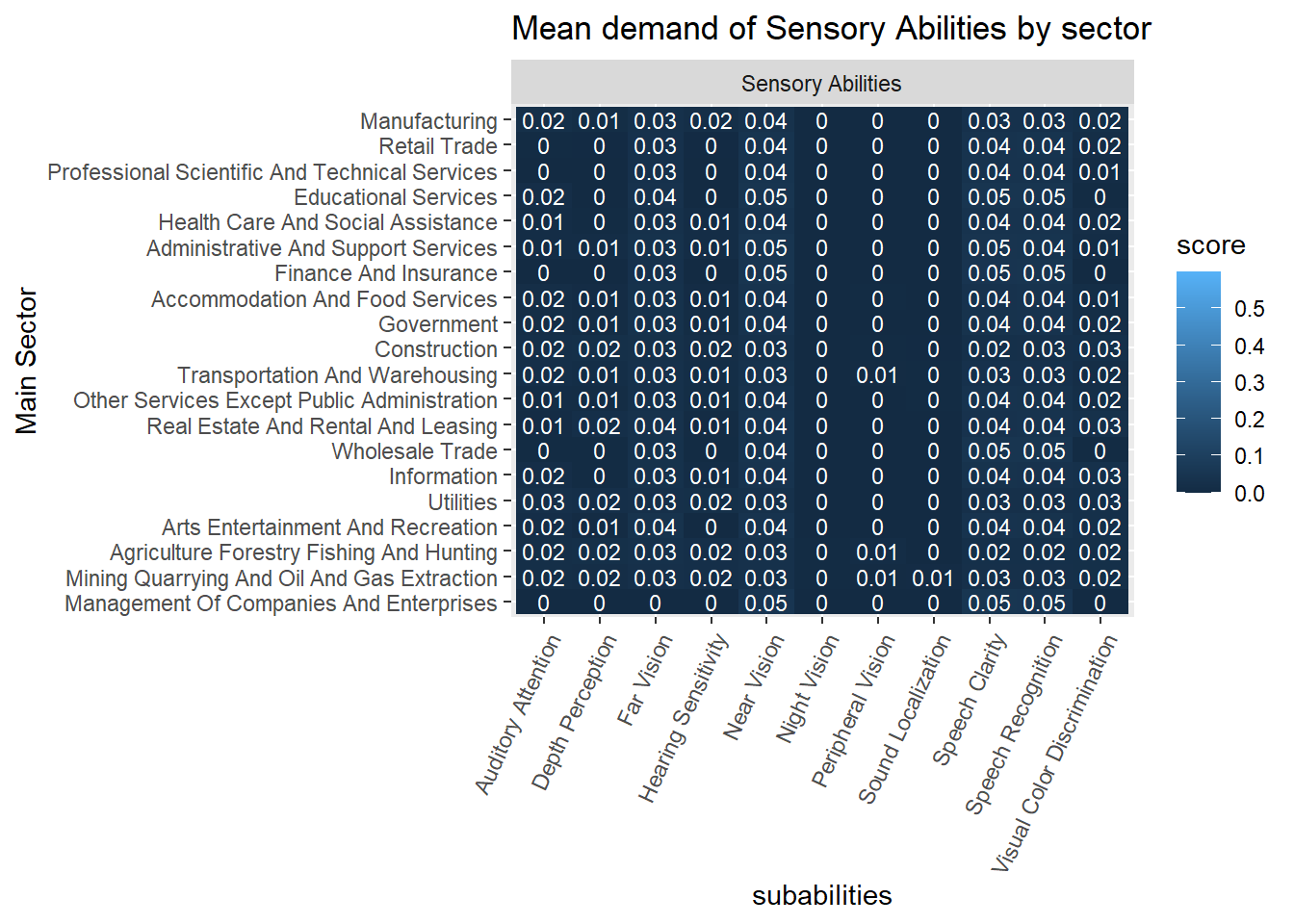
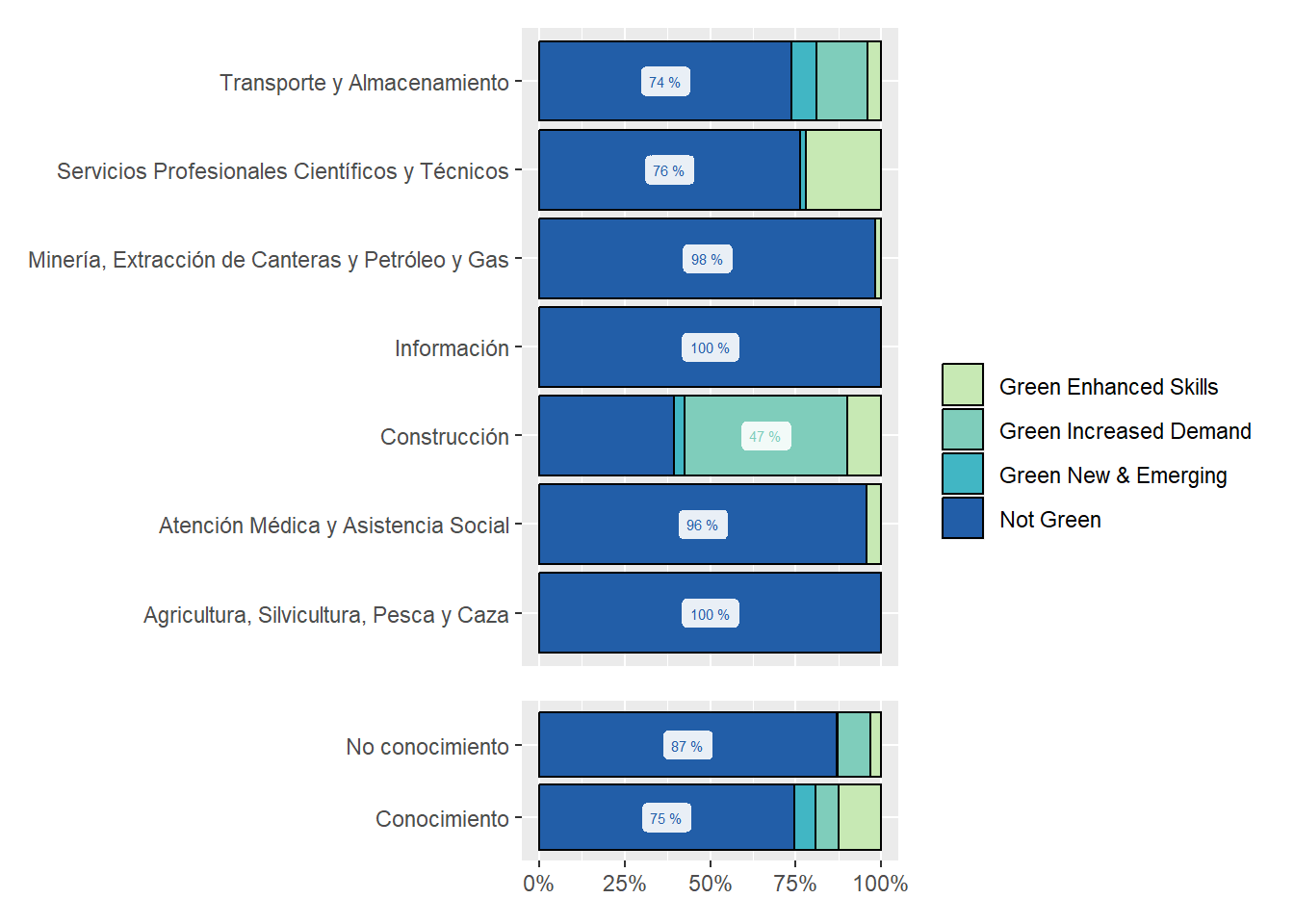
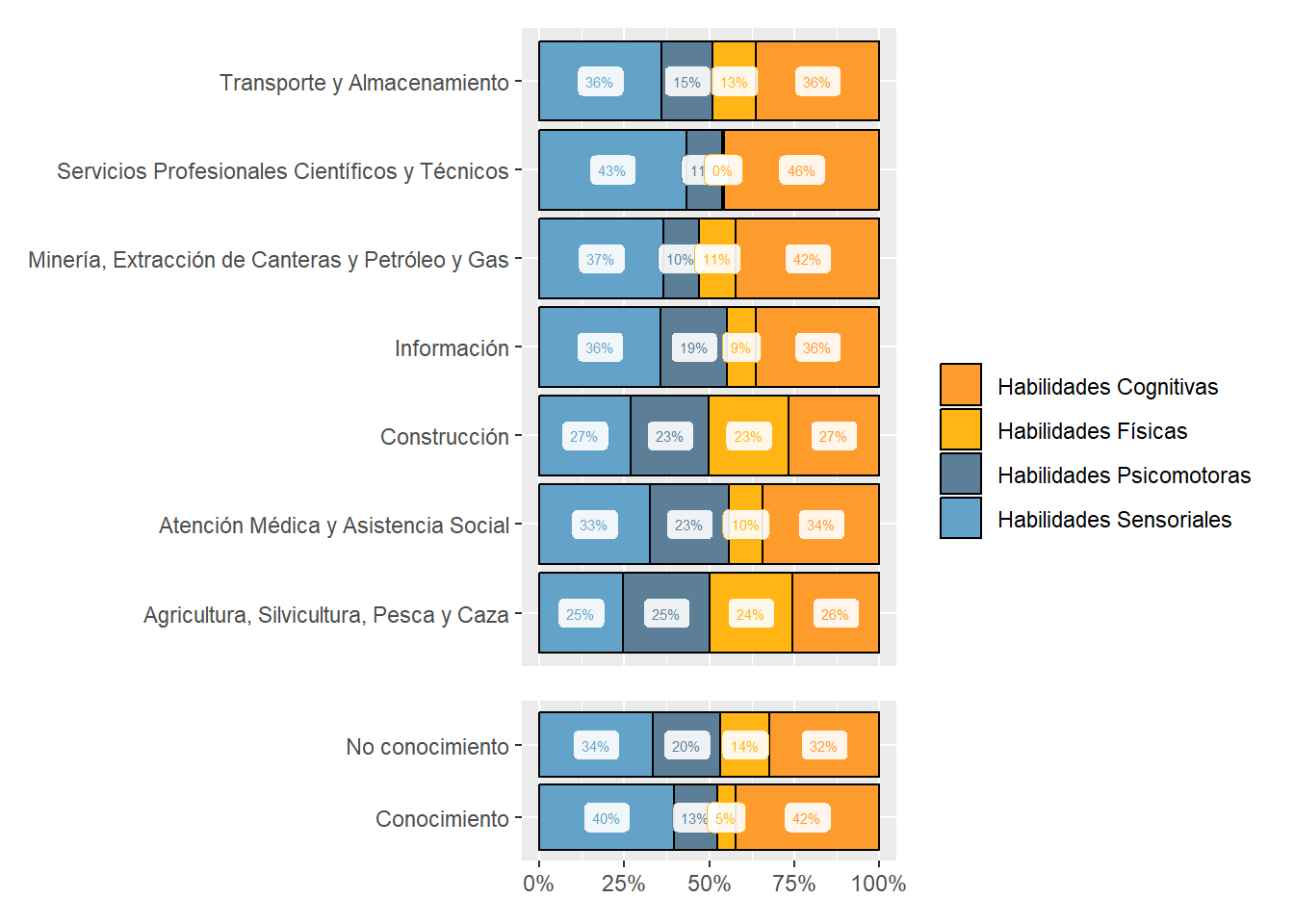
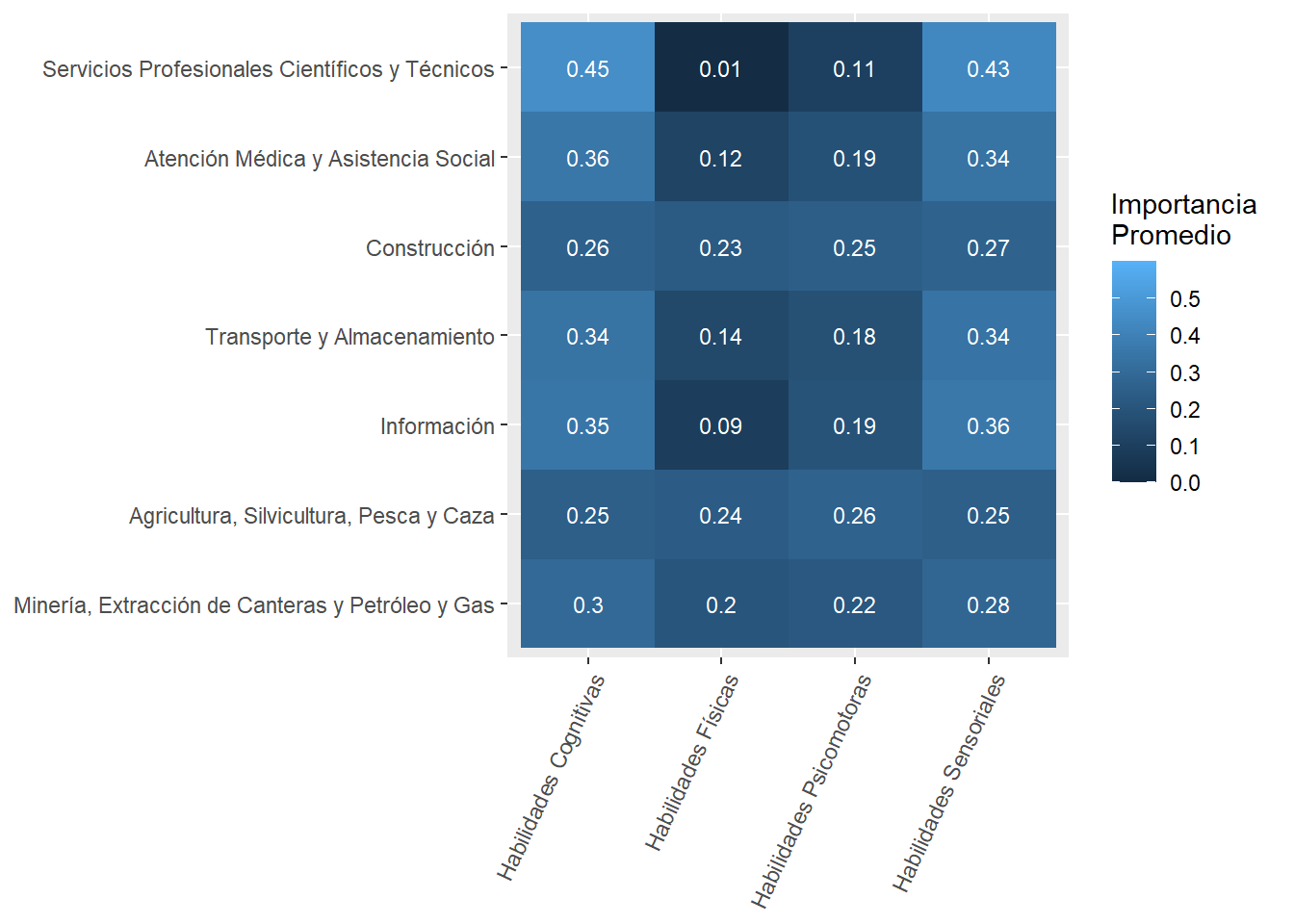
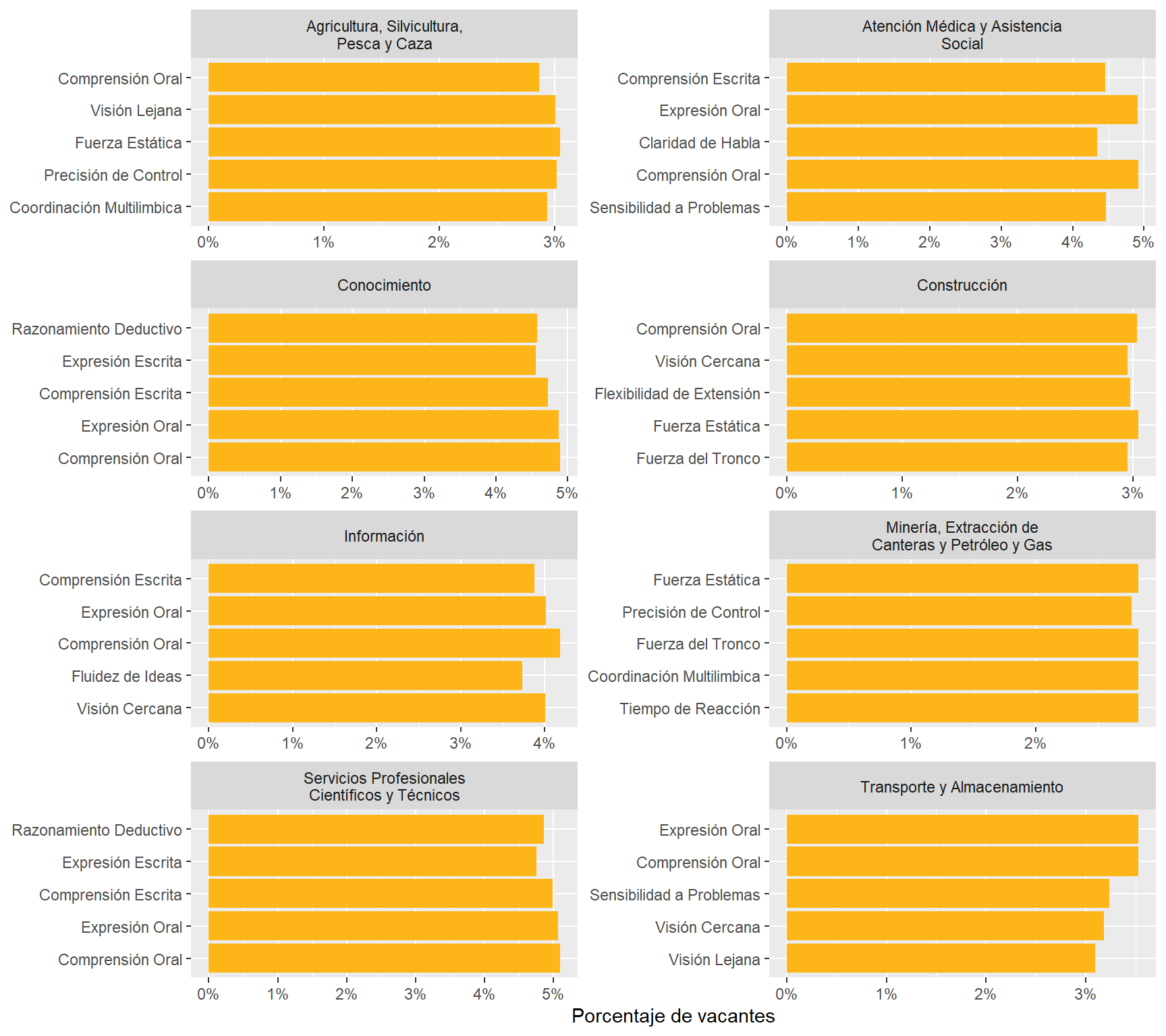
The most “Cognitive” abilities-intensive sectors are “Professional, Scientific and Technical Services,” “Utilities,” and “Management of Companies and Enterprises.” See Figure 18.
The most “Sensory” sectors are “Wholesale Trade,” “Management of Companies and Enterprises,” and “Educational Services.” These are sectors demanding many “Sensory” subabilities to a high degree. See Figure 18.
The “Construction” sector demands “Cognitive,” “Physical,” “Psychomotor,” and “Sensory” abilities similarly. The demand for abilities in the “Accommodation and Food Services” sector is similarly even. See Figure 18.
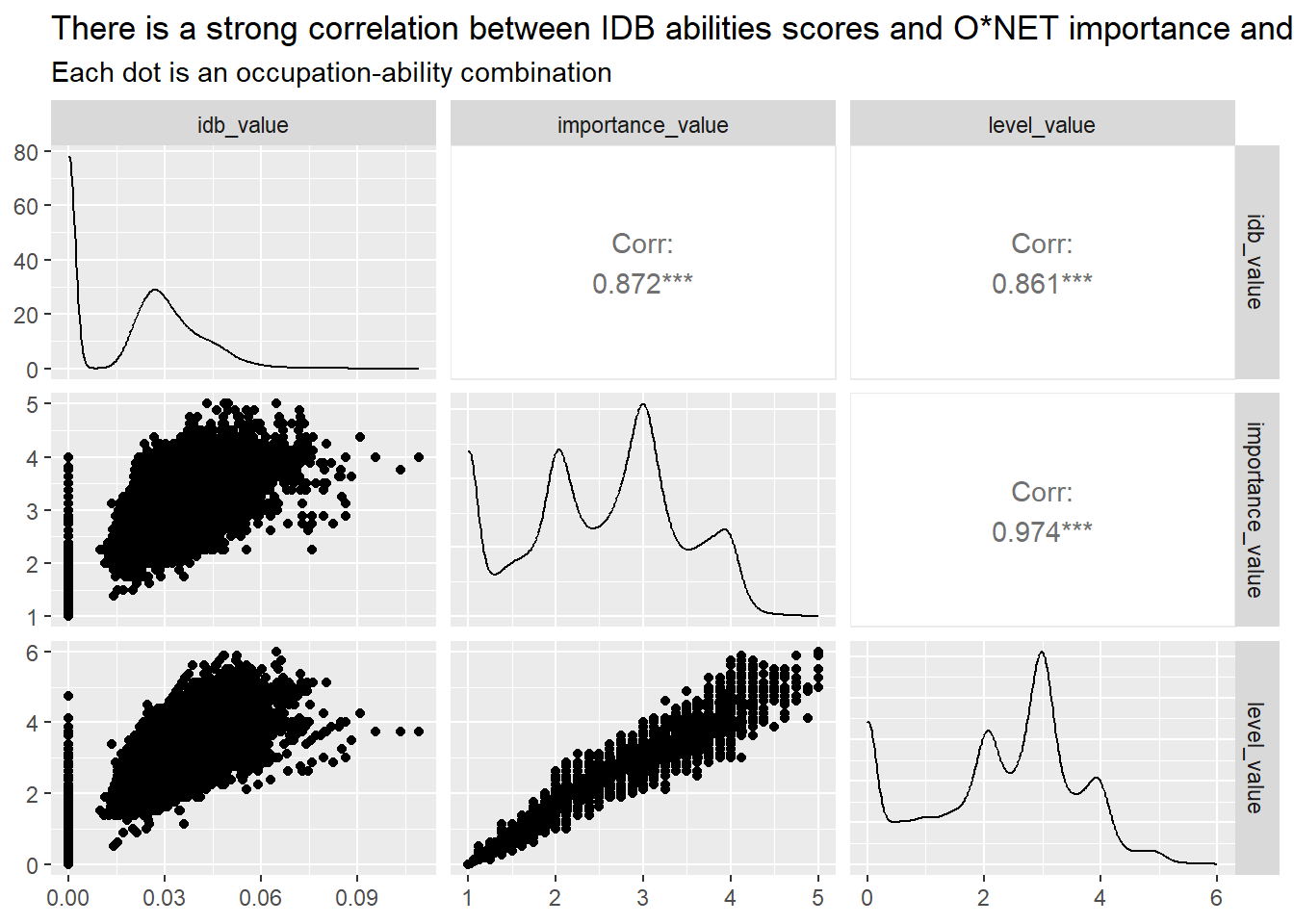
Sub-abilities’ intensity in Google Jobs data aligns well with O*NET data on Sub-abilities’ importance by occupation. Figure 70. There are methods to identify occupations exposed to AI by looking at subabilities (See Felten et. Al. 2018).
Work from Home arrangements (WFH):
The fraction of remote/hybrid vacancies detected is too low. Chile’s share of remote vacancies is 1.3%, while New Zealand’s is 10% (see Table 6 and ?@fig-bloom3). However, global surveys say Chileans work from home 0.9 days a week, while New Zealanders do so 1.0 days per week (see ?@fig-bloom3).
In the Argentinean files reviewed, 85% of vacancies with the word “hybrid” on the description were classified as not remote/hybrid (see Table 9). This evidence suggests a high prevalence of Type II errors. This likely happens in Chile and Uruguay files.
Type II errors aside, Santiago and Buenos Aires account for 24% and 20% of all remote vacancies, respectively. Regions like Córdoba, Mendoza, Corrientes, and Metropolitana account for 4%, 4%, 2%, and 4% of remote job postings, respectively. These last regions and Buenos Aires account for a more significant share of remote vacancies than expected by chance (See Table 7).
Energy transition:
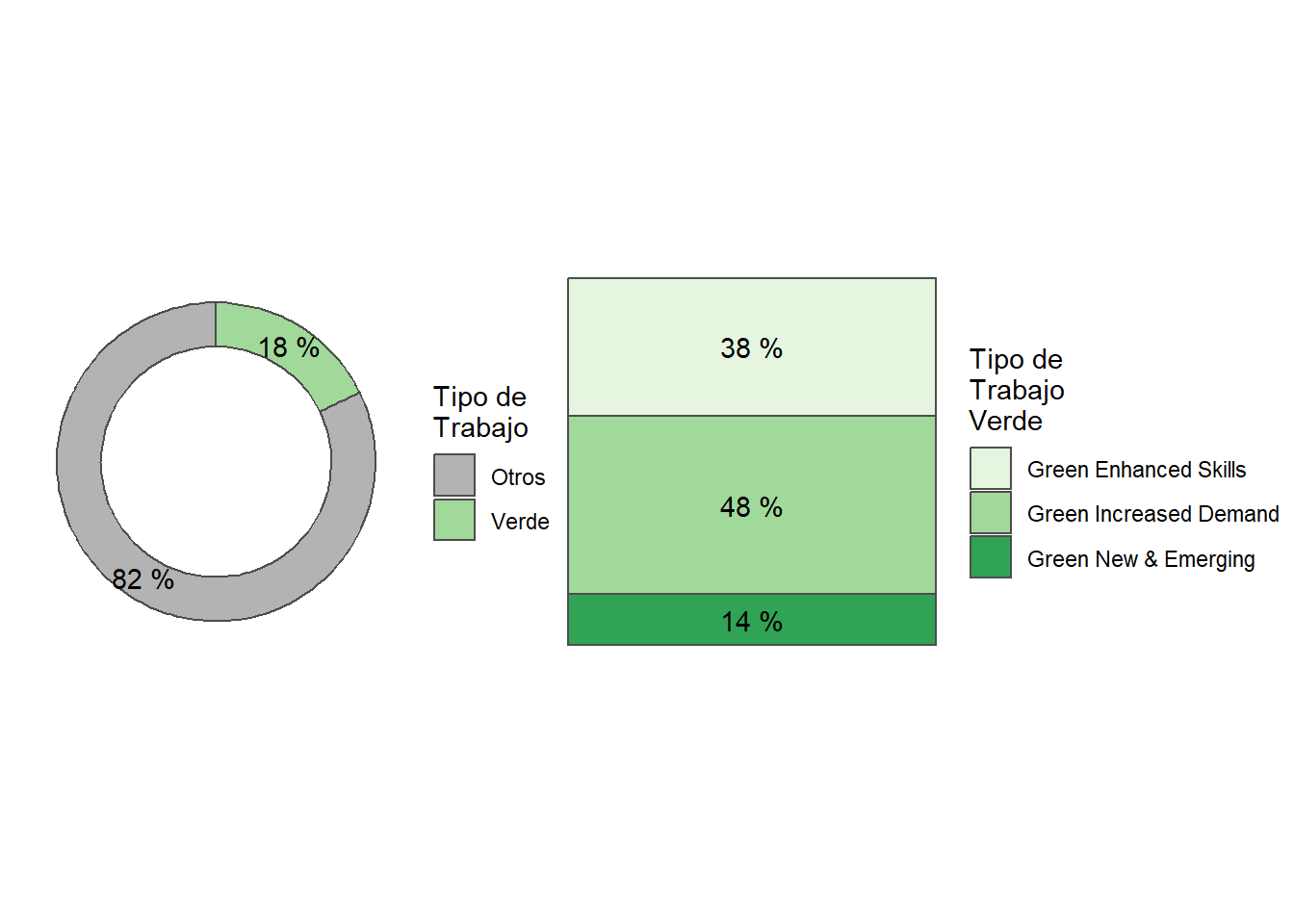
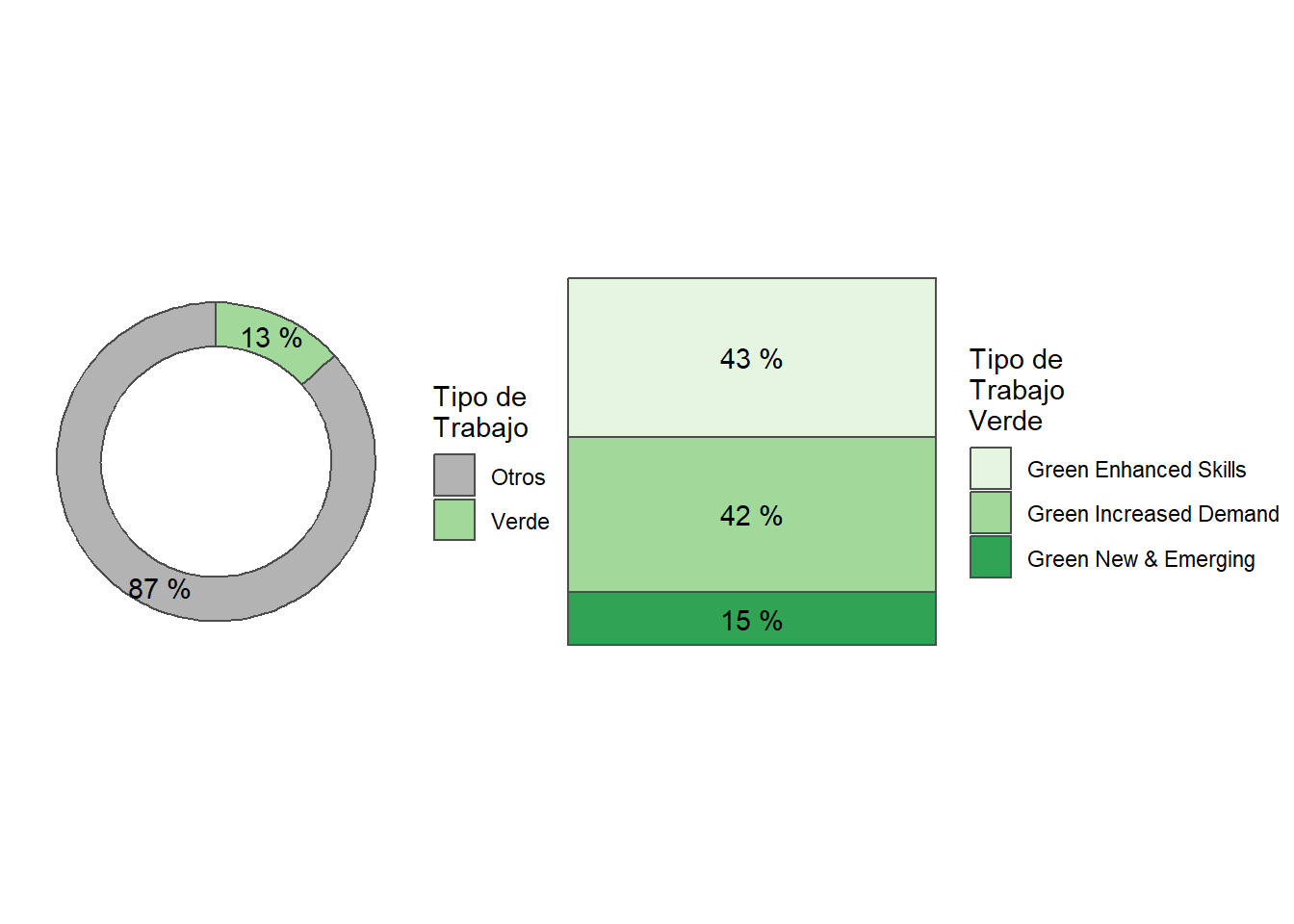
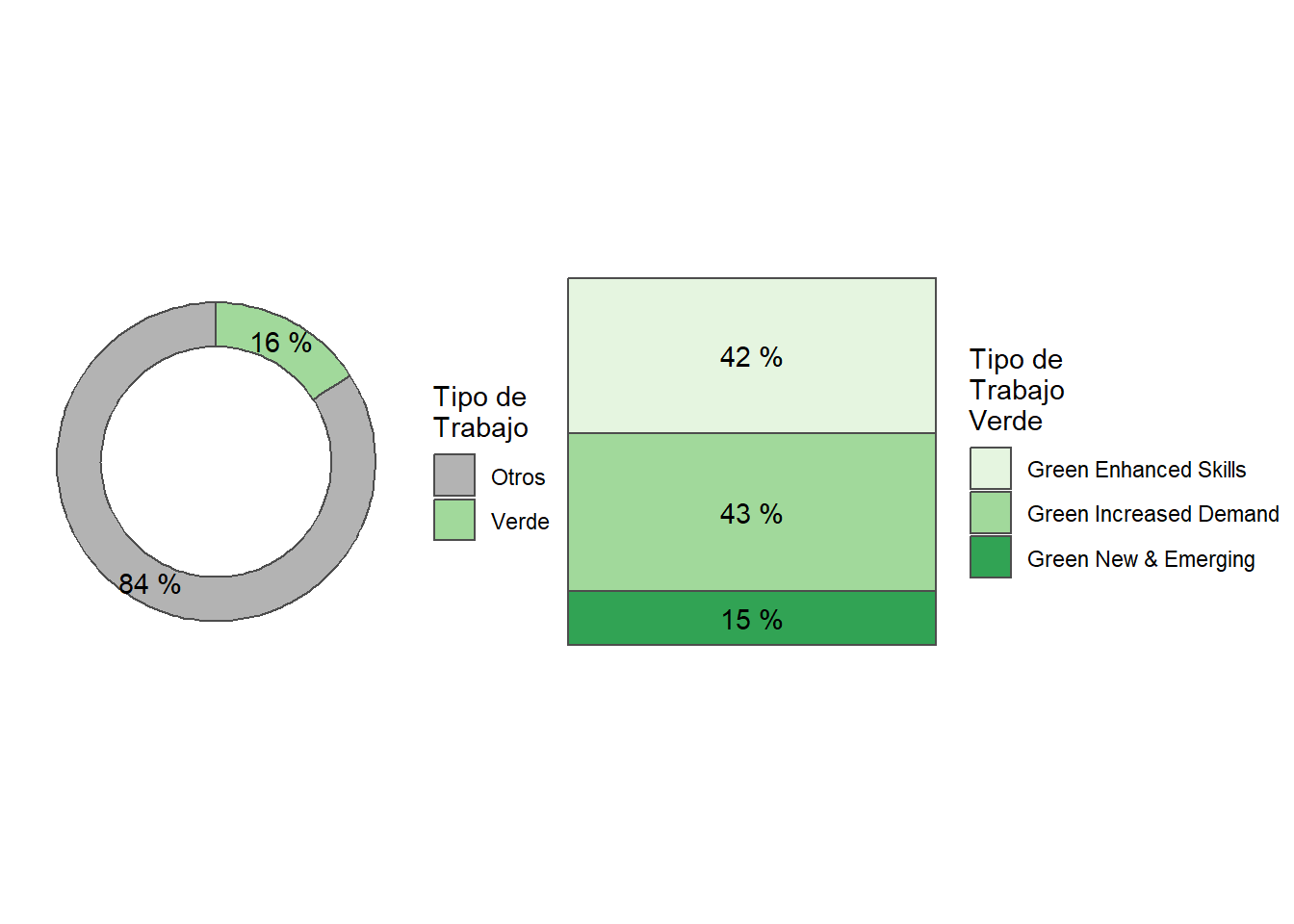
Green jobs represent 15% of all online job postings. Argentina has the highest share of green jobs in its’ job postings (17%), while Chile has the lowest (13%). See Table 3.
“Green Increased Demand” accounts for 45% of Green jobs, while “Green Enhanced Skills” and “Green New & Emerging” account for 40% and 14%, respectively. See Table 4.
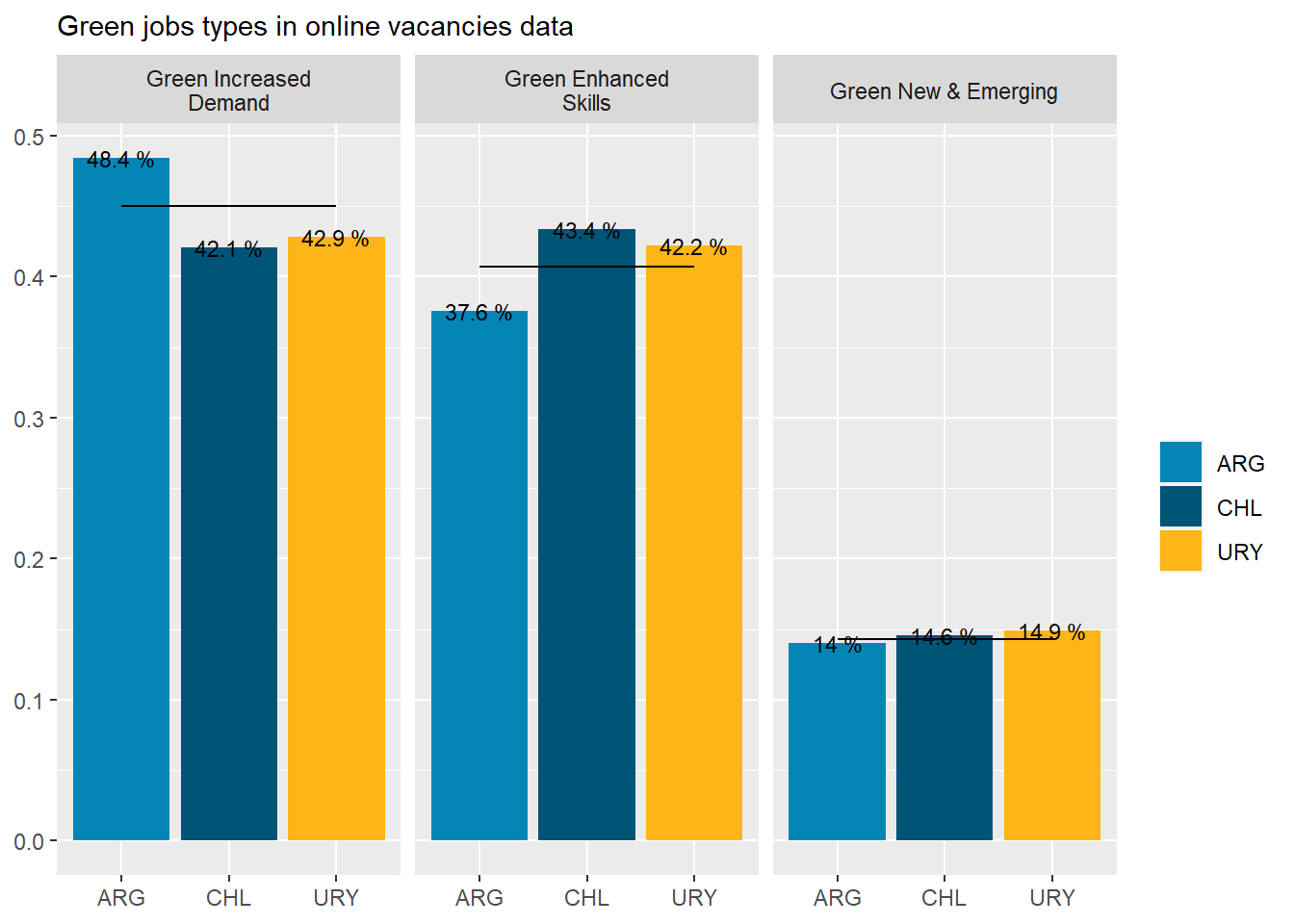
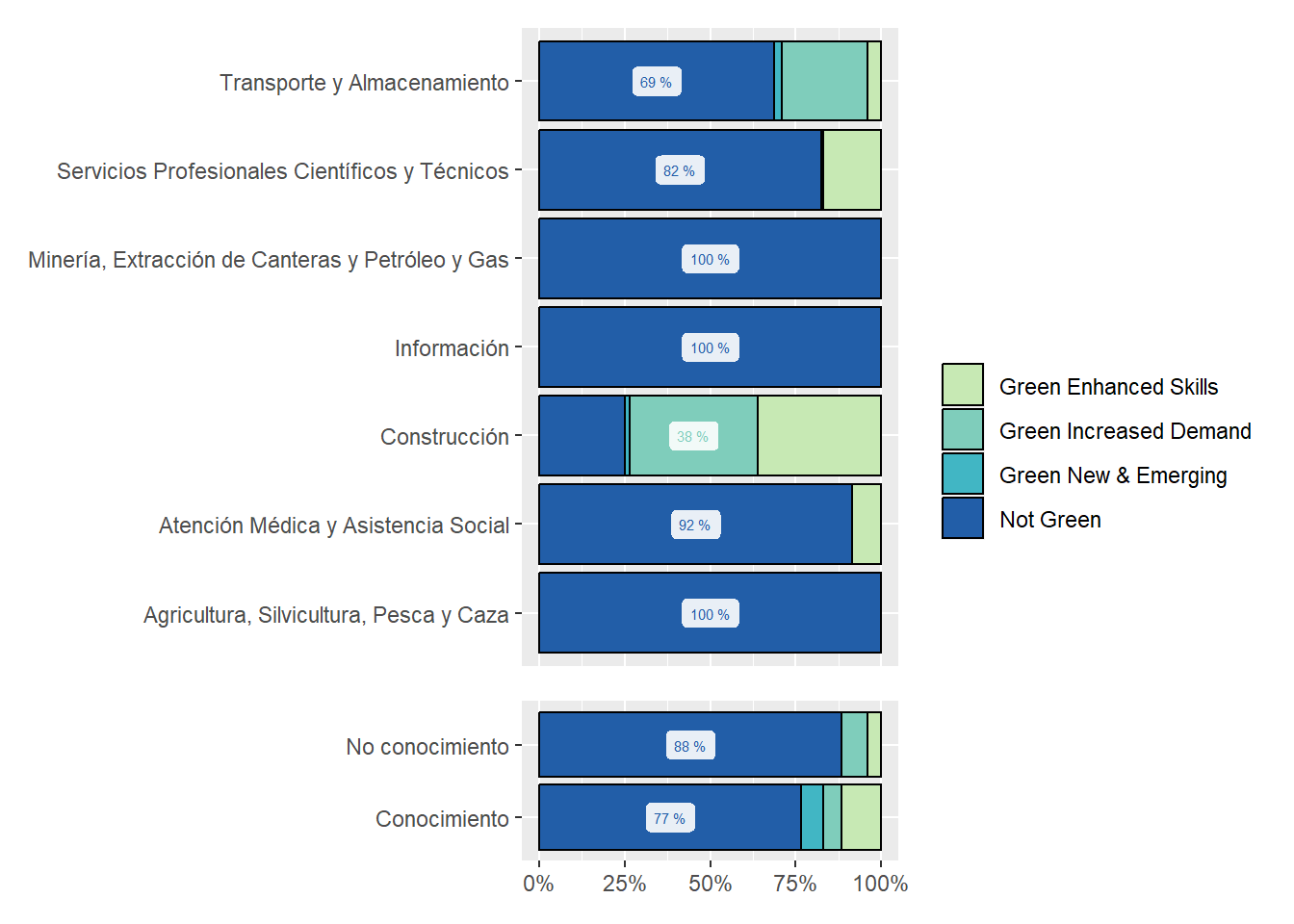
Argentina is intensive in “Green Increased Demand” (48%), while Chile is relatively intensive in “Green Enhanced Skills” (43.4%). See Table 4
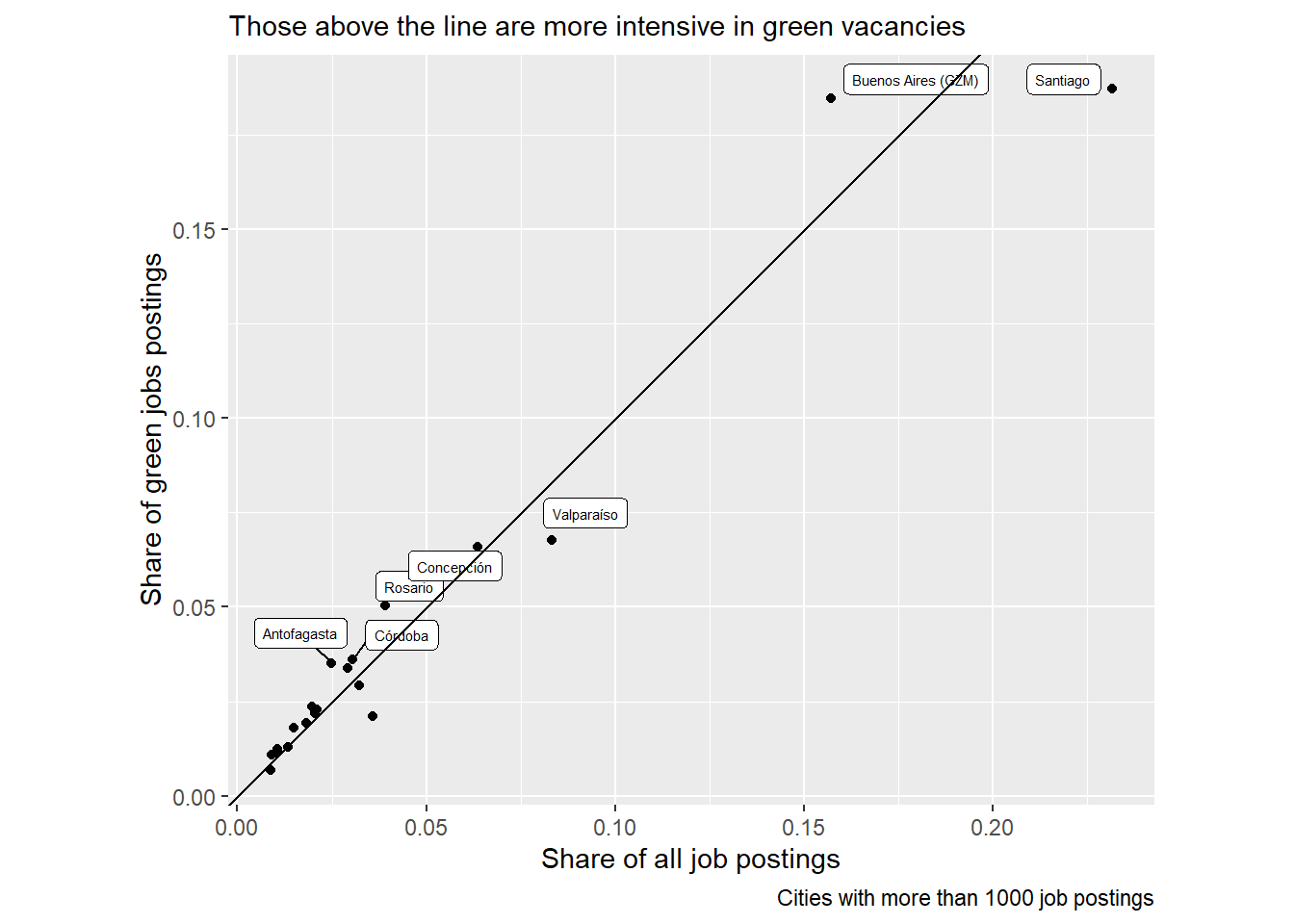
Santiago and Buenos Aires account for 18% and 18% of all green online vacancies, while regions like Rosario, Mendoza, and Antofagasta account for 6%, 4%, and 4%, respectively. Buenos Aires, Rosario, Mendoza, and Antofagasta account for a more significant share of Green vacancies than expected by chance. See Table 5.
Job Zones:
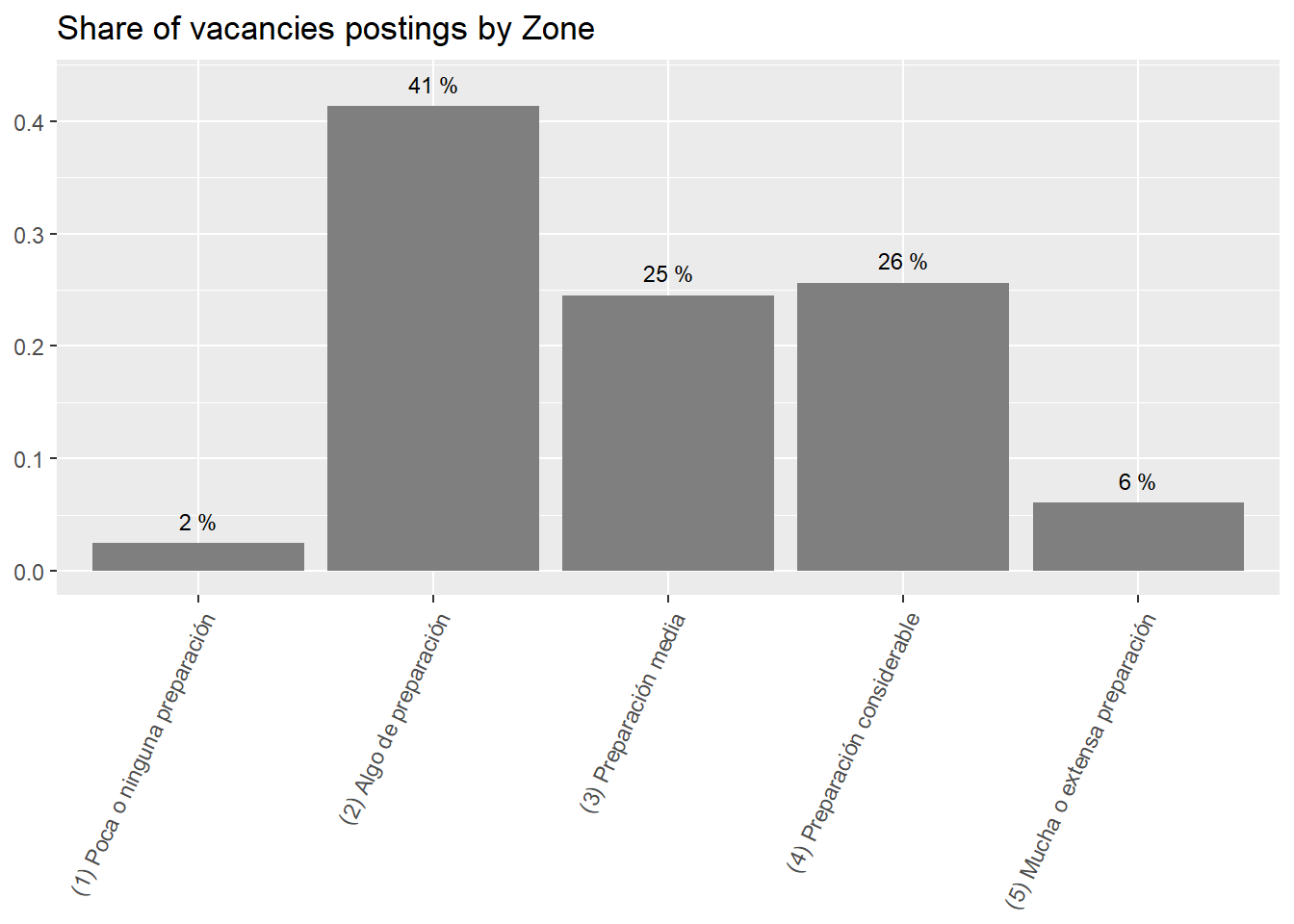
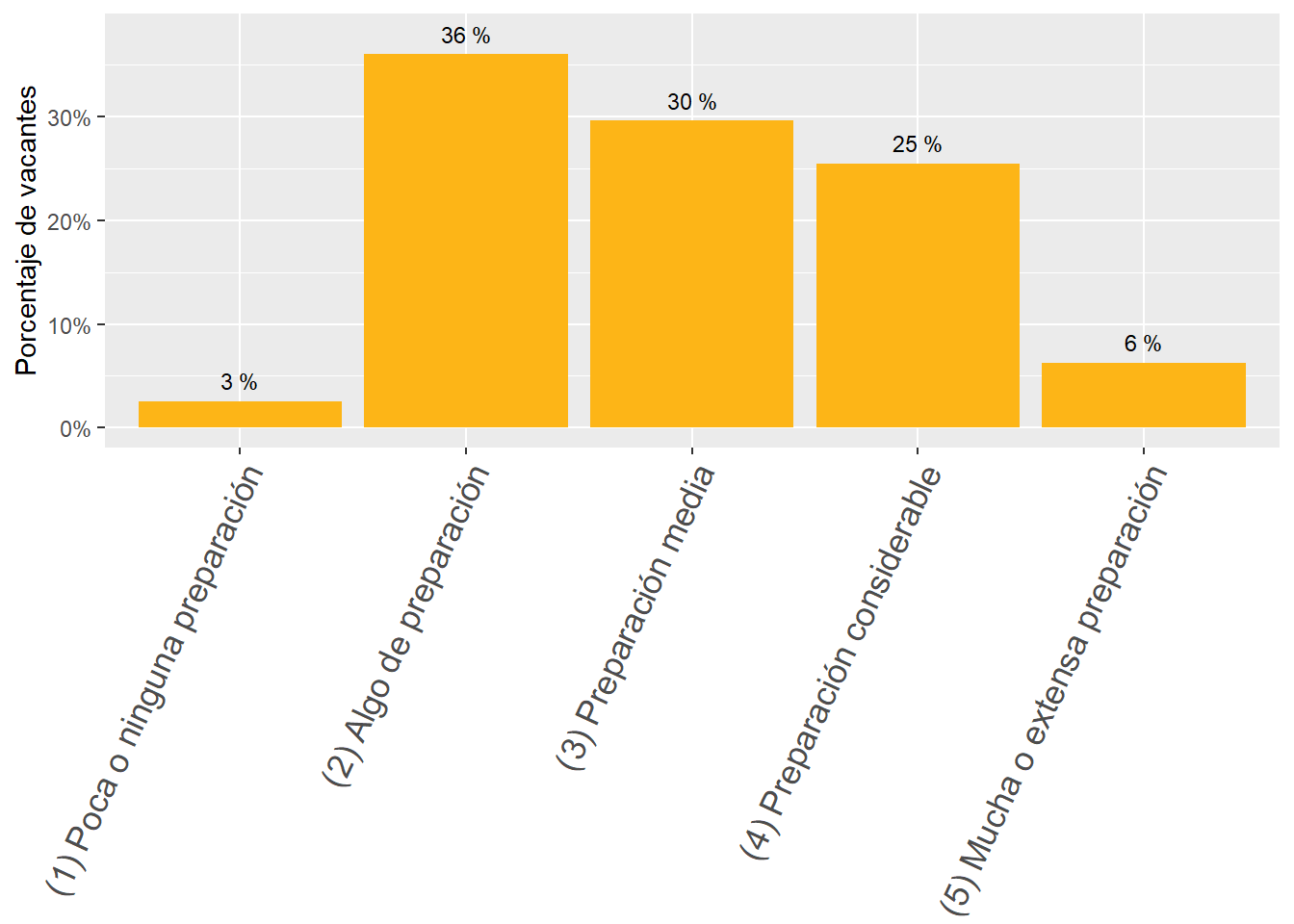
41% of job vacancies in the South Cone require “(2) Some preparation”, while 25% require “(4) Considerable preparation”, and another 25% require “(3) Middle preparation”. Only 8% of the demand falls on the “(1) no preparation” and “(5) a lot of preparation” extremes. See Figure 19.
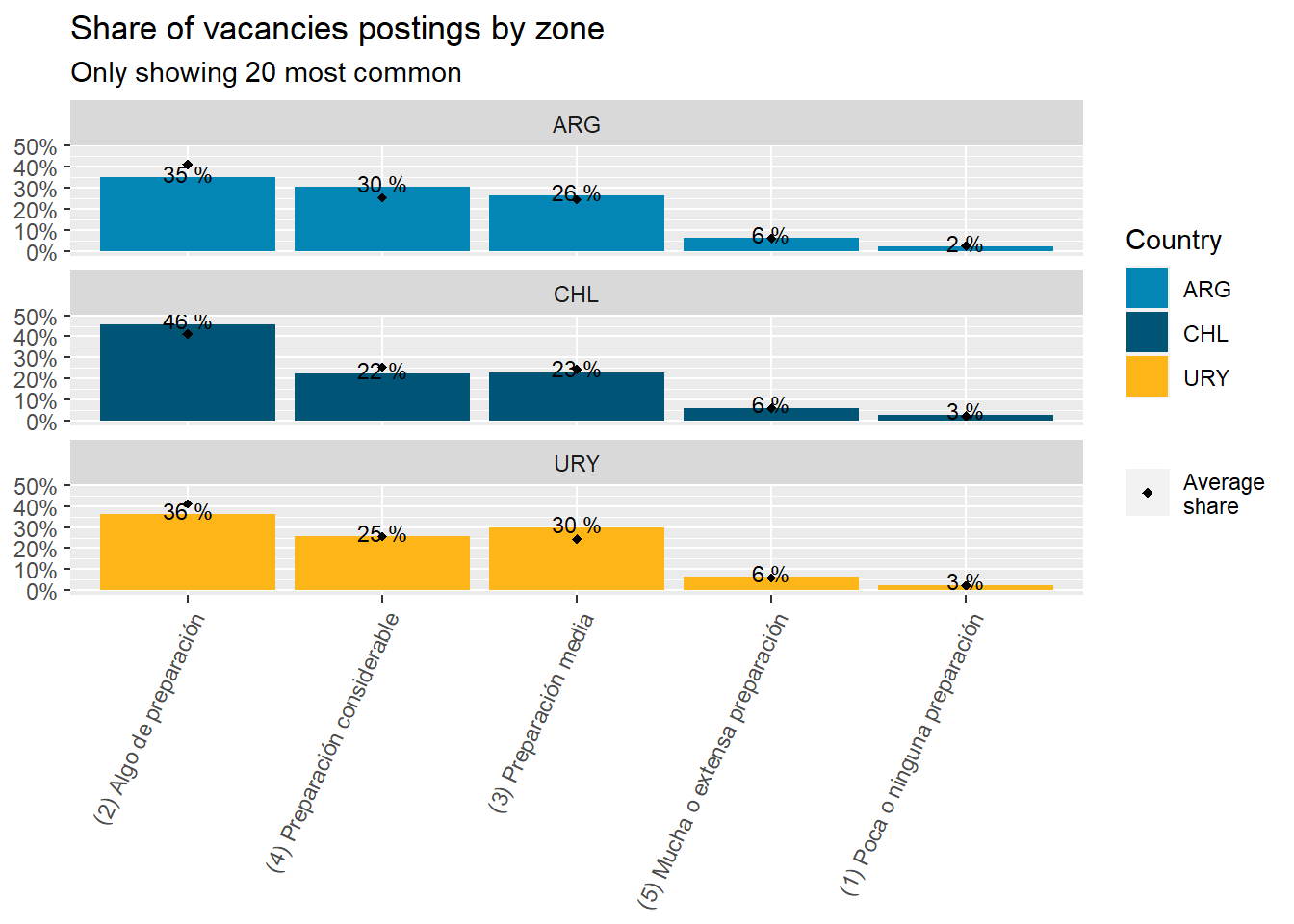
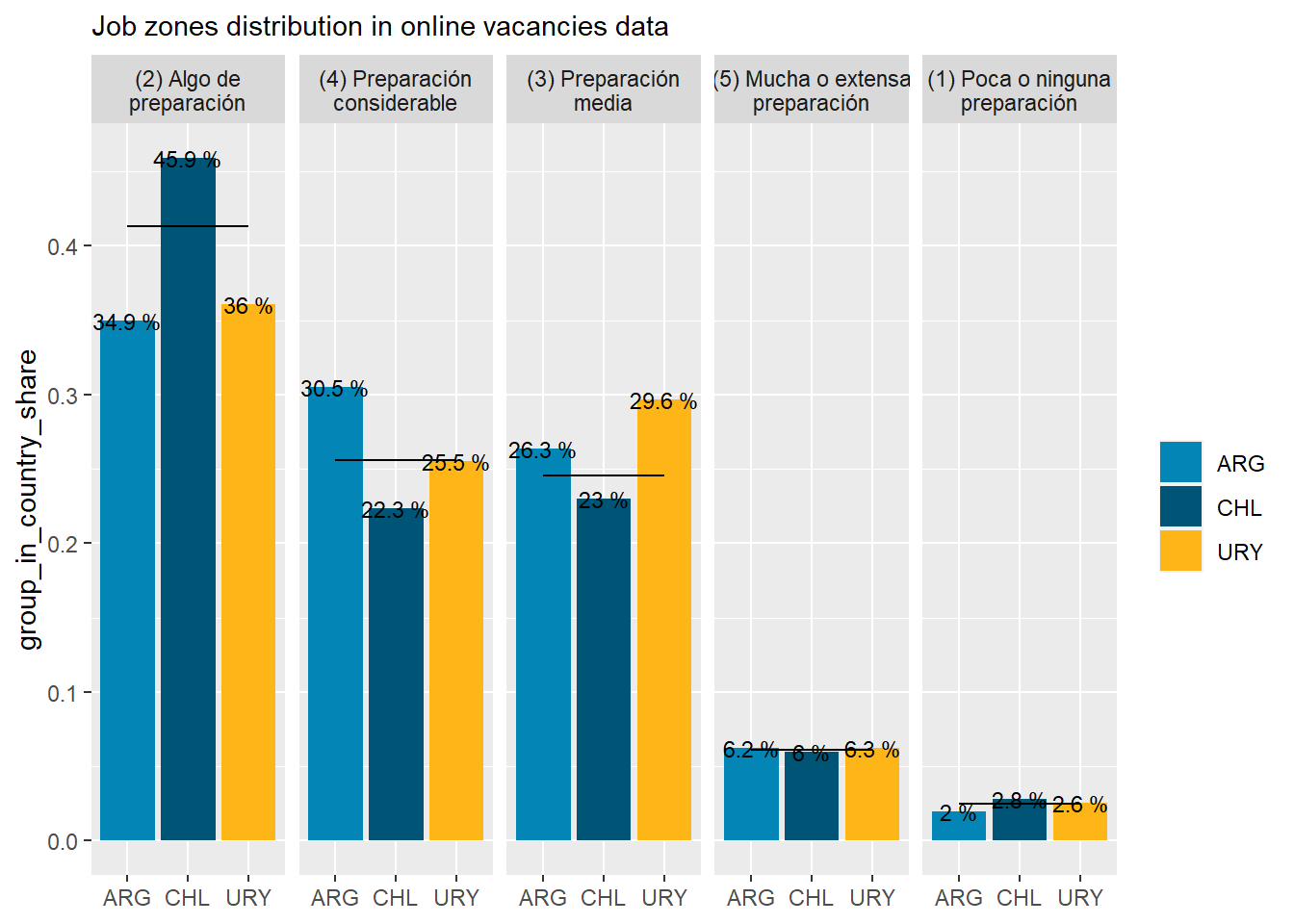
46% of job postings in Chile demand “(2) Some preparation”. It’s the country most concentrated in that area of demand by a considerable margin. See Figure 23.
30.5% of job postings in Argentina demand “(4) Some preparation”. It’s the country most concentrated in that area of demand by a moderate margin. See Figure 23.
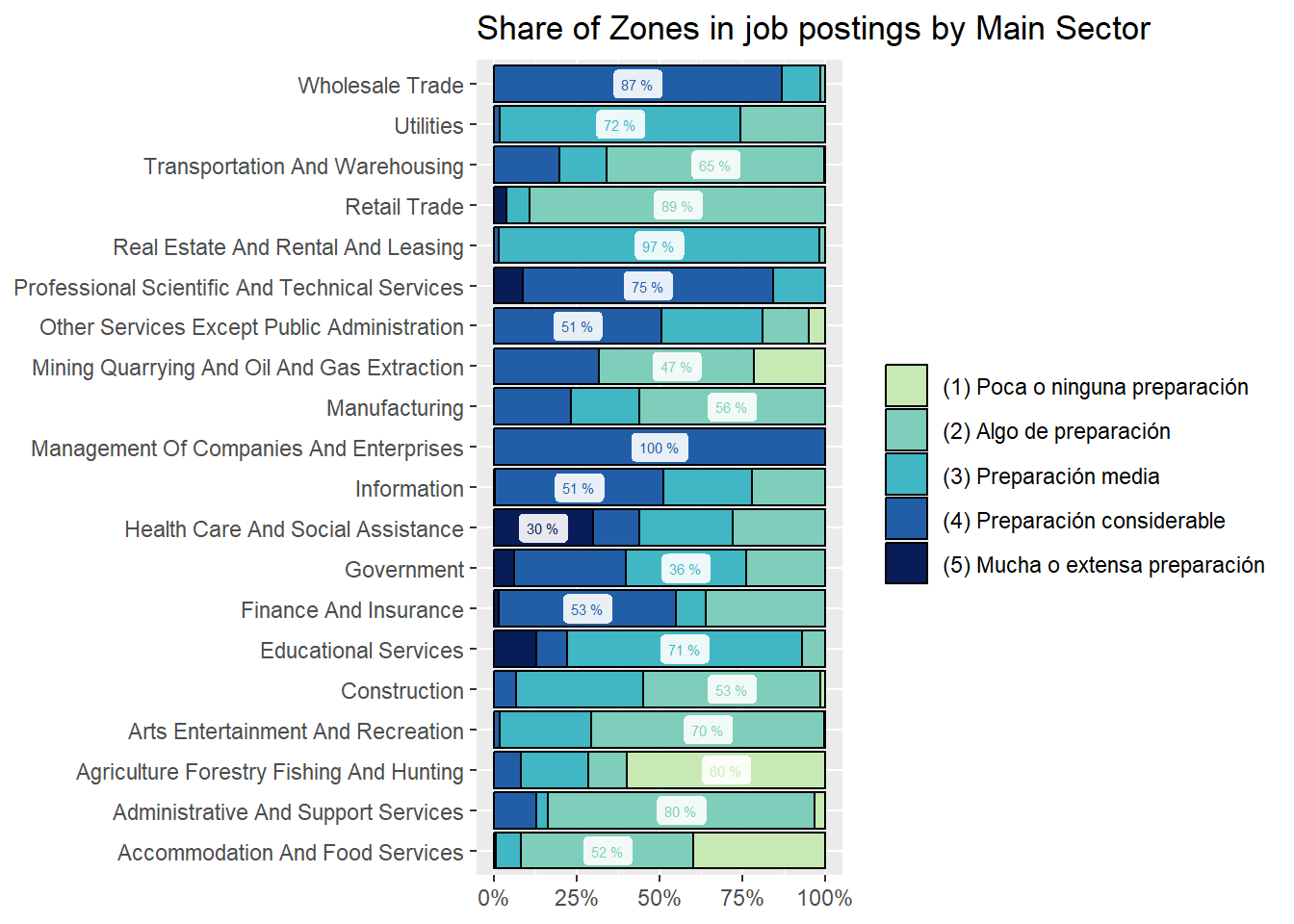
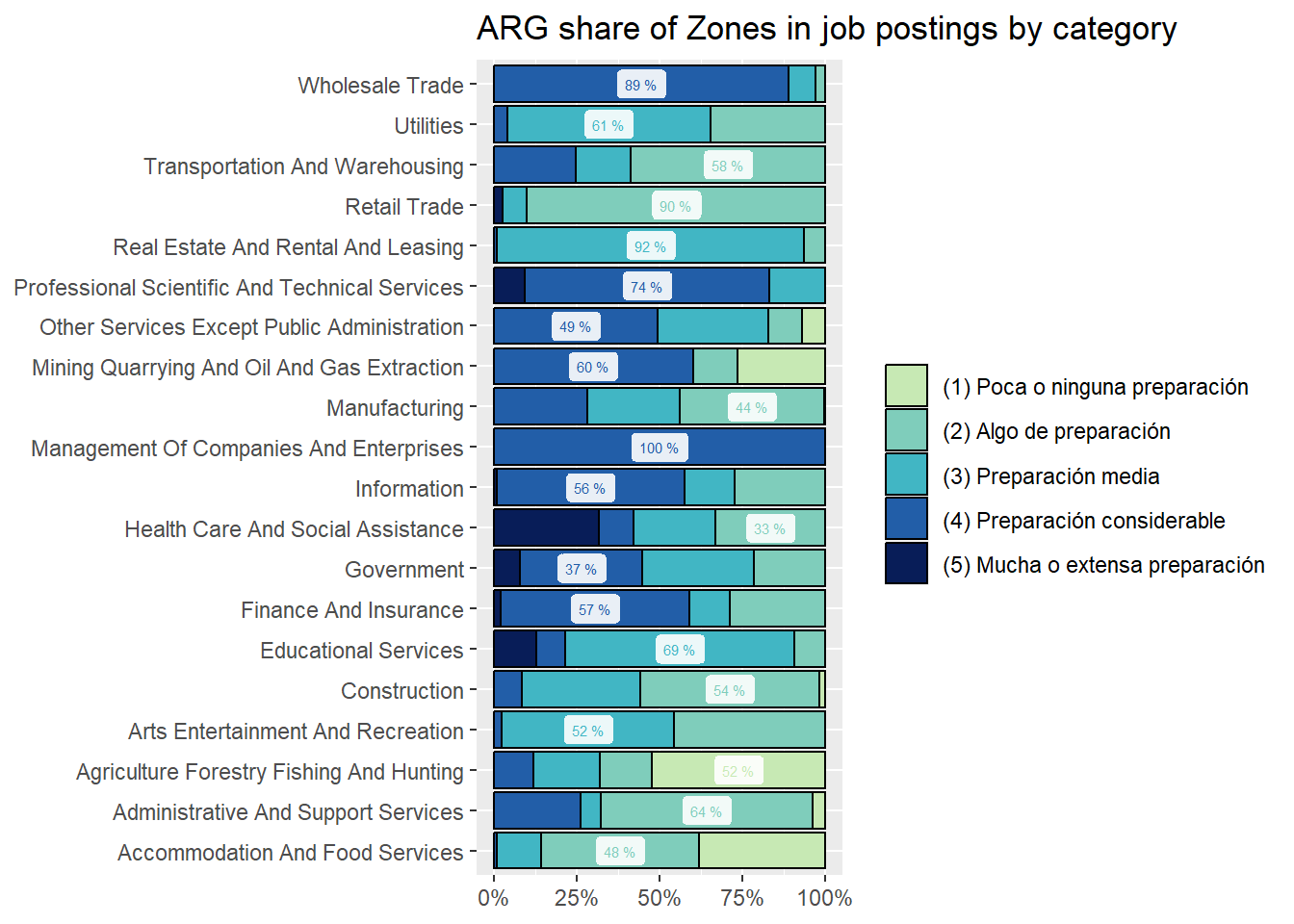
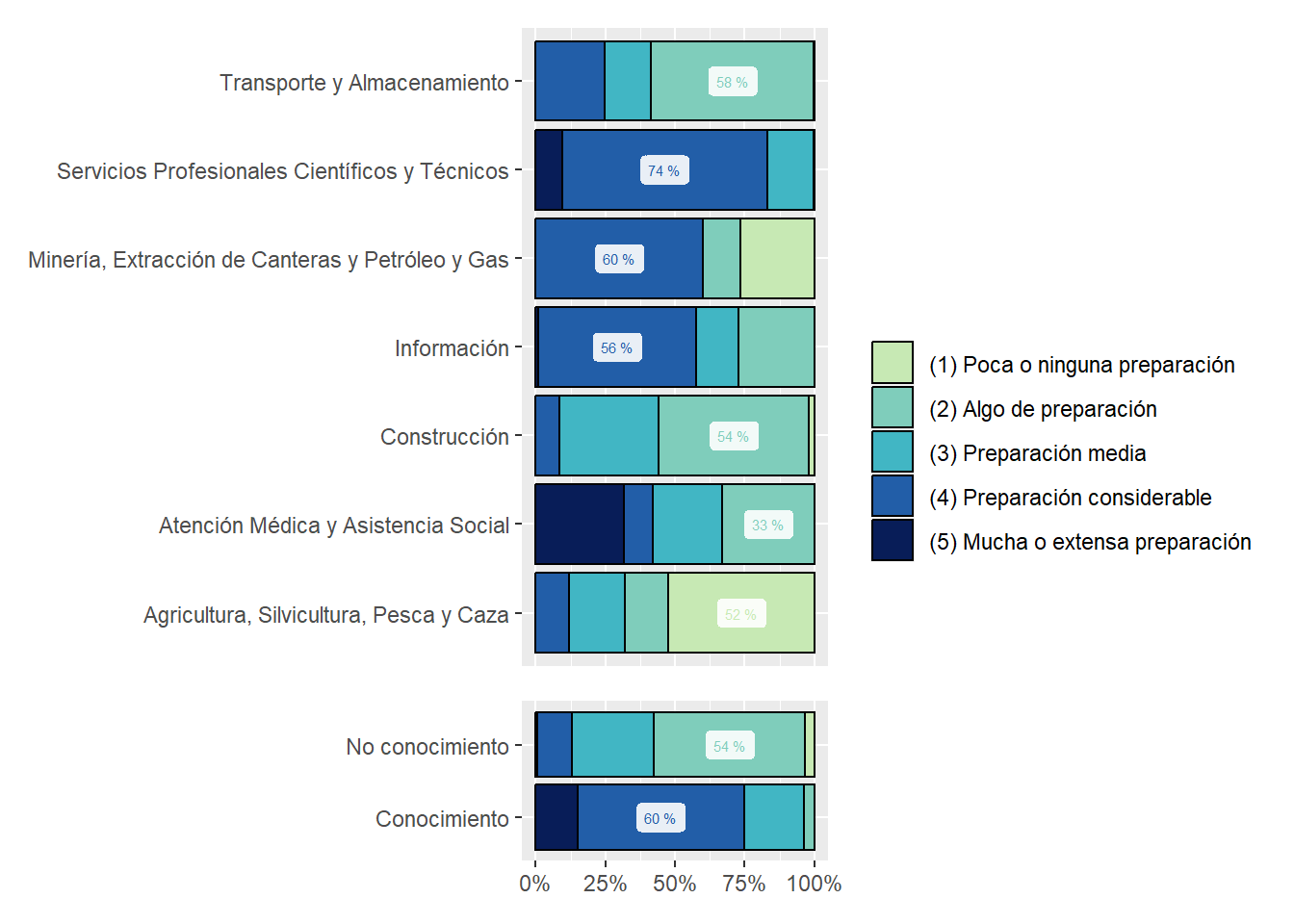
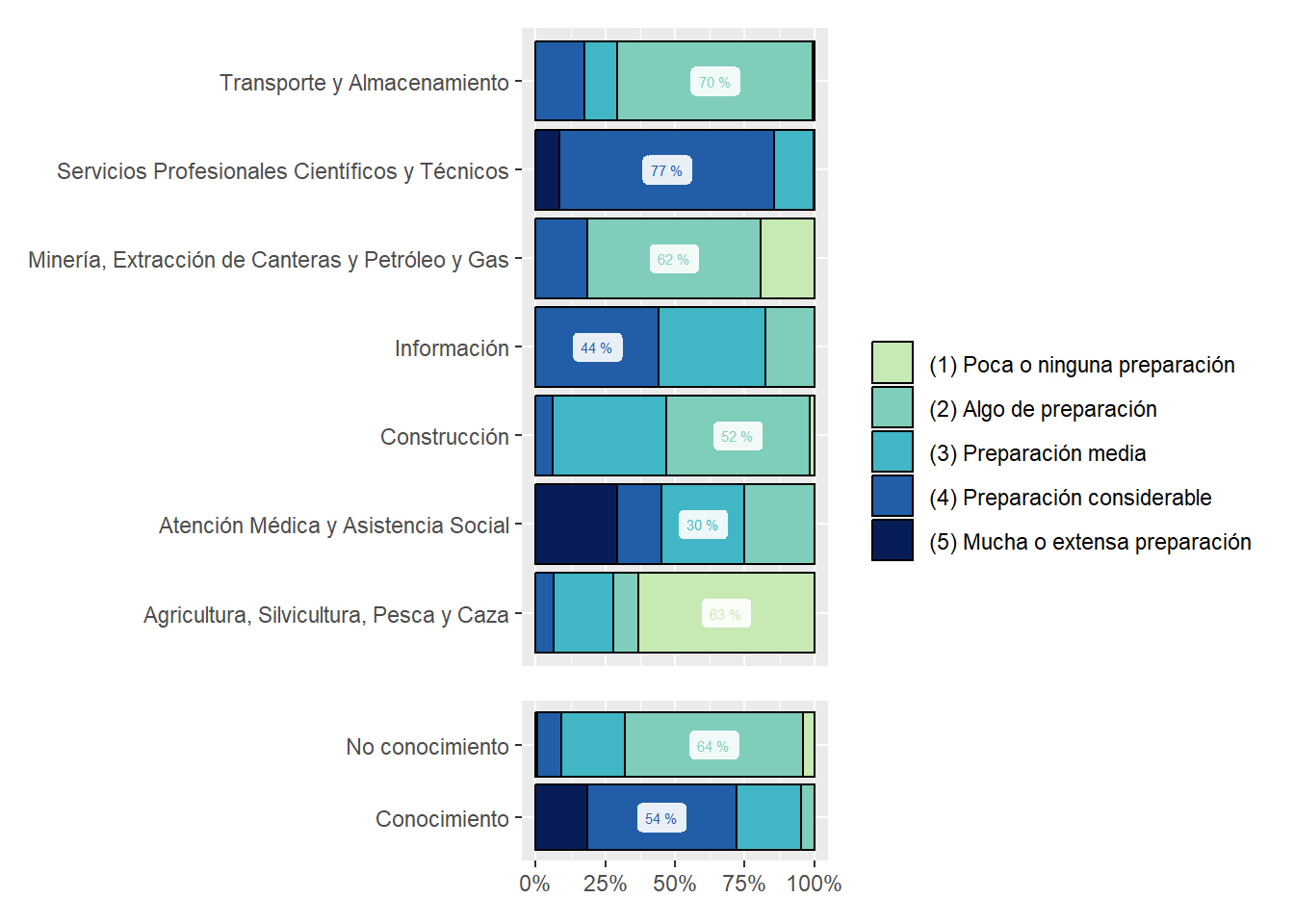
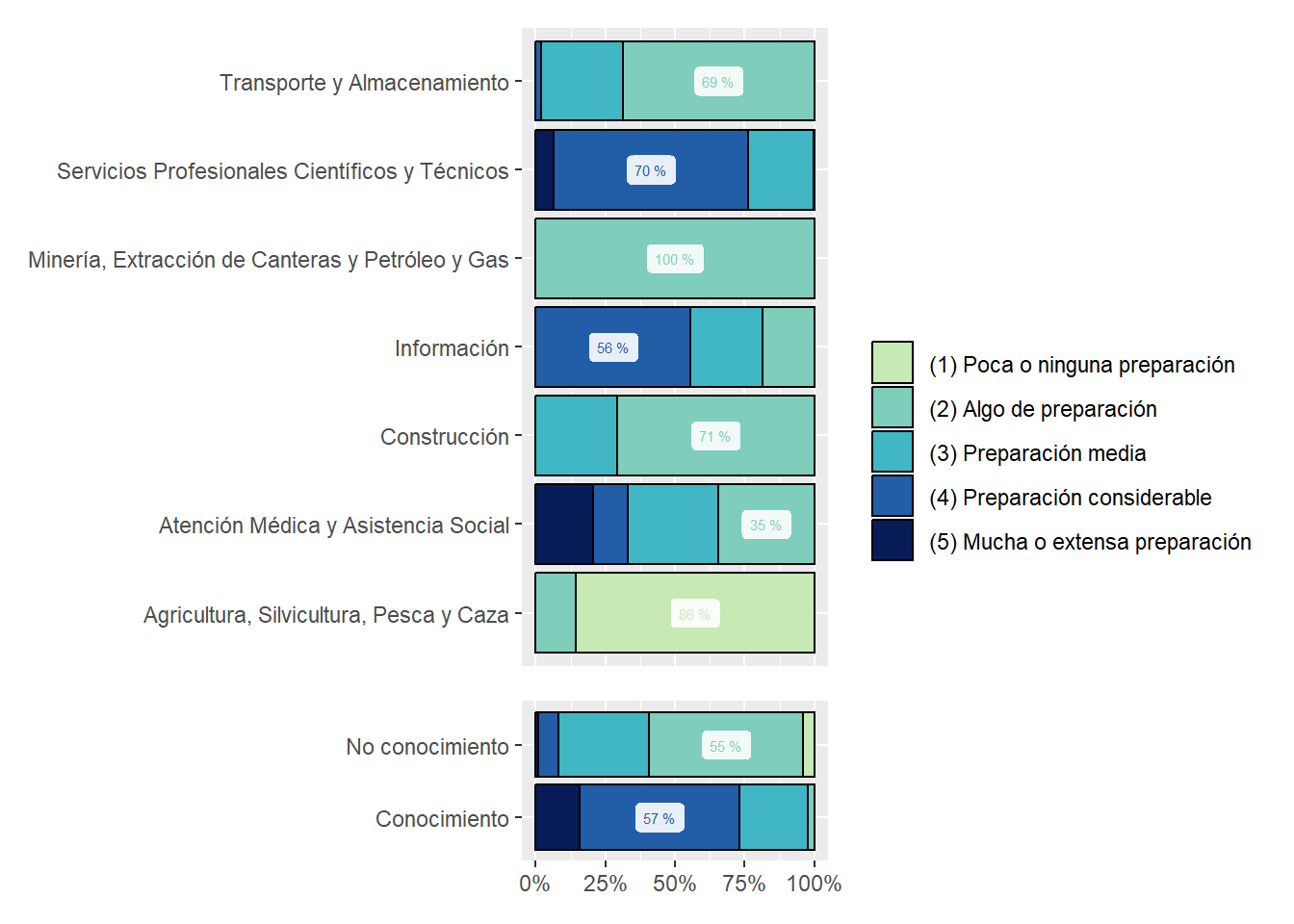
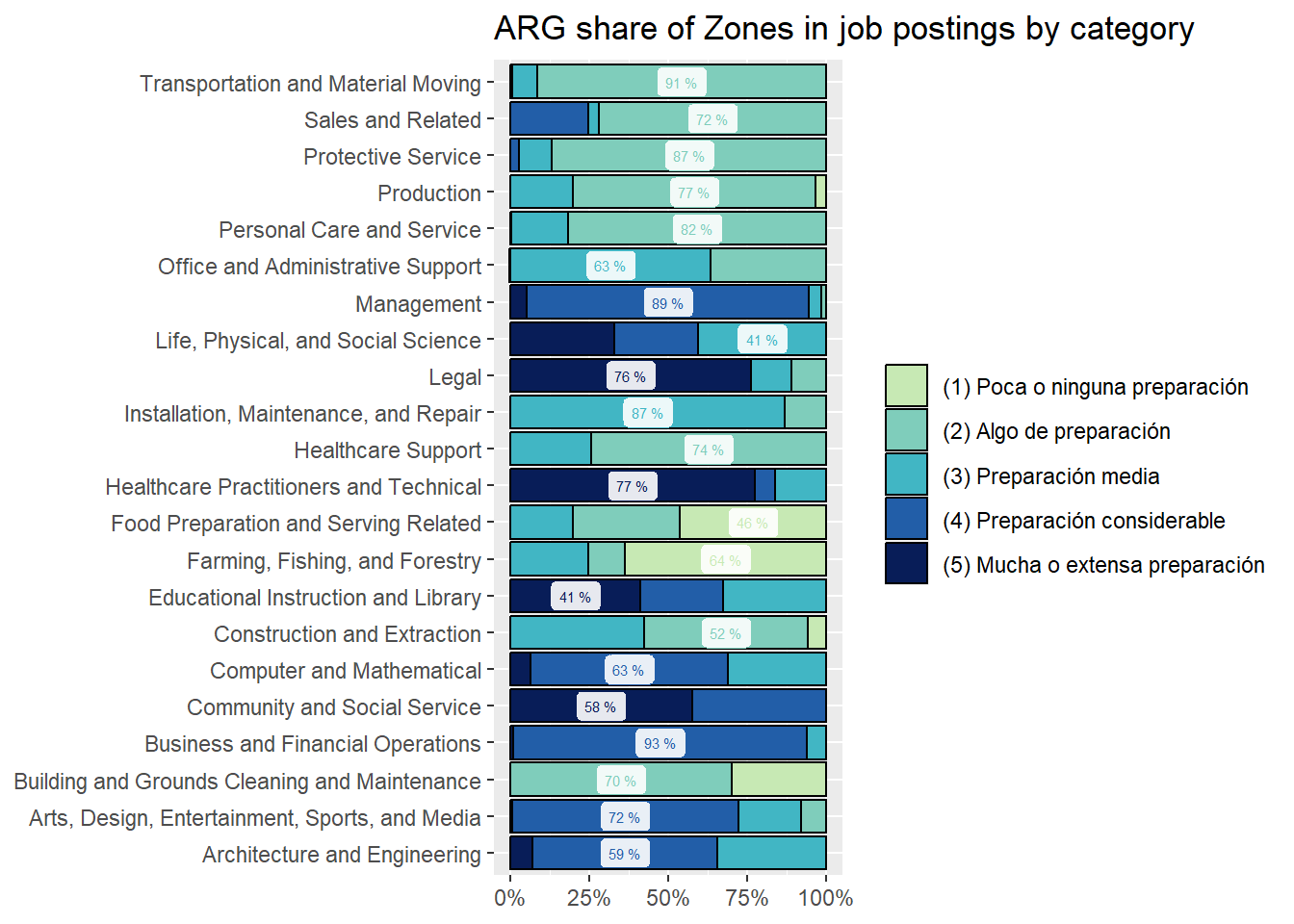
We show sectors’ composition of online vacancies by Job Zone. One of the surprises we found is that Transportation and Warehousing asks for [(4) Preparación Considerable] en around 15% of online vacancies, at least in Argentina. See Figure 24.
The breakdown of job zones aligns with our understanding of training and preparation requirements by sector. We’re able to spot minor variations within countries.
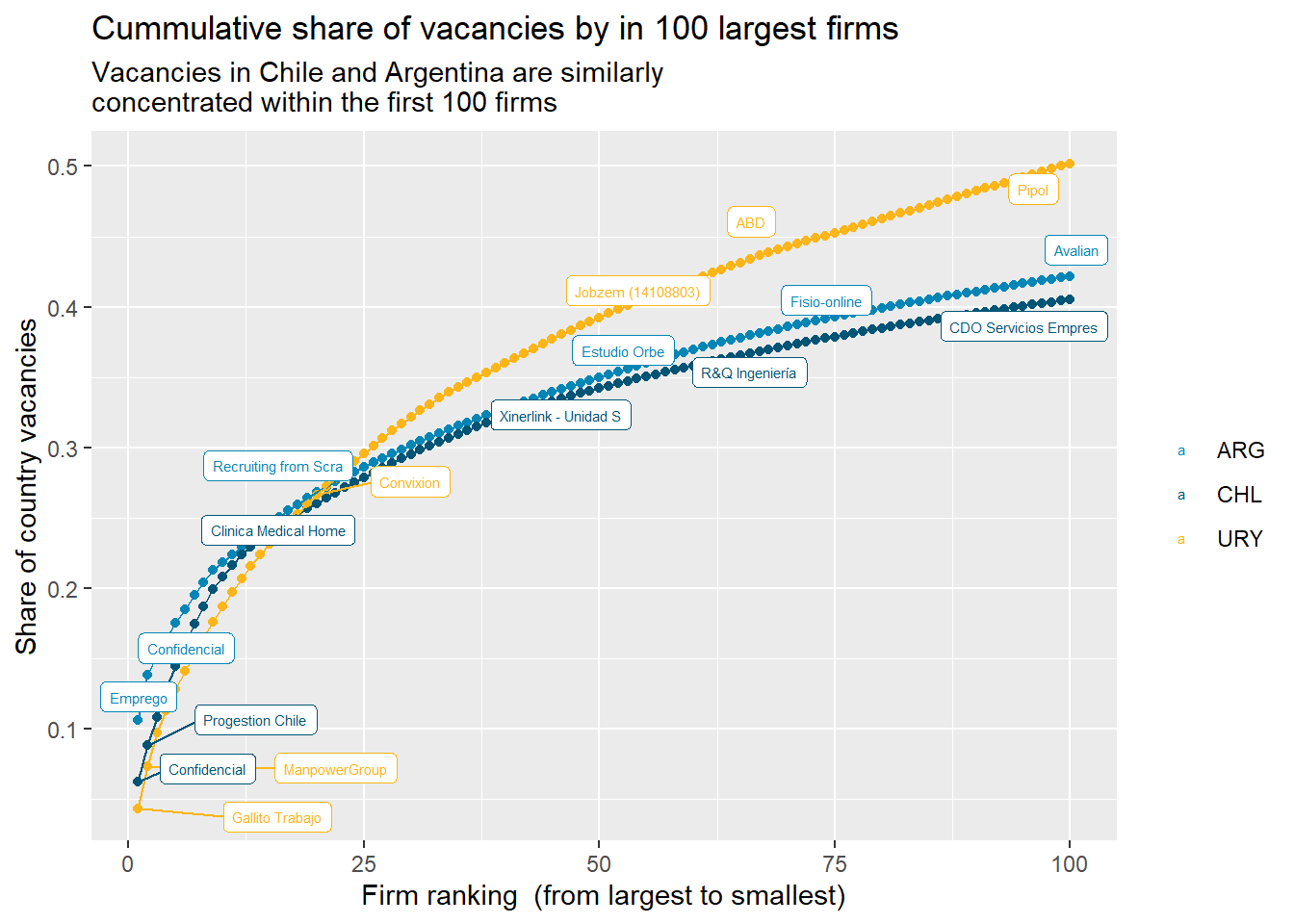
Firms:
Chile and Argentina have around 800 firms (see Table 11 ). The 100 most prominent firms in both countries account for around 40% of all job vacancies. We present a plot to help policymakers spot the hottest demand firms across different periods (see Figure 51).
Ideas moving forward:
Automating this report: We could work on automating updates to this or other similar on a monthly basis by establishing an API connection.
Creating a dashboard with dates and country filters: We could work on a dashboard that allows the user reproduce all these plots and statistics and includes date/country filters. The tool would be connected to the API.
Follow developments on Argentina Labor markets: Data could be used to track the effects of the incoming labor markets de-regulation in Argentina.
Discuss the effect of AI on labor demand:Acemoglu, Autor, et al 2022 have used online job vacancies and AI exposure measures to discuss heterogeneous effects of AI on labor demand. Our data is very similar, only short.
Measure labor market tightness: Geographical granularity offers valuable insights for policy makers. This could allow researchers create estimates of labor market tightness in large regions by calculating the ratio of vacancies to unemployment. On the other end, firm granularity could allow policy makers to reach out to firms leading job demand.
Assist green transition efforts: We could explore other dimensions of “green labor demand.” What sectors and firms are behind it? What abilities are they more reliant on? How does it change following COP28 resolutions?
Evidence found here suggest there is a possibility of reducing type II error in remote work classification at a low cost. First step would consist on building a simple NLP model for WFH detection and compare it with “human-in-the-loop” classifications of a sub-sample of postings to measure improvements. Algorithms could grow more complex if needed. If that’s the case I suggest using Taska, Bloom, et. al. 2023) work as guidance.
The IDB online job postings database
Variables
We identify four groups of variables:
Sector weights: will tell us the sector distribution of firms searching for workers. Each column is named after one of the 20 NAICS 2-digits sectors.
Abilities and sub abilities weights: works similar to the sector ones. Each column shows a score associated with that (sub)ability. The raw score apparently lacks any interpretation, but it can be used to either rank items from most to least important, or weight each observations to calculate the aggregate importance of each item. (Sub)Abilities are defined in the ONET Content Model Ability.
Work related variables: Including the occupation title, the work schedule, training and education requirements (zones), whether remote or not, whether green or not, and whether knowledge activity or not.
Names in the database
occupation: Contains occupation titles according to the ONETSOC19 system. The actual codes aren’t available in the table, but titles can be joined to official crosswalks to recover them. Its’ spanish version can be found in onet_job.Problem to report: 2.5% of occupation records are empty, 0% of onet_job are empty.
remote: Binary indicator on whether a possition offers any kind of work from home (WFH) arrangement. Namely remote or hybrid work.
area: Binary indicator on whether a the employer is likely be a knowledge-intensive services provider, as defined by the Ley de Economía del Conocimiento Argentina: **software; nanotecnología; biotecnología; las industrias audiovisual, aeroespacial y satelital; la ingeniería para la industria nuclear y la robótica, entre otras actividades.*
green_job: Variable showing the ONET green occupation category a vacancy falls into (Green New & Emerging, Green Enhanced Skills, and Green Increased Demand.)
job_zone: Variable showing the ONET category of preparation requirements an vacancy falls into. Here, preparation stands for a mix of education, experience, and training.
schedule: Variable showing the contractual arrangement offered in the vacancy. It can take “Intership”, “Contractor”, “Part-time”, “Full-time”, and “other” as categories.
Origin variables: Including the id of the vacancy, the date, the country code, firm name, platform, and region.
Names in the database
country_code: The name of the country.
date_posted: The date the vacancy was posted in yyyy-mm-dd format.
firm: The name of the firm publishing the post.
rm: Region Metropolitana. It has 24 unique values for Argentina (equal to Provincia in when the count of vacancies is small, otherwise accounting for important metropolitan areas). Similarly, “rm” has 18 unique values for Chile (two more of what’s supposed to be if the intention is showing Regiones), and 6 unique values for Uruguay (way below the 18 Departamentos).
city_name: City. Good providing more geographic granularity. A high-level analysis shows that cities like Vicente Lopez and Quilmes have a combined number of vacancies similar to that of Santa Fe and Rosario combined, Córdoba Capital, and Mendoza Capital.
job_name: The name the employer gave to the vacancy in the posting.
descrip: The raw text description of the job.
There is an statistical summary of these and other relevant variables in table Table 2.
Database statistics
Here we present the dimension and summary statistics of our dataset:
[1] “There are 60689 postings in our data. Job postings count by country:”
latest_country_PEA<-read_csv("data/latest_country_pea.csv") %>%select(country_code=ref_area, PEA=obs_value) %>%mutate(PEA=PEA,PEA_share=PEA/sum(PEA))country_code_df %>%left_join(latest_country_PEA) %>%gt() %>%tab_header(title ="Overall Statistics",subtitle =paste0("Between ", min(south_cone_df$date_posted), " and ",max(south_cone_df$date_posted), ". Population data comes from ILOSTAT") ) %>%fmt_percent(ends_with("share")) %>%fmt_integer(columns =vars(country_vacancies,PEA)) %>%cols_label(country_vacancies ="Online vacancies",country_share ="Online vacancies (%)",PEA ="Working Age Pop (Thousands)",PEA_share ="Working Age Pop (%)" )
Table 1:
Summary
Overall Statistics
Between 2023-09-25 and 2023-10-29. Population data comes from ILOSTAT
Characterizing labor market demand (Work in progress)
This section consists in highlighting vacancy distributions of each country across different indicators (occupational groups, sectors, skills, sub-skils, job zones, work schedule, green jobs, remote jobs, knowledge jobs, regions, and firms). Each indicator will have its own section.
Unless otherwise specified, each section will start with the overall distribution of vacancies across that variable, followed by the same distribution within each country. Each section is then finalized a relative concentration analysis, showing where is each country more specialized vis a vis its’ peers.
In other words, analysis will answer the following questions:
Whats more common?
What’s the most common in each country?
Which country has more of each group?
Which country has a higher than average concentration on each group?
Across occupations
We prepare the South Cone data for aggregation at the Major SOC group (2018) level. We first get the ONET SOC 19 code of each occupational title in the data, and then use ONET crosswalk to SOC18.
Summary
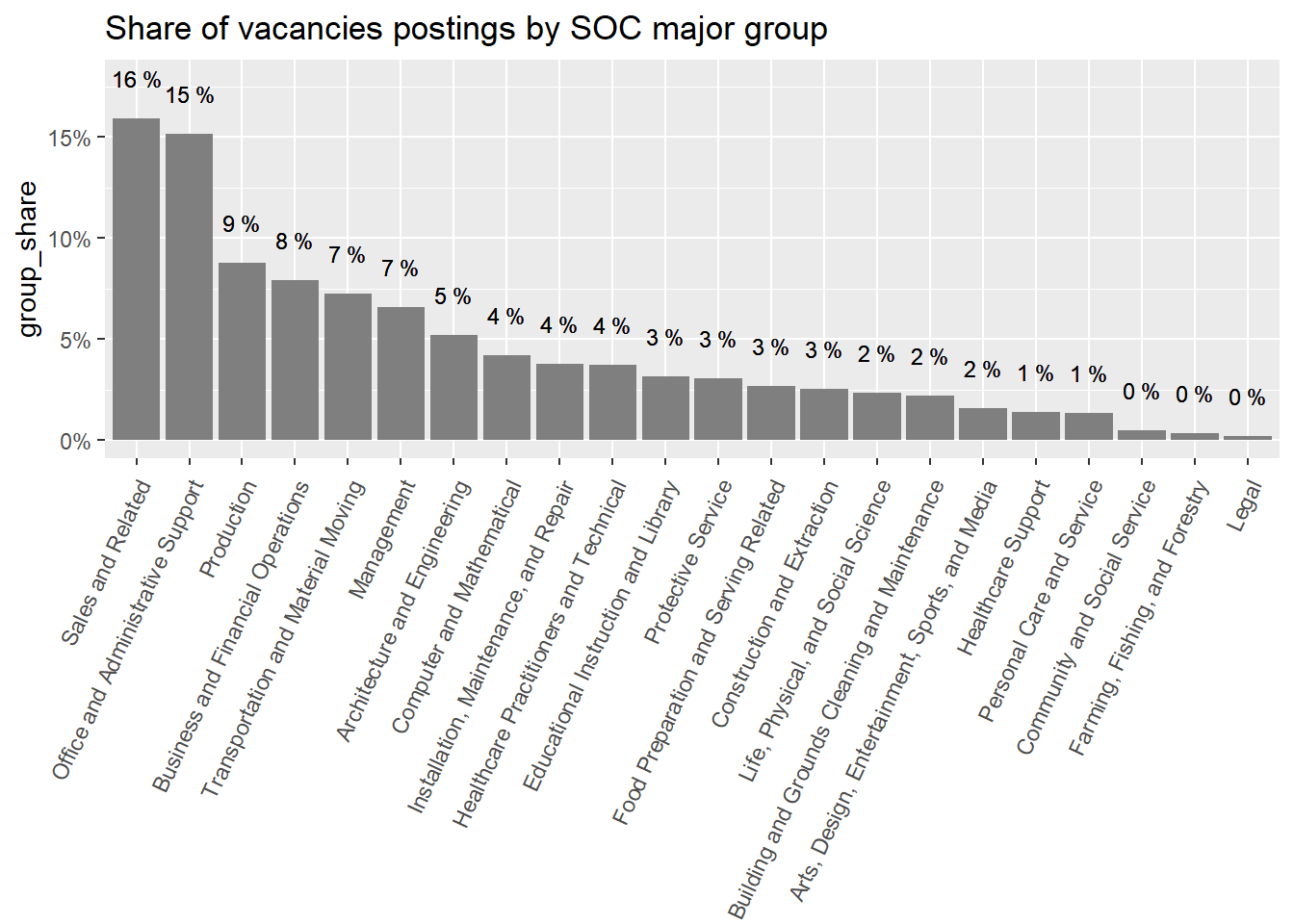
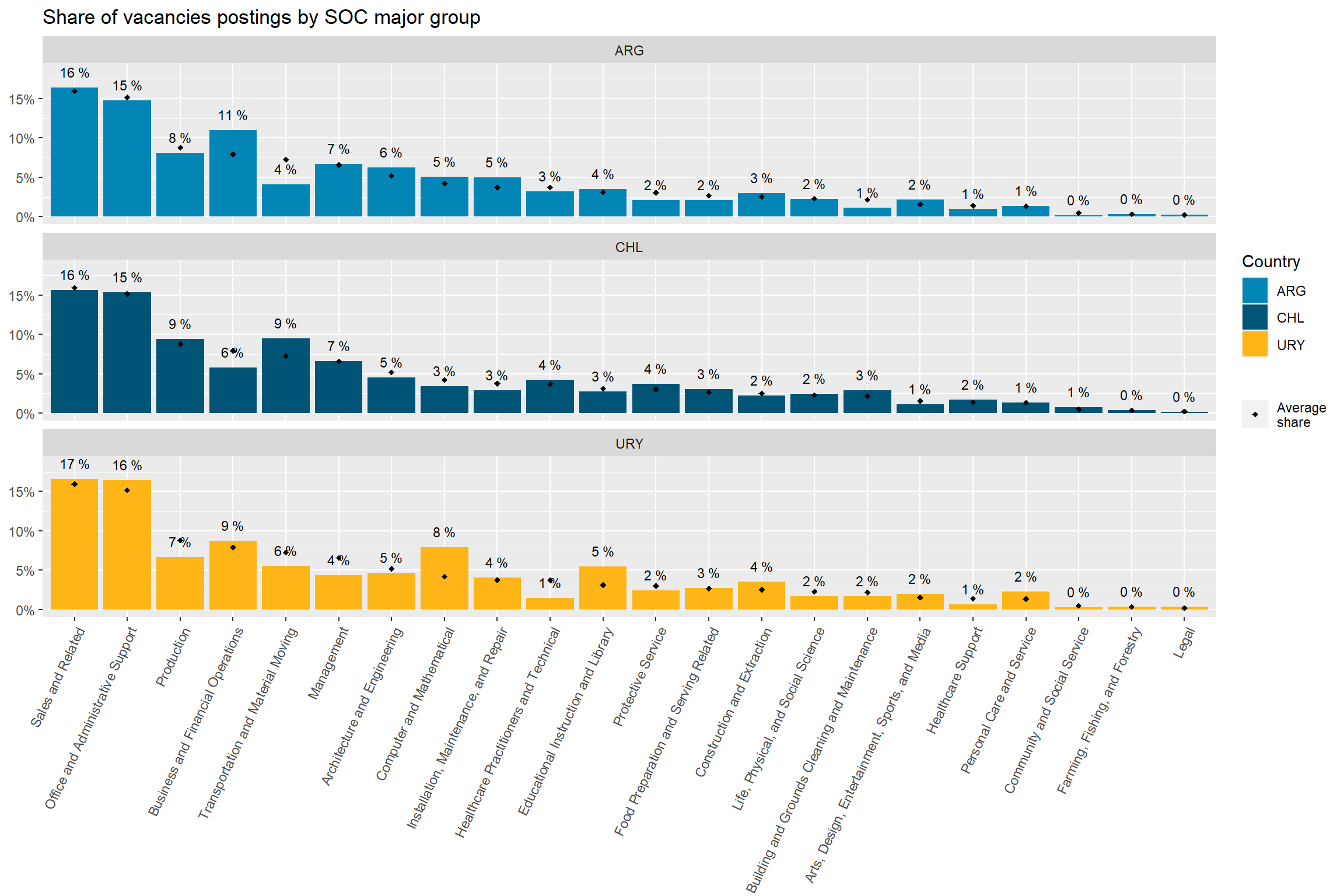
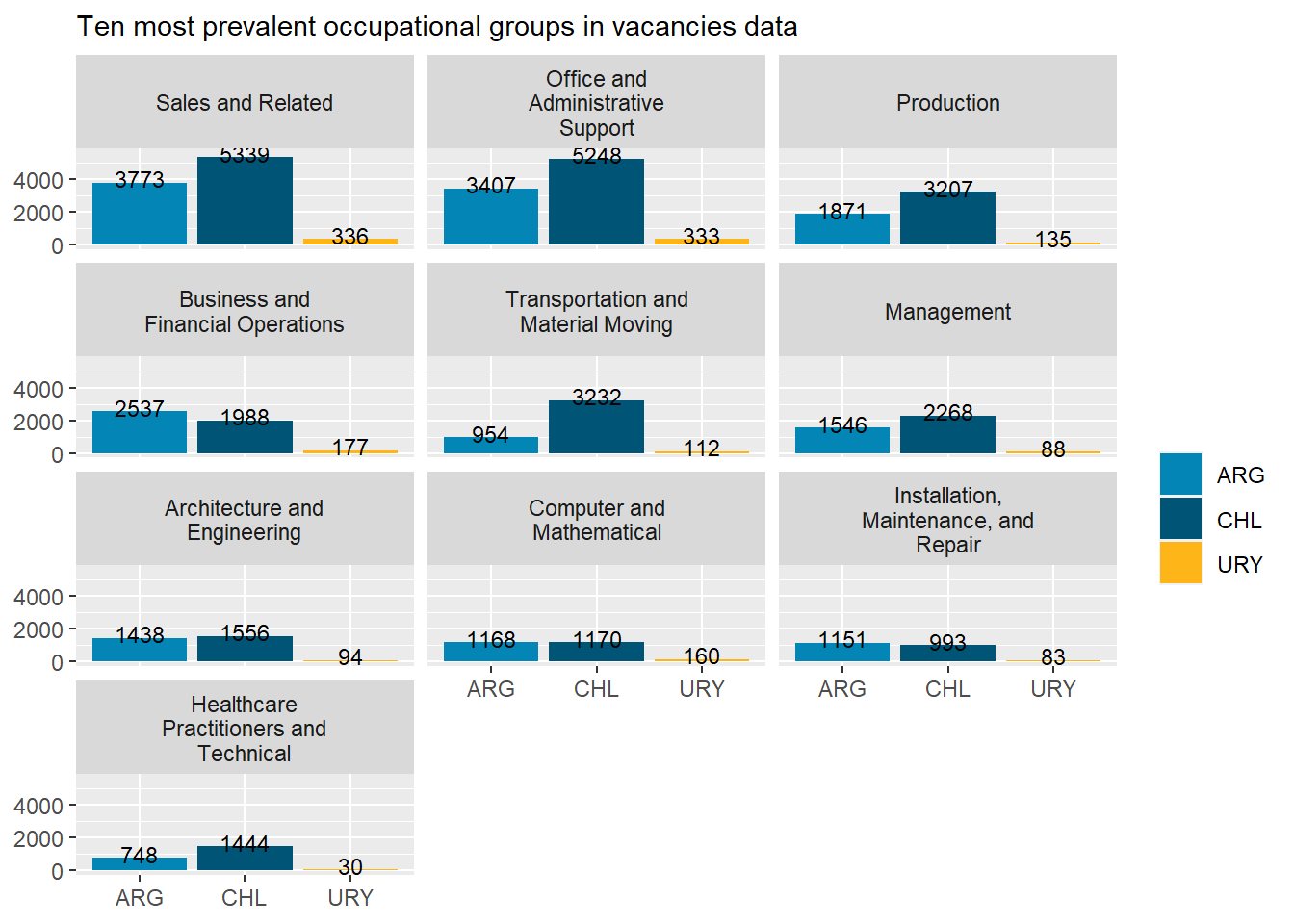
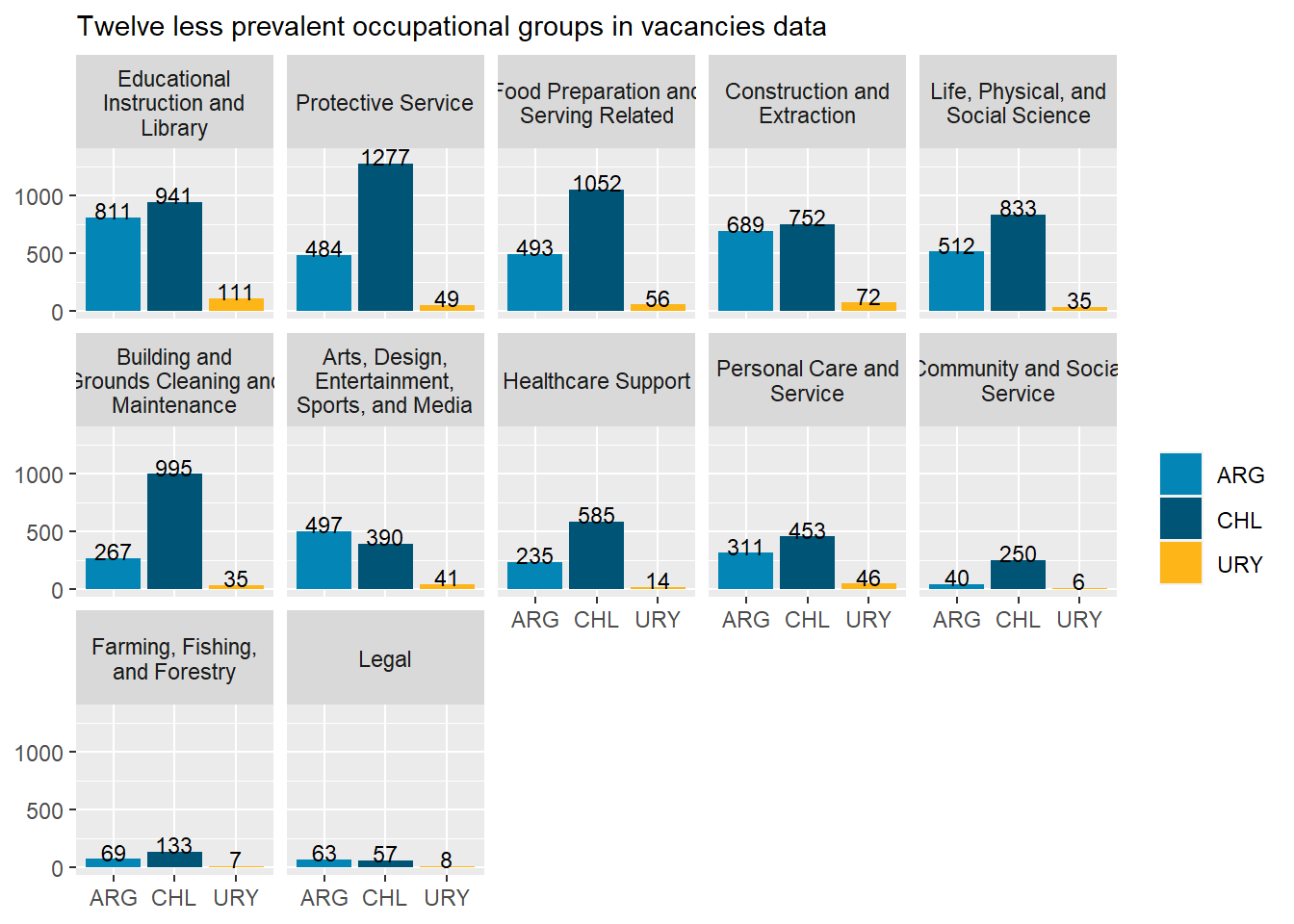
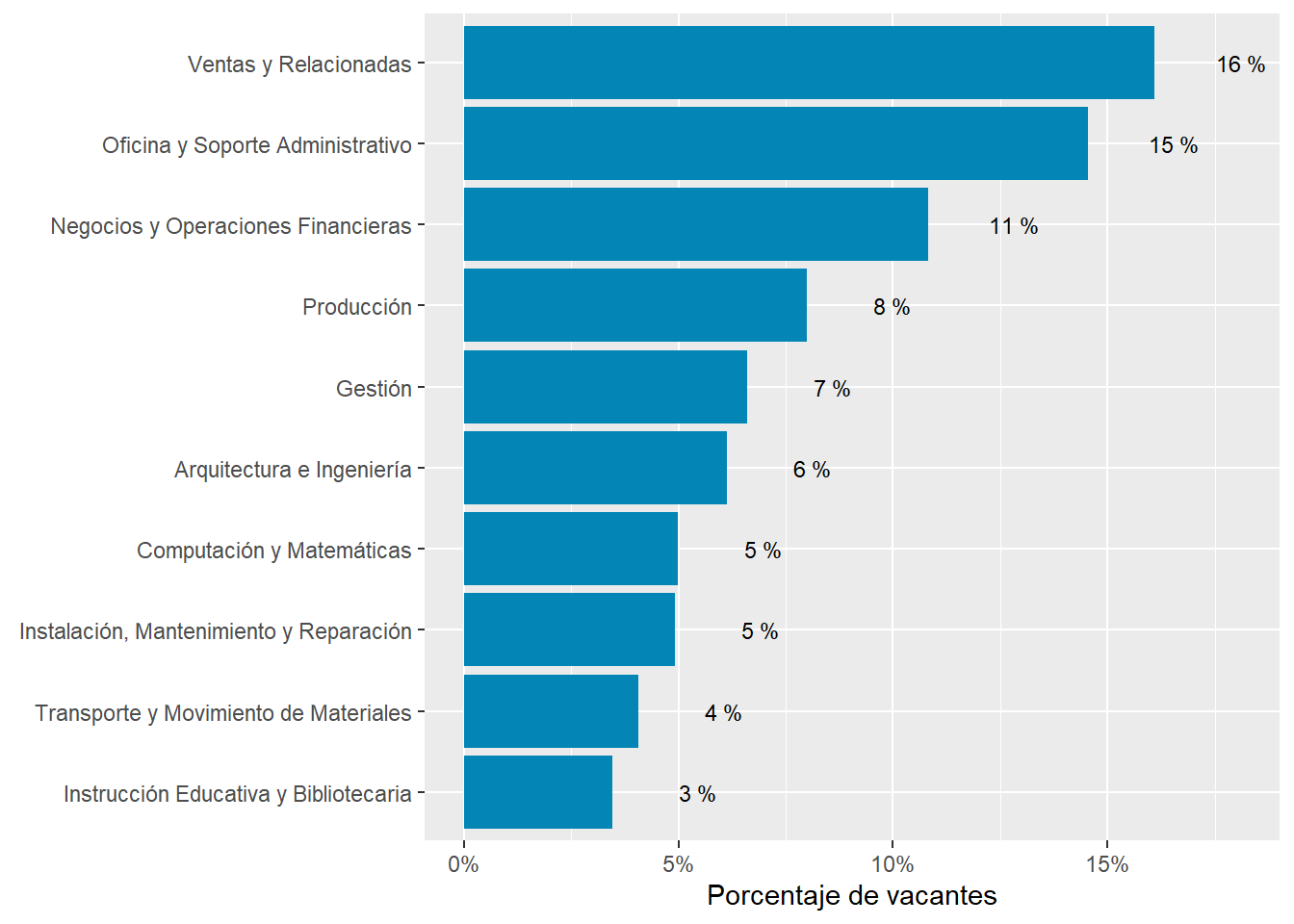
“Sales and Related”, “Office and Administrative Support”, “Production”, “Business and Financial”, “Management”, “Architecture and Engineering”, and “Computer and Mathematical” occupations are the most prevalent occupational groups across all countries. Together they account for about 70% of all vacancies.
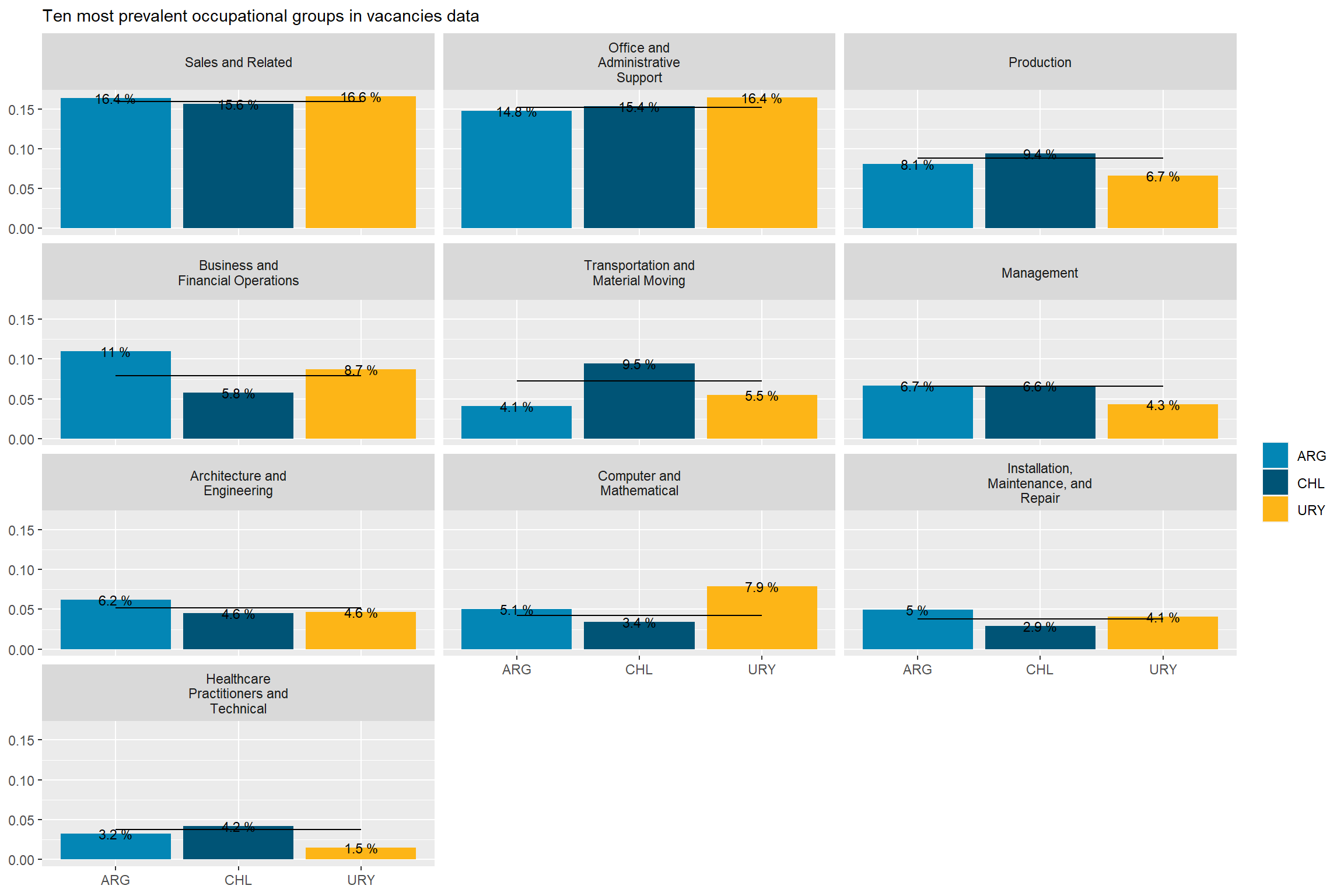
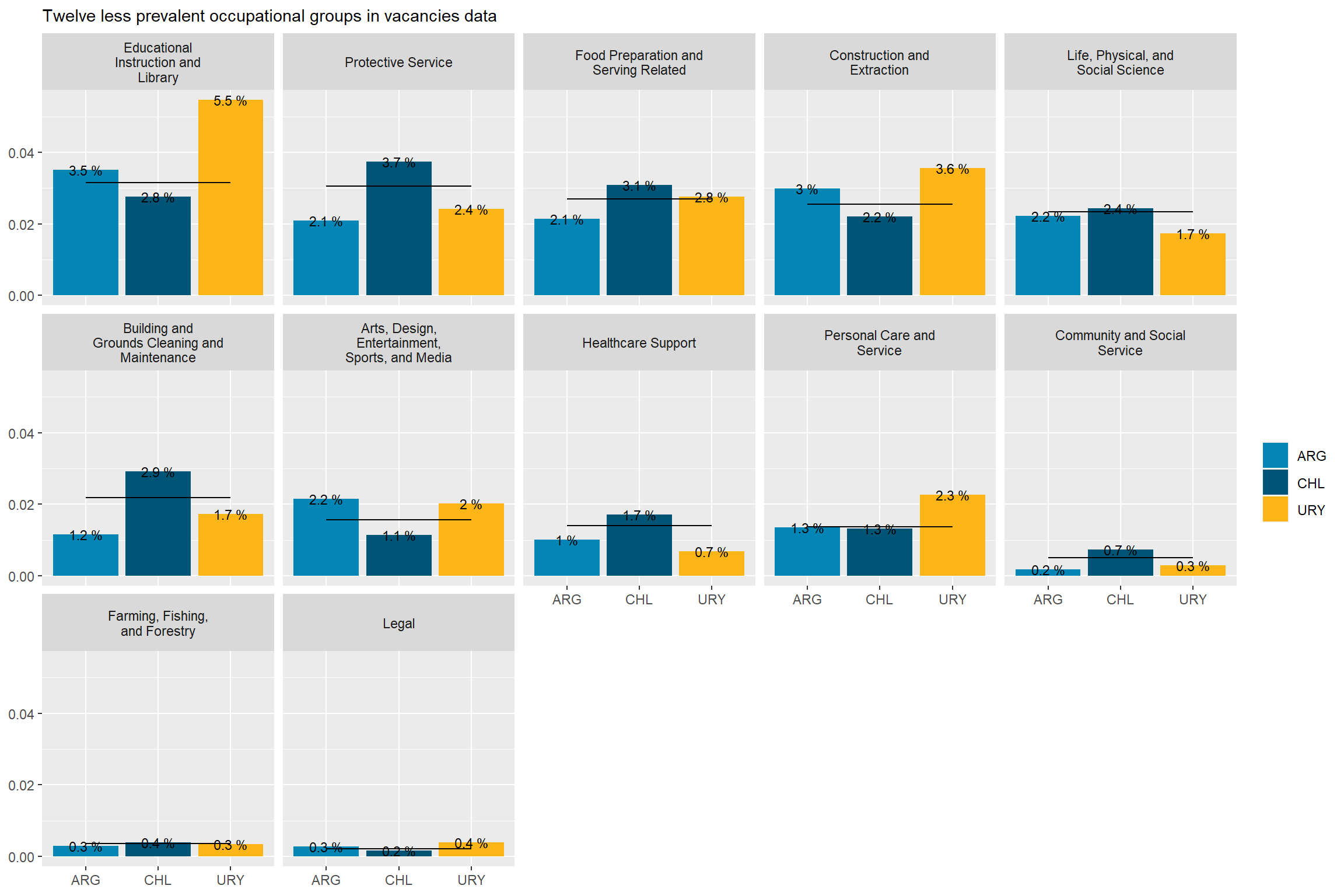
Argentina’s demand is remarkably strong in “Business and Financial Operations”, “Arts, Design, Entertainment, and Media” and “Installation, Maintenance, and Repair” occupations, as well as remarkably in “Transportation and Material Moving”,“Protective services” and “Community and Social Service” occupations. It’s above average in “Computer and Mathematical” and “Architecture and Engineering Occupations”.
Chile accounts for almost 60% of the sample, so it swings much less from the average than Argentina and Uruguay. Chile’s demand is remarkably strong in “Transportation and Material Moving Occupations”, “Building and Ground Cleaning and Maintenance”, and “Community and Social service” occupations. It’s remarkably in “Business and Financial Operations Occupations” and below average in “Computer and Mathematical occupations”.
Uruguay’s demand is remarkably strong in “Computer and Mathematical Occupations”, “Educational Instruction and Library Occupations”, “Personal Care and Service”, “Construction and Extraction”, and “Legal” occupations. It’s remarkably in “Management”, “Healthcare Support”, and “Healthcare Practitioners and Technical” Occupations, which was unexpected.
What’s more common?
We calculate the frequency of each Major SOC group in the South Cone as a whole.
Code
## frecuency table of occupationsmajor_group_df<-south_cone_df %>%group_by(major_group,major_group_title)%>%summarise(group_vacancies=n())%>%ungroup()%>%mutate(group_share=group_vacancies/sum(group_vacancies))%>%arrange(desc(group_vacancies)) ## frequency table of occupations, by countrymajor_group_by_cty<-south_cone_df %>%group_by(country_code,major_group,major_group_title)%>%summarise(count=n() ) %>%ungroup() %>%left_join(major_group_df %>%select(major_group,group_vacancies)) %>%left_join(country_code_df %>%select(country_code,country_vacancies)) %>%mutate(group_in_country_share=count/country_vacancies,country_in_group_share=count/group_vacancies) %>%ungroup()
Code
cat_var_chart(data=mutate(south_cone_df,major_group_title=str_remove_all(major_group_title,"Occupations")),category ="major_group_title")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by SOC major group",x=NULL)
Figure 1: Major SOC group distribution
What’s more common in each country?
We calculate the frequency of each Major SOC group in each country. For each row, we calculate the share of that group in the country and the share of the country in the group.
Code
country_major_soc_df<-country_var_count(data=mutate(south_cone_df,major_group_title=str_remove_all(major_group_title," Occupations")),country ="country_code",category ="major_group_title")country_var_chart(agg_data=country_major_soc_df,country ="country_code",category ="major_group_title")[[1]]+scale_fill_manual(values=country_colors)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by SOC major group",fill="Country",shape=NULL,x=NULL,y=NULL)
Figure 2: Major SOC distribution, by country
What’s the country most specialized in each group?
Code
# 10 largest occupational groupstop_10_soc<-var_count(data=mutate(south_cone_df,major_group_title=str_remove_all(major_group_title," Occupations")),category="major_group_title") %>%top_n(10,group_share) %>%pull(major_group_title)country_var_chart(agg_data =filter(country_major_soc_df, major_group_title%in% top_10_soc),category ="major_group_title",country="country_code")[[2]] +scale_fill_manual(values=country_colors)+labs(subtitle="Ten most prevalent occupational groups in vacancies data",fill=NULL,x=NULL,y=NULL)# 12 smallest occupational groupsbottom_12_soc<-var_count(data=mutate(south_cone_df,major_group_title=str_remove_all(major_group_title," Occupations")),category="major_group_title") %>%top_n(12,-group_share) %>%pull(major_group_title)country_var_chart(agg_data =filter(country_major_soc_df, major_group_title%in% bottom_12_soc),category ="major_group_title",country="country_code")[[2]] +scale_fill_manual(values=country_colors)+labs(subtitle="Twelve less prevalent occupational groups in vacancies data",fill=NULL,x=NULL,y=NULL)
Figure 3: Major SOC distribution by country, side by side
Figure 4: Major SOC distribution by country, side by side
Which country has the largest number of vacancies in each group?
Code
# 10 largestcountry_var_chart(agg_data =filter(country_major_soc_df, major_group_title%in% top_10_soc),category ="major_group_title",country="country_code")[[3]] +scale_fill_manual(values=country_colors)+labs(subtitle="Ten most prevalent occupational groups in vacancies data",fill=NULL,x=NULL,y=NULL)# 12 smallestcountry_var_chart(agg_data =filter(country_major_soc_df, major_group_title%in% bottom_12_soc),category ="major_group_title",country="country_code")[[3]] +scale_fill_manual(values=country_colors)+labs(subtitle="Twelve less prevalent occupational groups in vacancies data",fill=NULL,x=NULL,y=NULL)
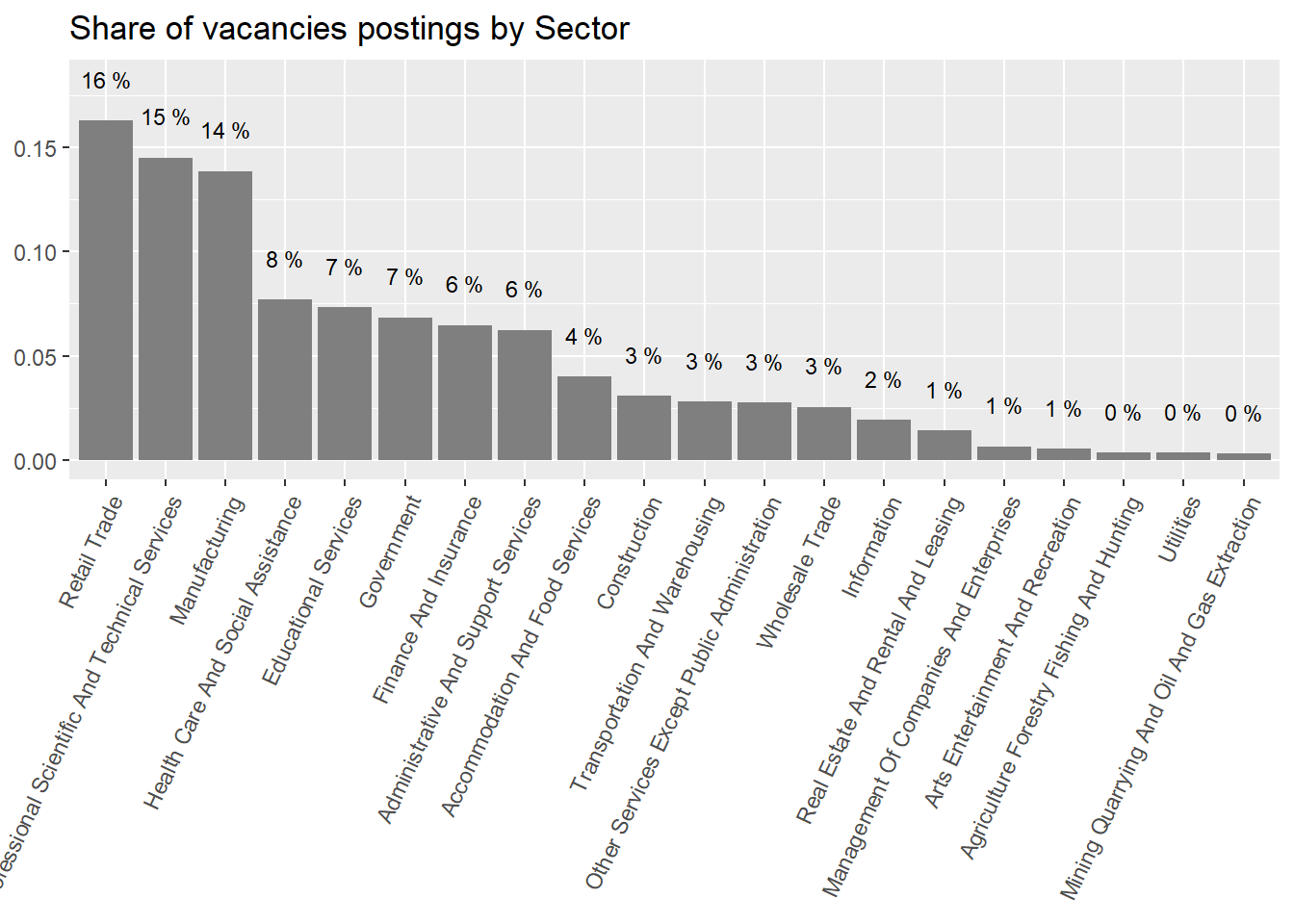
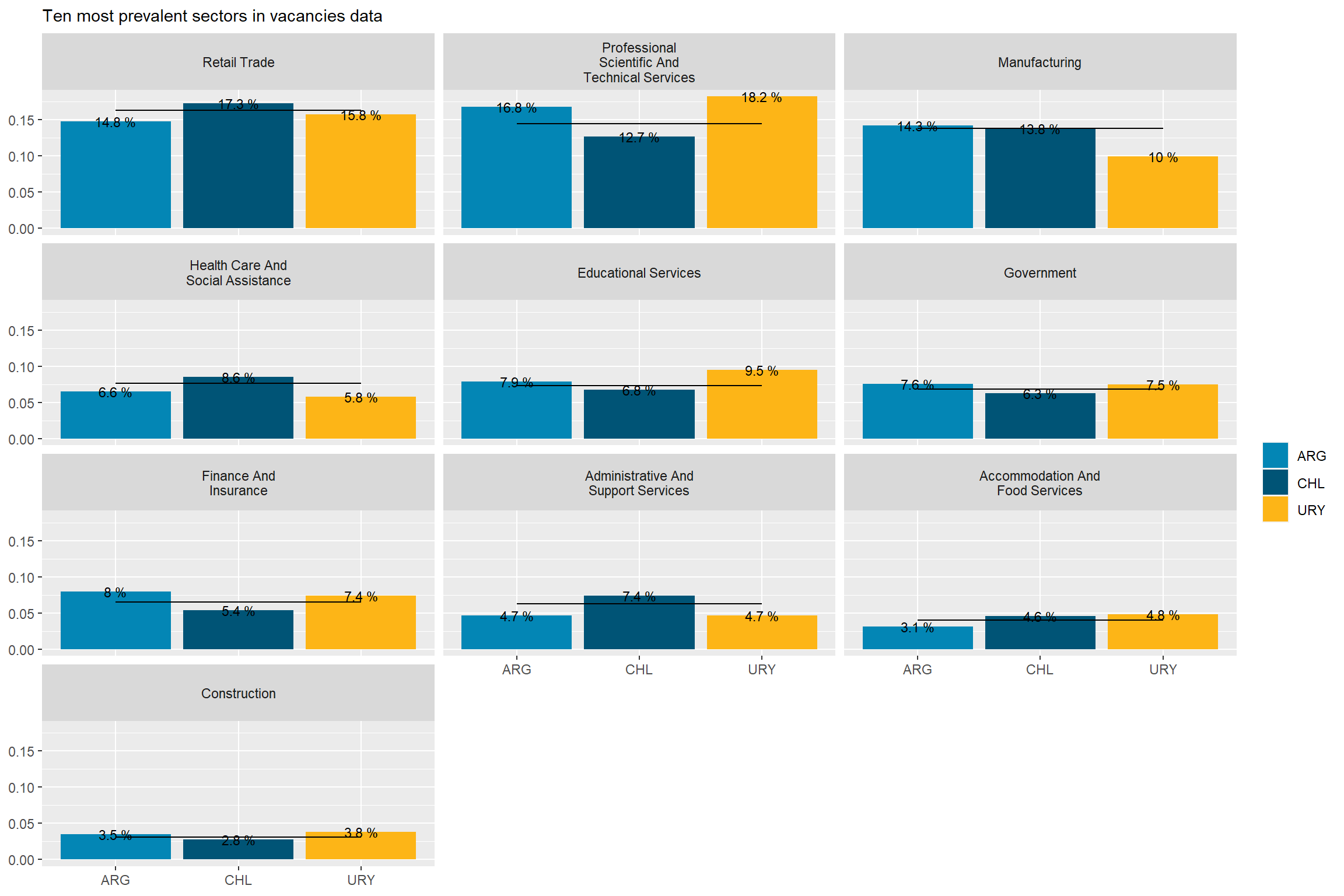
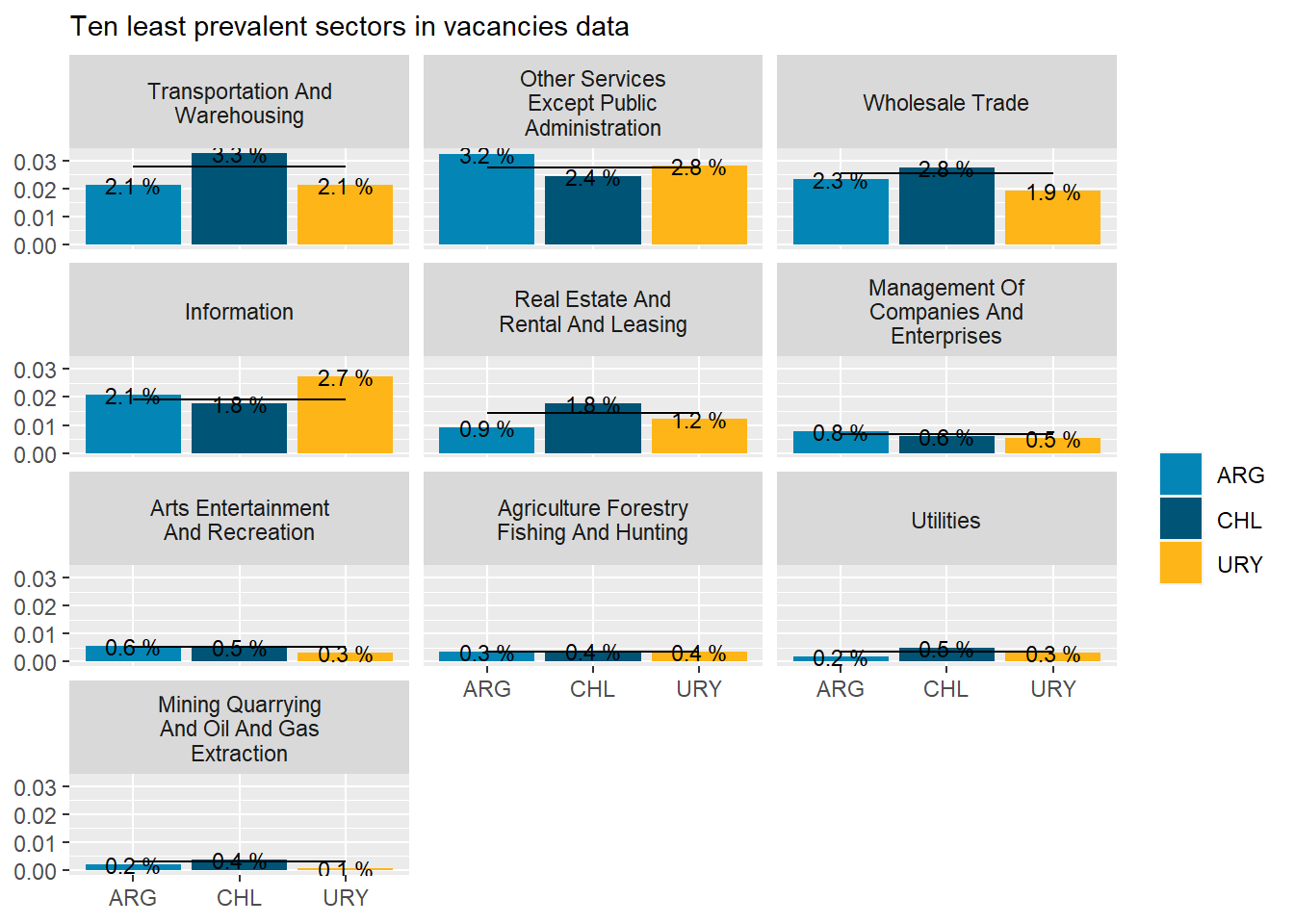
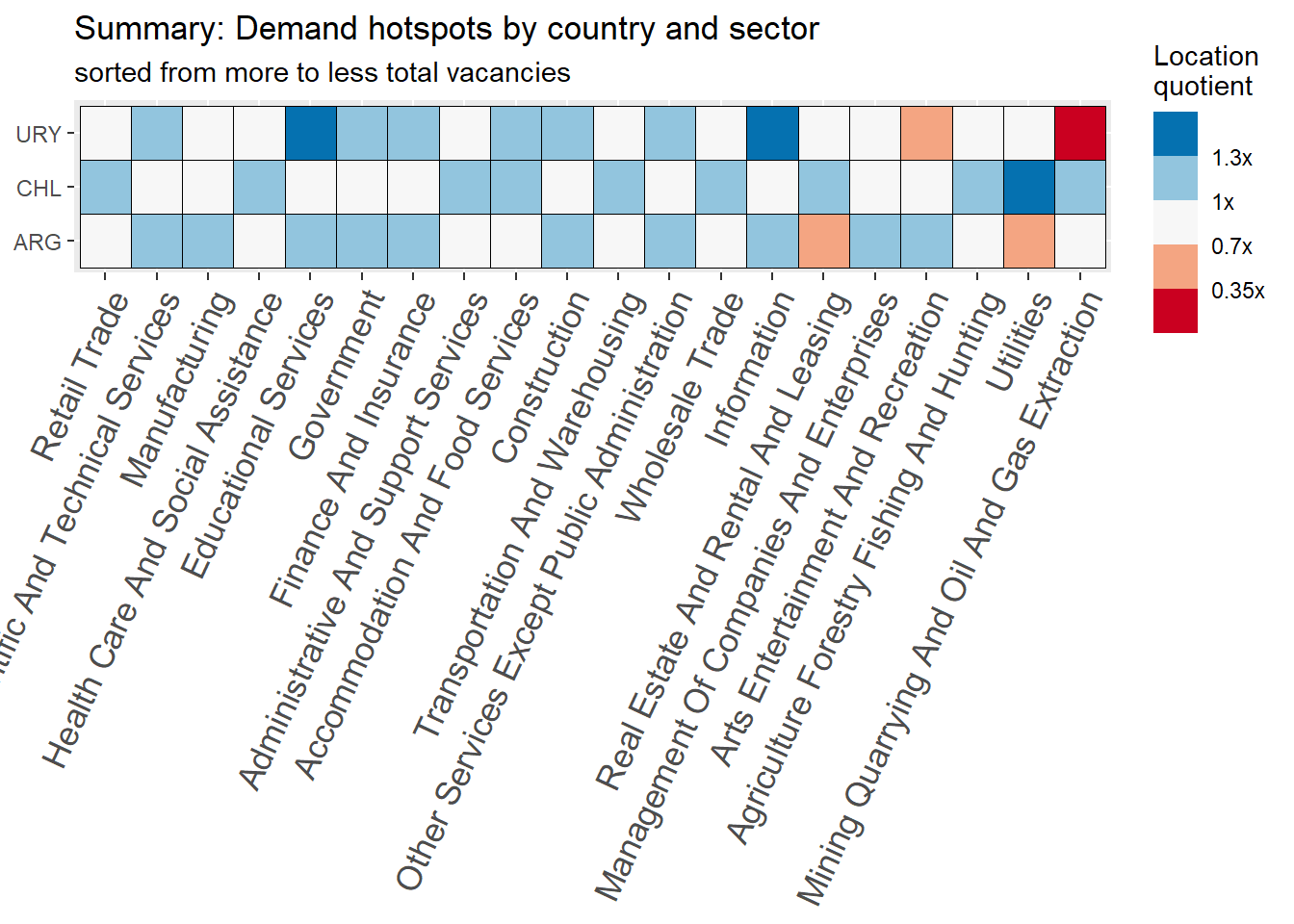
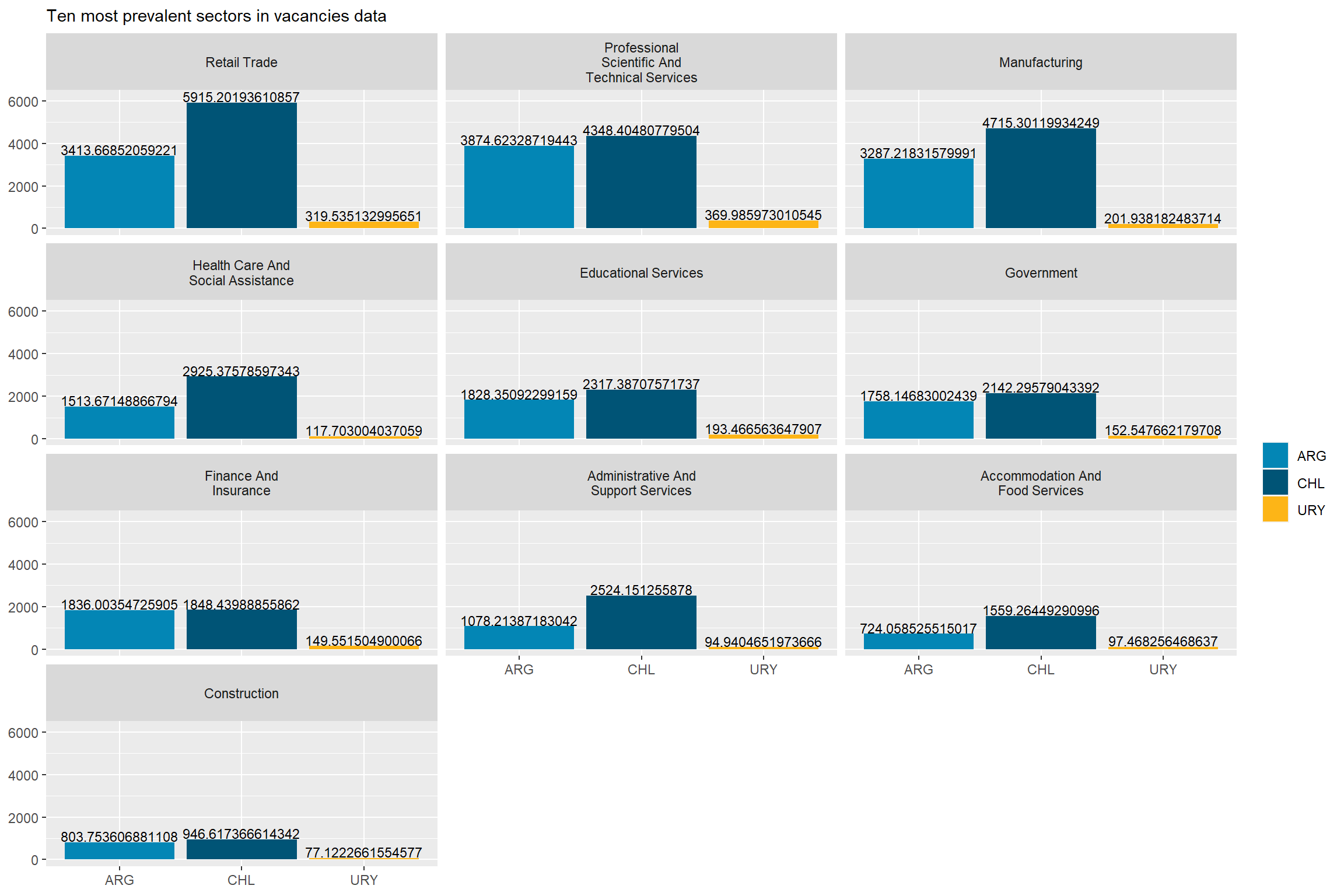
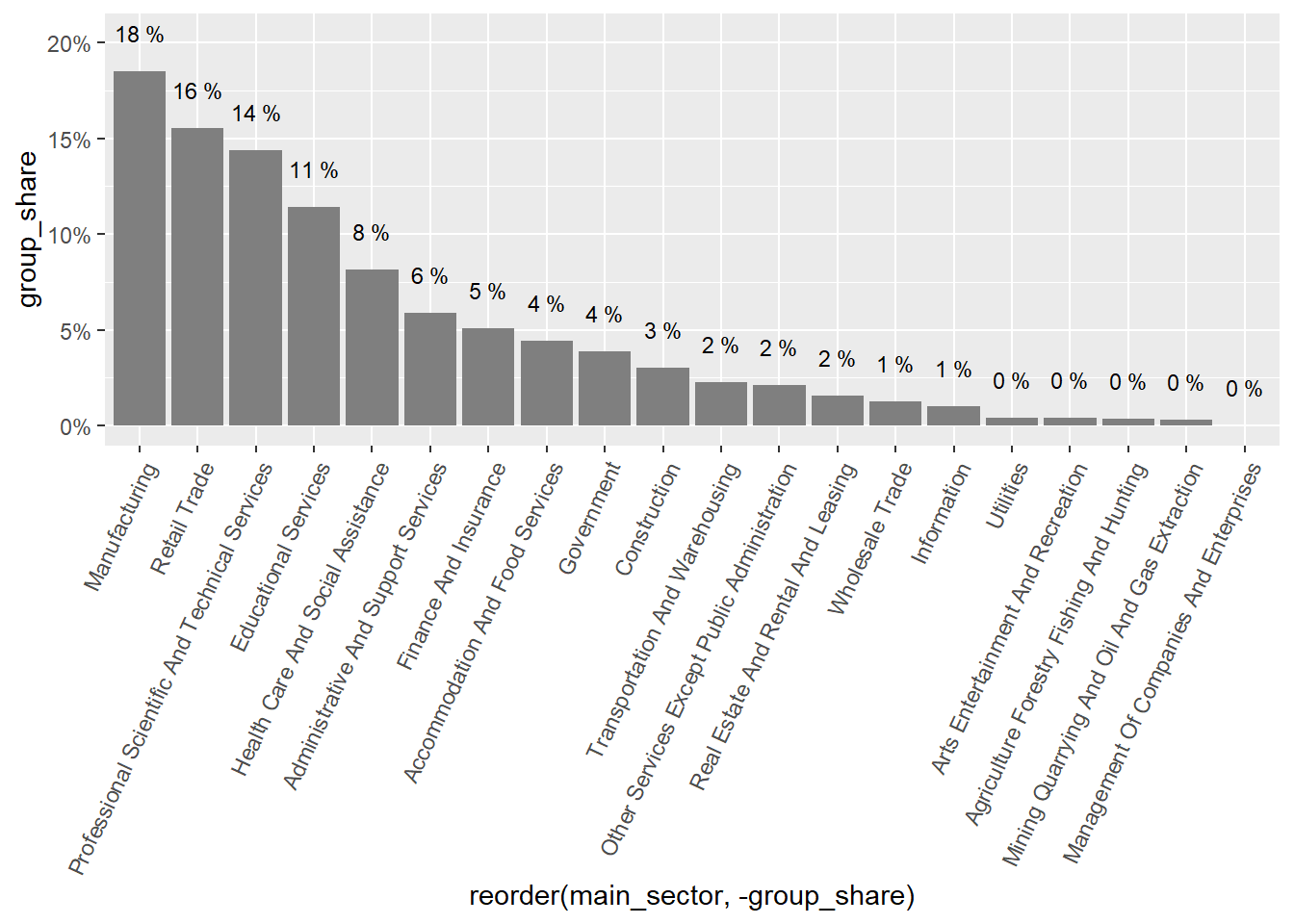
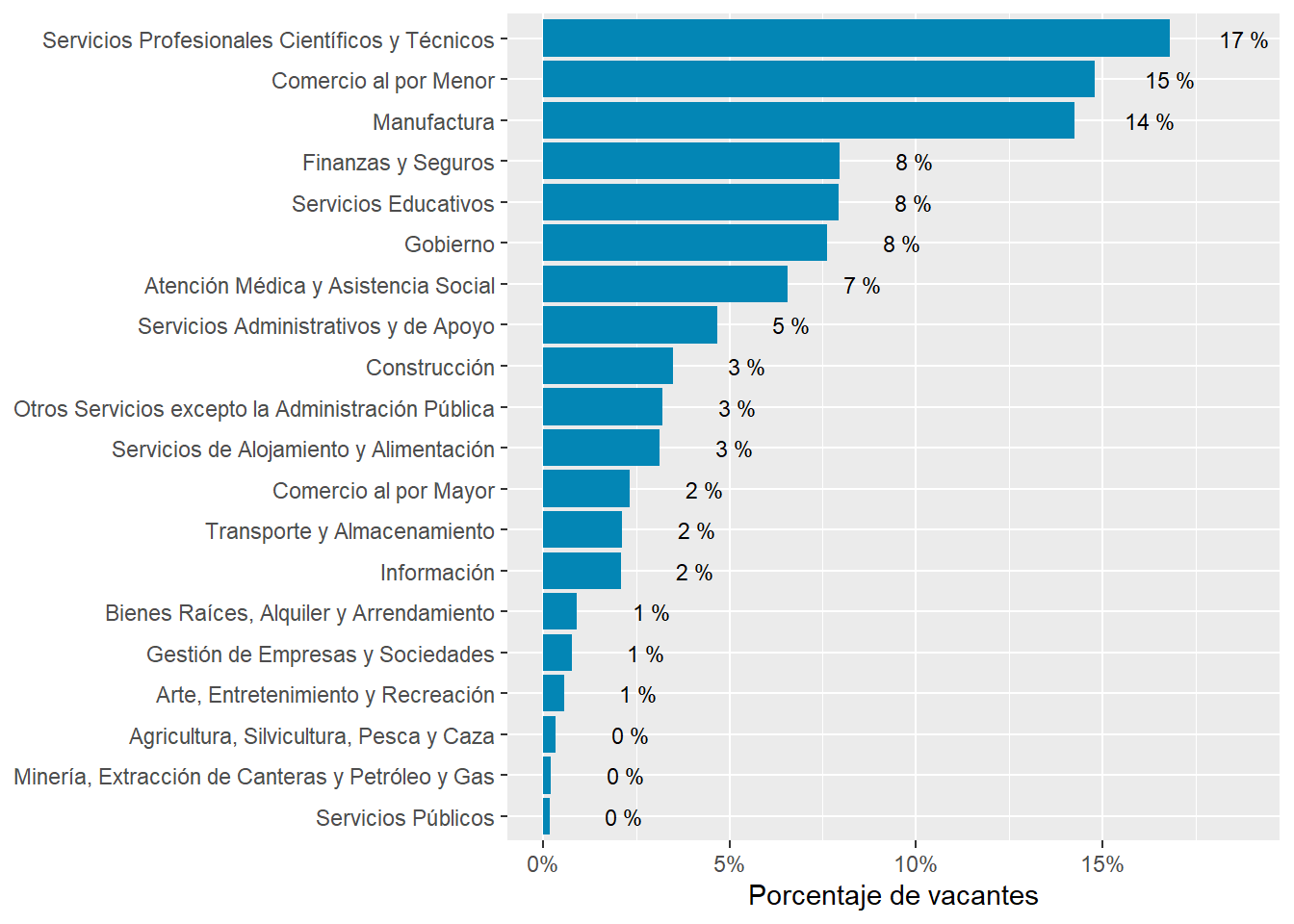
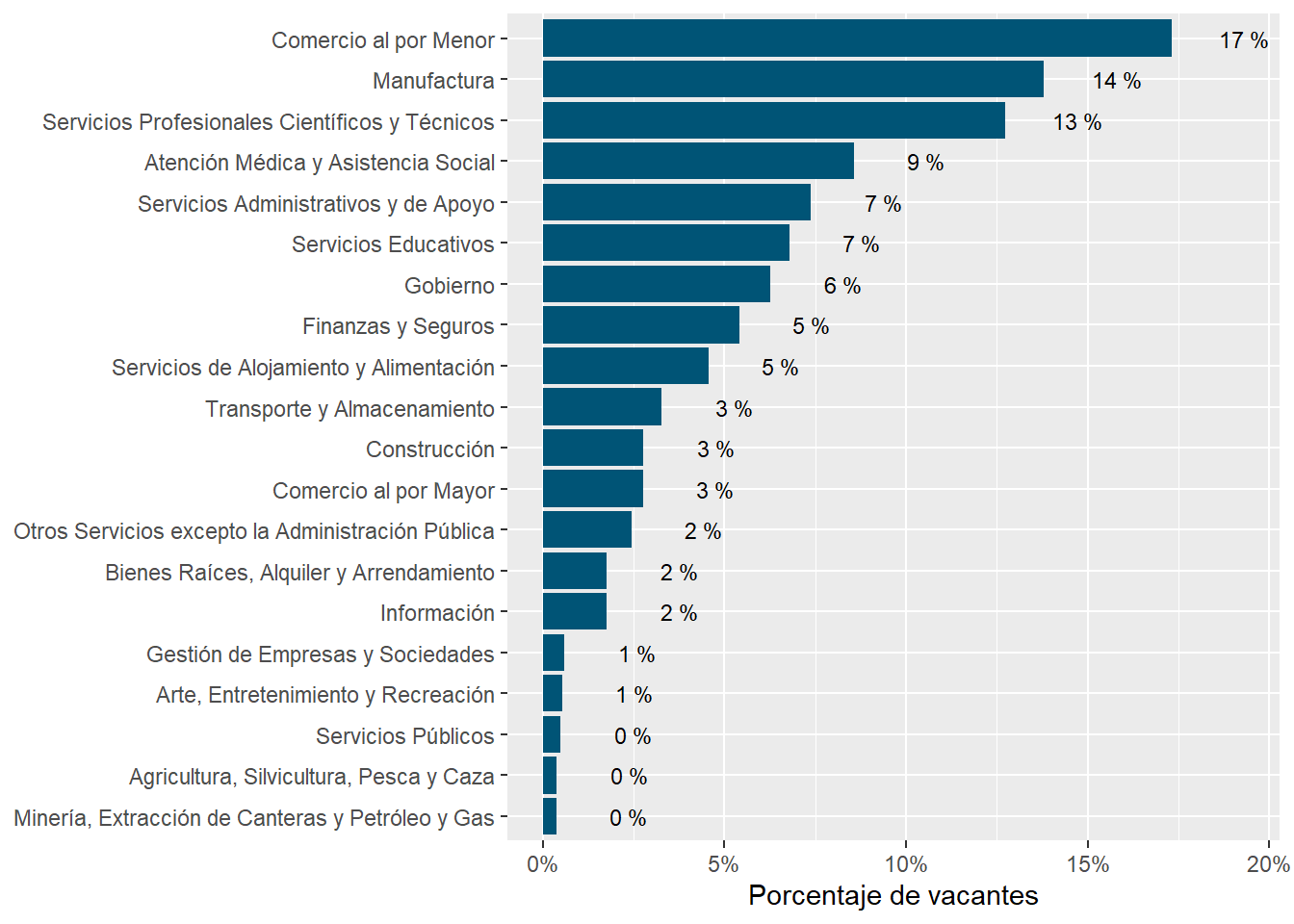
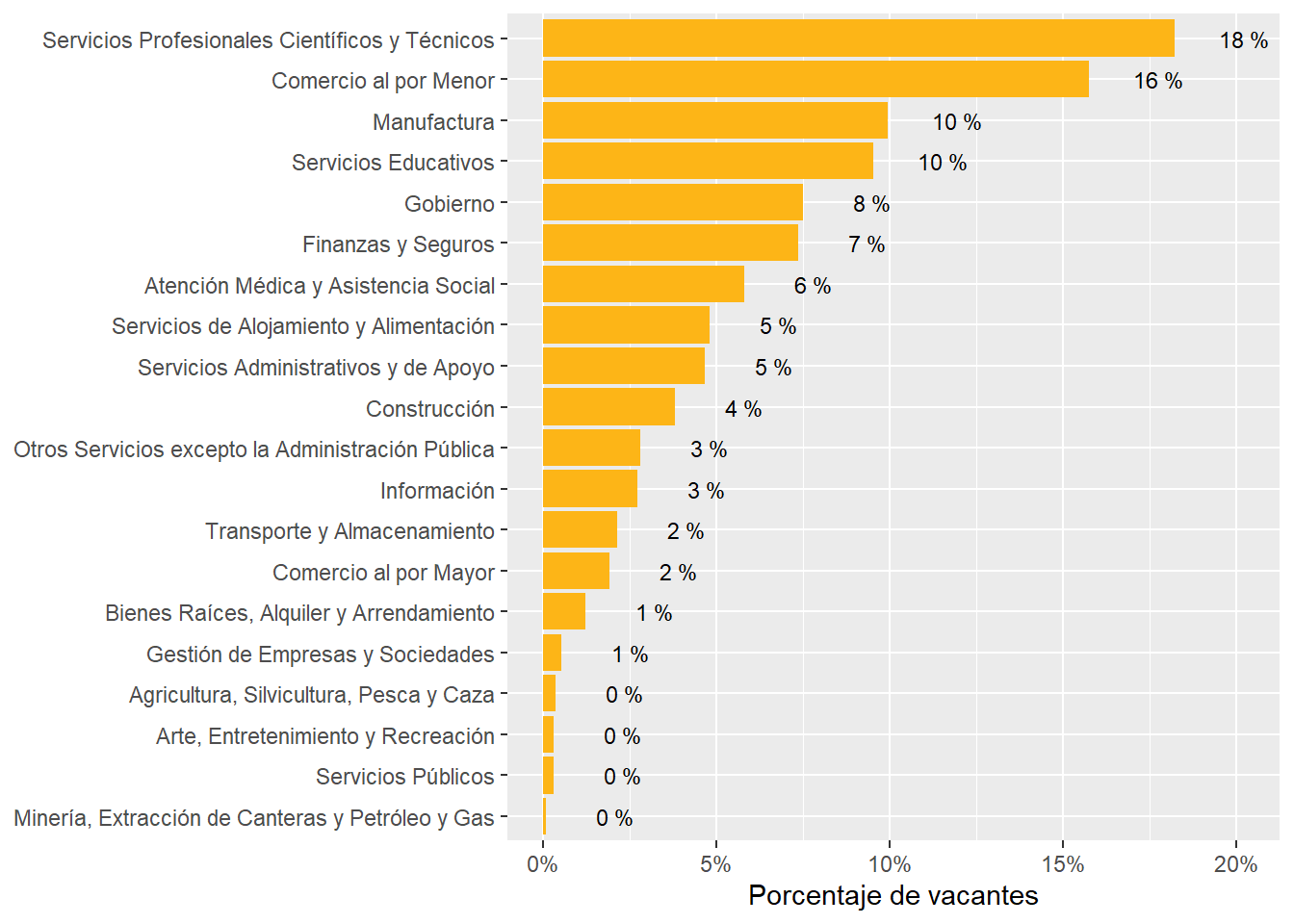
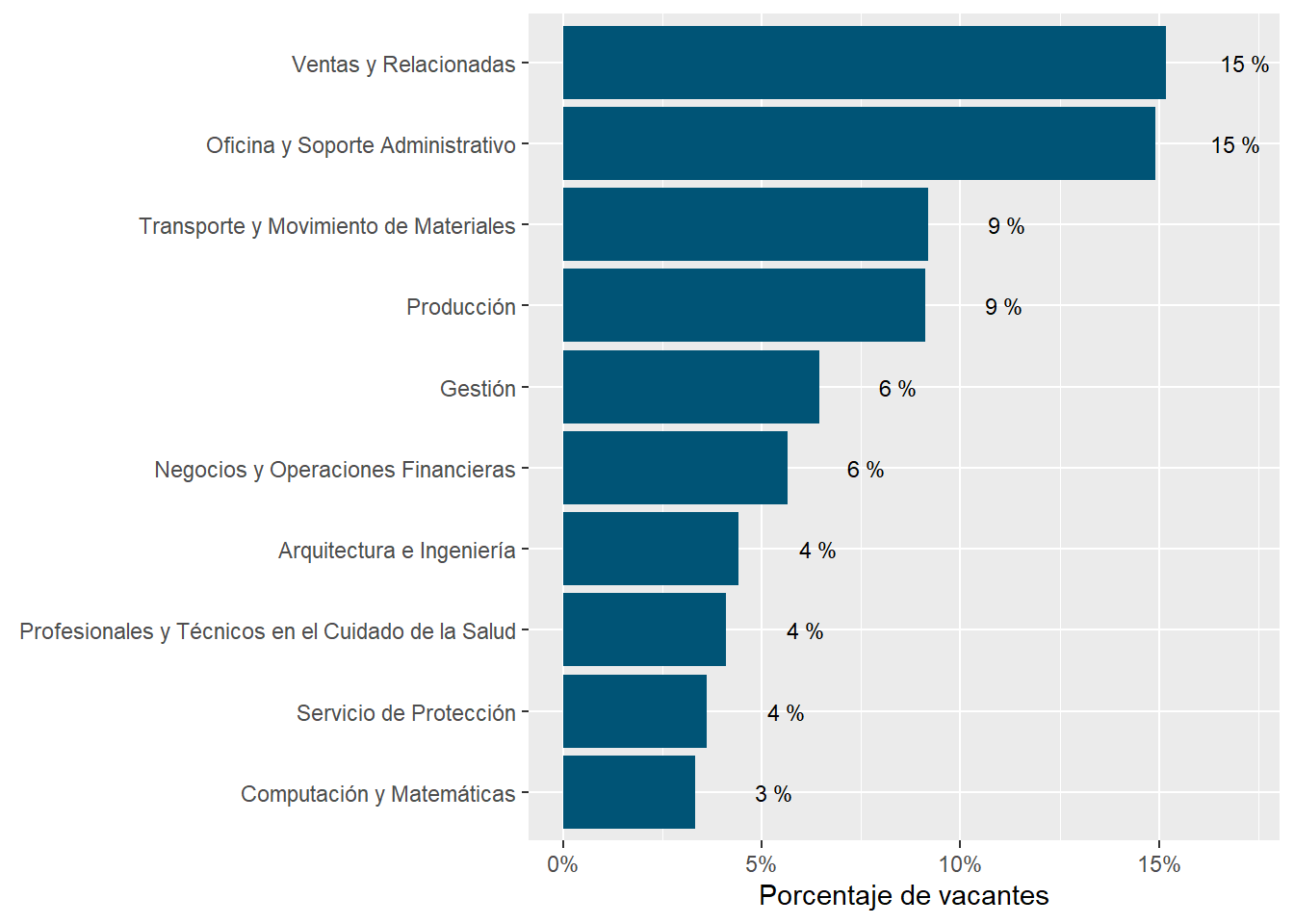
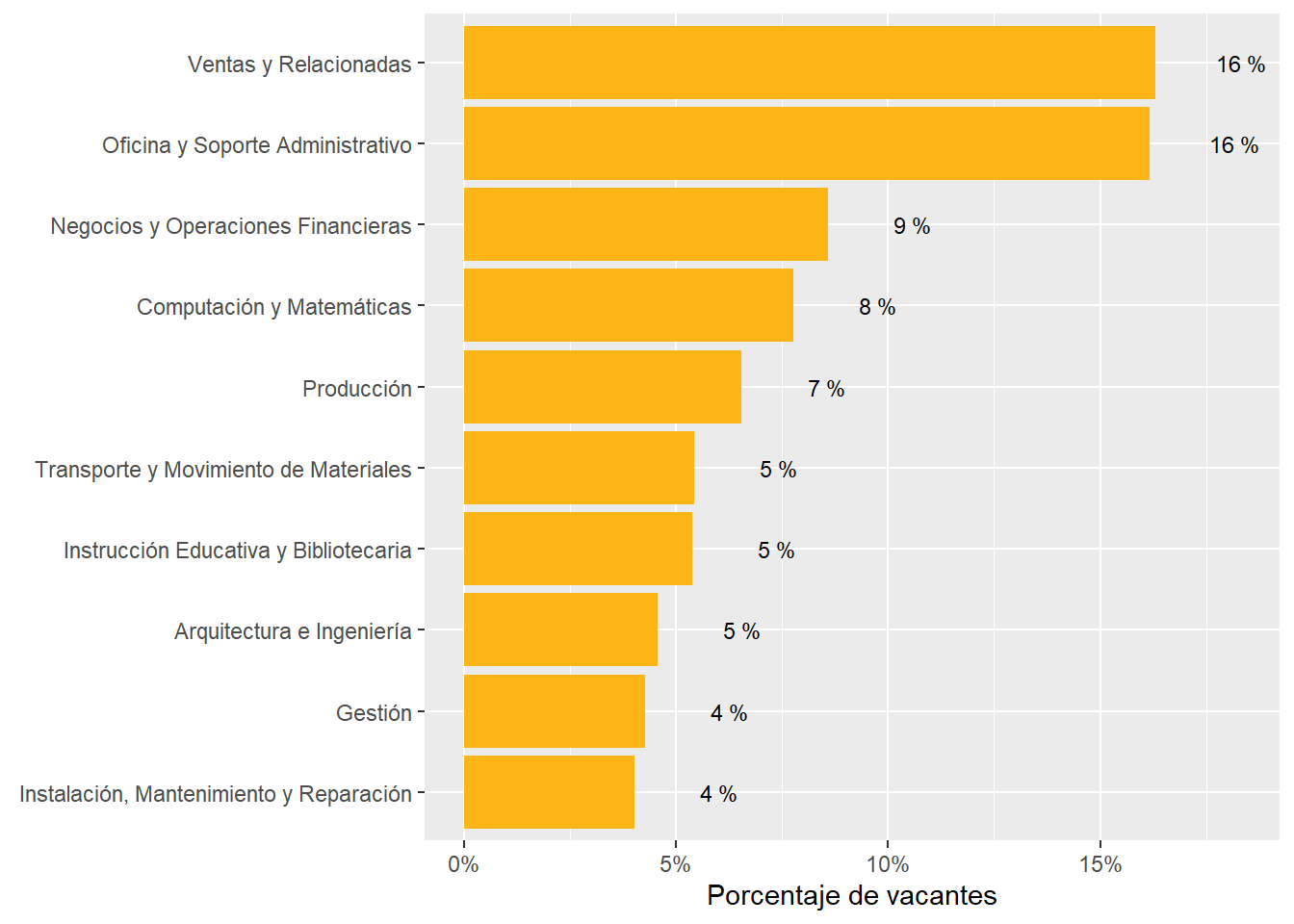
The sectors demanding more jobs online are “Retail Trade”, “Manufacturing”, “Professional scientific and Technical Services”, “Educational Services”, “Government”,and “Finance and Insurance”. They accout for about 83% of all postings.
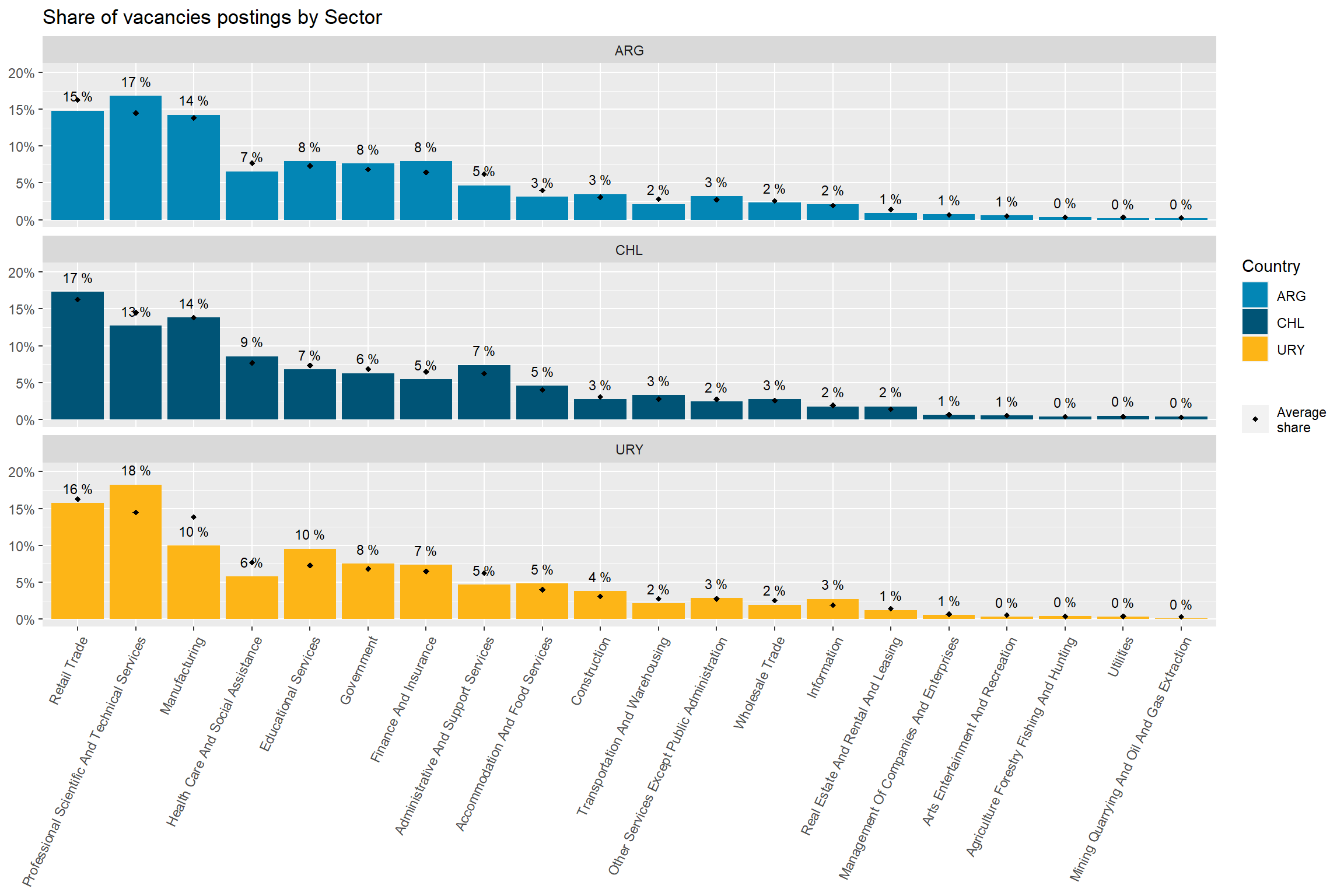
Argentina’s demand is strong in “Finance and Insurance”, “Professional Scientific and technical services”, and “Construction”. It’s particularly weak in “Retail”, “Accommodation and food services”, “Administrative and support services”, and “transportation and warehousing”
Chile’s demand is strong in “Retail trade”, “Manufacturing”, “Health Care and Social Assistance”, “Administrative and Support Services”, “Retail trade”, “Transportation and Warehousing”, and “Wholesale Trade”. It’s particularly weak in “Professional Scientific and Technical Services”, “Finance and Insurance”, “Construction”, “Other Services Except Public Administration”, and “Information.”
Uruguay is super strong in “Professional Scientific and Technical Services”, “Educational Services”,“Construction”, and “Information”. It’s strong in “Construction”. It’s particularly weak in “Health care and social assistance” and “Manufacturing”.
What’s more common?
Code
rama_df %>%distinct(sector,group_share) %>%ggplot(aes(x=reorder(sector,-group_share),y=group_share))+geom_col(fill="gray50")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by Sector",x=NULL,y=NULL)
Figure 7: Sector distribution, with number of vacancies wegithed by the weight of the sector
What’s more common in each country?
Code
country_var_chart(agg_data=rename(rama_df,count=weigths_sum),country ="country_code",category ="sector")[[1]]+scale_fill_manual(values=country_colors)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by Sector",fill="Country",shape=NULL,x=NULL,y=NULL)
Figure 8: ?(caption)
What are countries specialized in?
Code
top_10_naics<-rama_df %>%top_n(30,group_vacancies) %>%pull(sector)# 10 largestcountry_var_chart(agg_data=rename(filter(rama_df,sector %in% top_10_naics),count=weigths_sum),country ="country_code",category ="sector")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Ten most prevalent sectors in vacancies data",fill=NULL,x=NULL,y=NULL)
Figure 9: Sector distribution, by country
Code
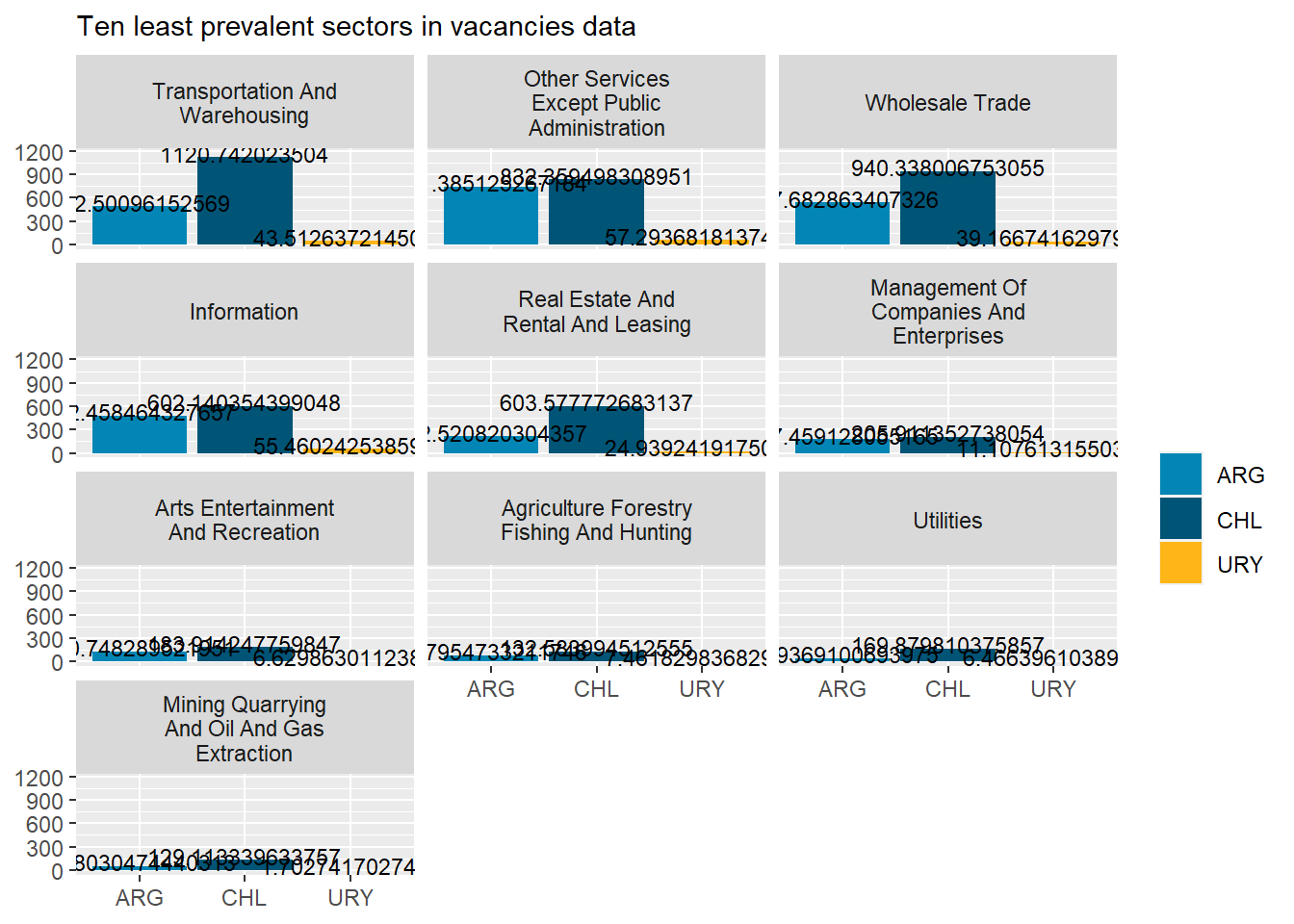
# 10 smallestbottom_10_naics<-rama_df %>%top_n(30,-group_vacancies) %>%pull(sector)country_var_chart(agg_data=rename(filter(rama_df,sector %in% bottom_10_naics),count=weigths_sum),country ="country_code",category ="sector")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Ten least prevalent sectors in vacancies data",fill=NULL,x=NULL,y=NULL)
Code
# Summaryrama_df %>%ggplot(aes(x=reorder(str_to_title(sector),-group_share),y=country_code, fill=group_in_country_share/group_share))+geom_tile(color="black")+theme(axis.text.x =element_text(angle =65, hjust=1, size=13))+scale_fill_fermenter(palette ="RdBu",direction =1, breaks=c(0.35,0.7,1,1.3),labels =function(x) paste0( x, 'x'))+labs(title ="Summary: Demand hotspots by country and sector",subtitle ="sorted from more to less total vacancies",fill="Location\nquotient",y=NULL,x=NULL)
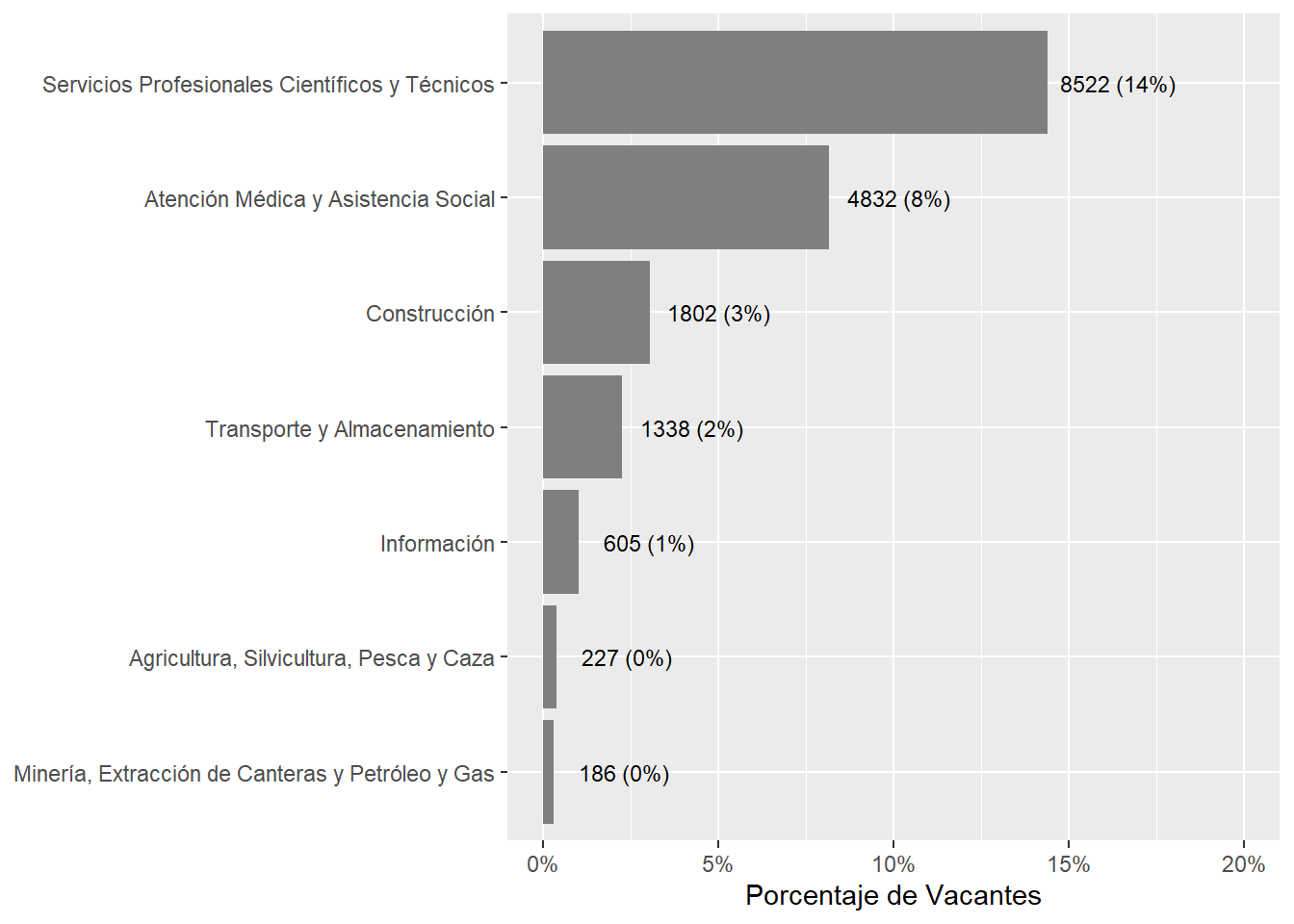
Which country accounts for the largest number of vacancies?
Code
# 10 largestcountry_var_chart(agg_data=rename(filter(rama_df,sector %in% top_10_naics),count=weigths_sum),country ="country_code",category ="sector")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Ten most prevalent sectors in vacancies data",fill=NULL,x=NULL,y=NULL)
Figure 10: ?(caption)
Code
# 10 smallestcountry_var_chart(agg_data=rename(filter(rama_df,sector %in% bottom_10_naics),count=weigths_sum),country ="country_code",category ="sector")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Ten least prevalent sectors in vacancies data",fill=NULL,x=NULL,y=NULL)
abilities_df %>%ggplot(aes(x=reorder(abilities,-group_share),y=group_share))+geom_col(fill="gray50")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(subtitle ="Share of vacancies requiring each Ability to some extent",x=NULL,y=NULL)
Figure 11: ?(caption)
Charts
Code
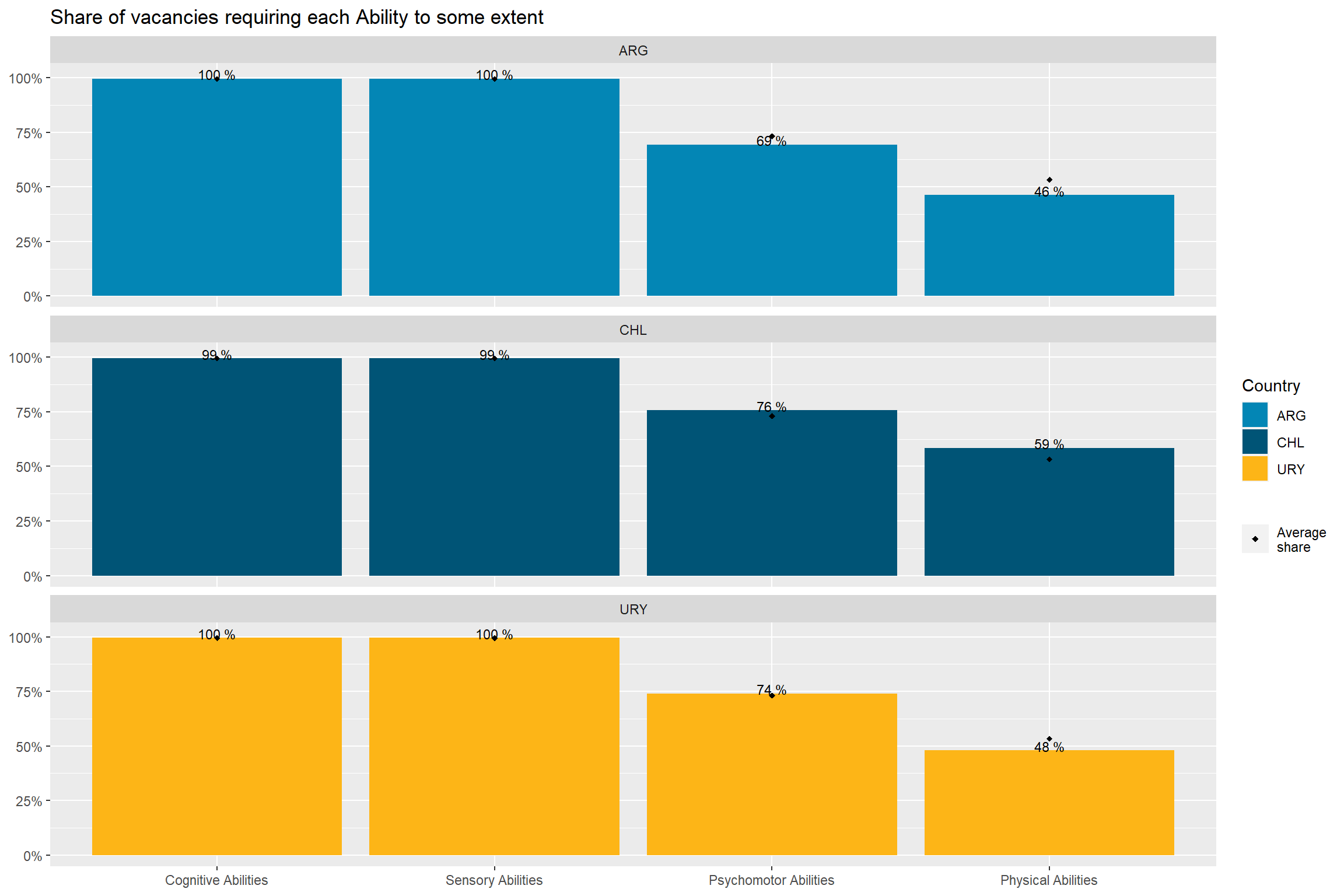
country_var_chart(agg_data=country_abilities_df,country ="country_code",category ="abilities")[[1]]+scale_fill_manual(values=country_colors)+labs(title ="Share of vacancies requiring each Ability to some extent",fill="Country",shape=NULL,x=NULL,y=NULL)
country_var_chart(agg_data=country_abilities_df,country ="country_code",category ="abilities")[[3]]+scale_fill_manual(values=country_colors)+labs(title ="Number of vacancies requiring an Ability, by Country",fill="Country",shape=NULL,x=NULL,y=NULL)
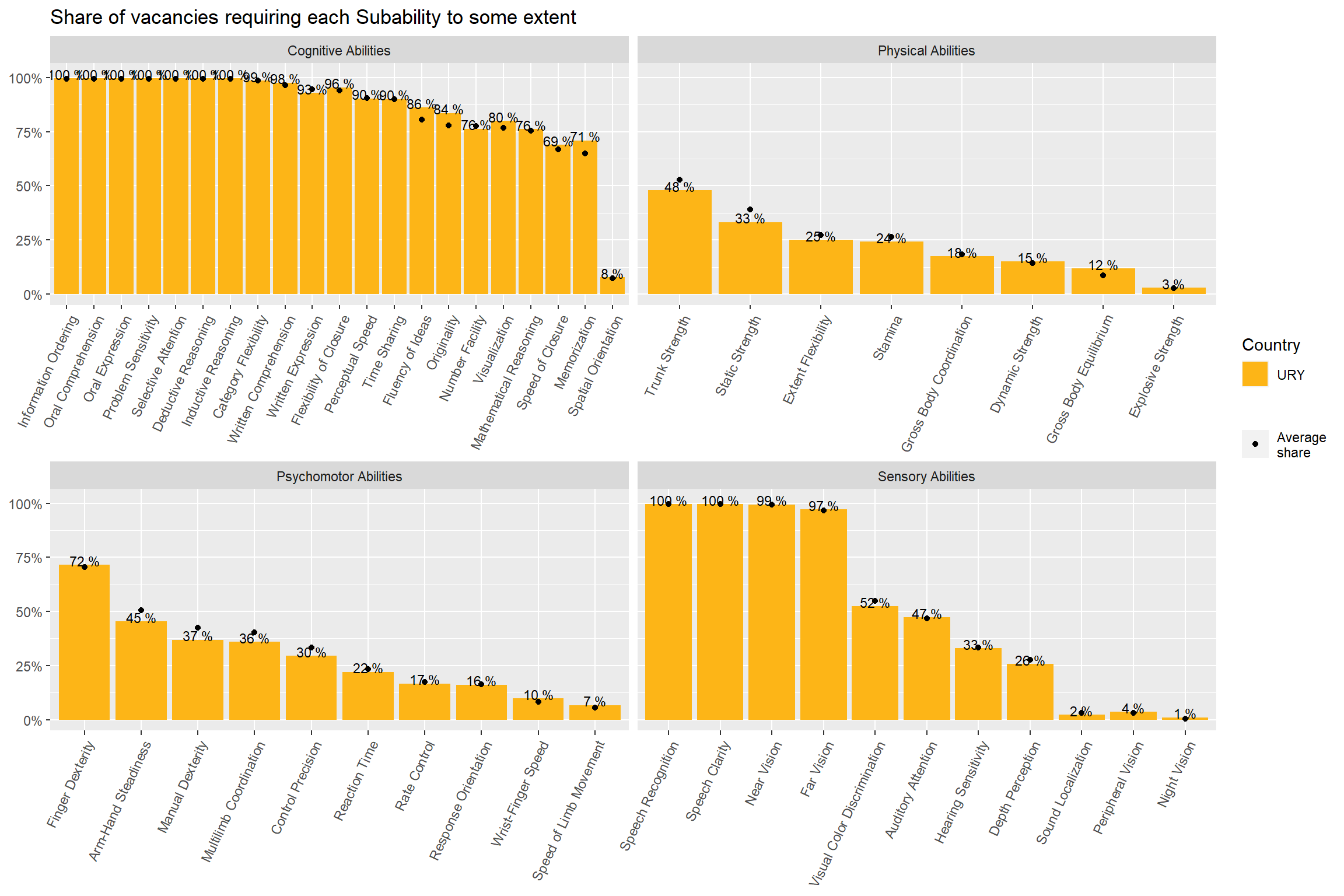
There are 51 Sub Skills but Dynamic_Flexibility is missing from Uruguay. This report shows the remaining 50 until the original data is fixed.
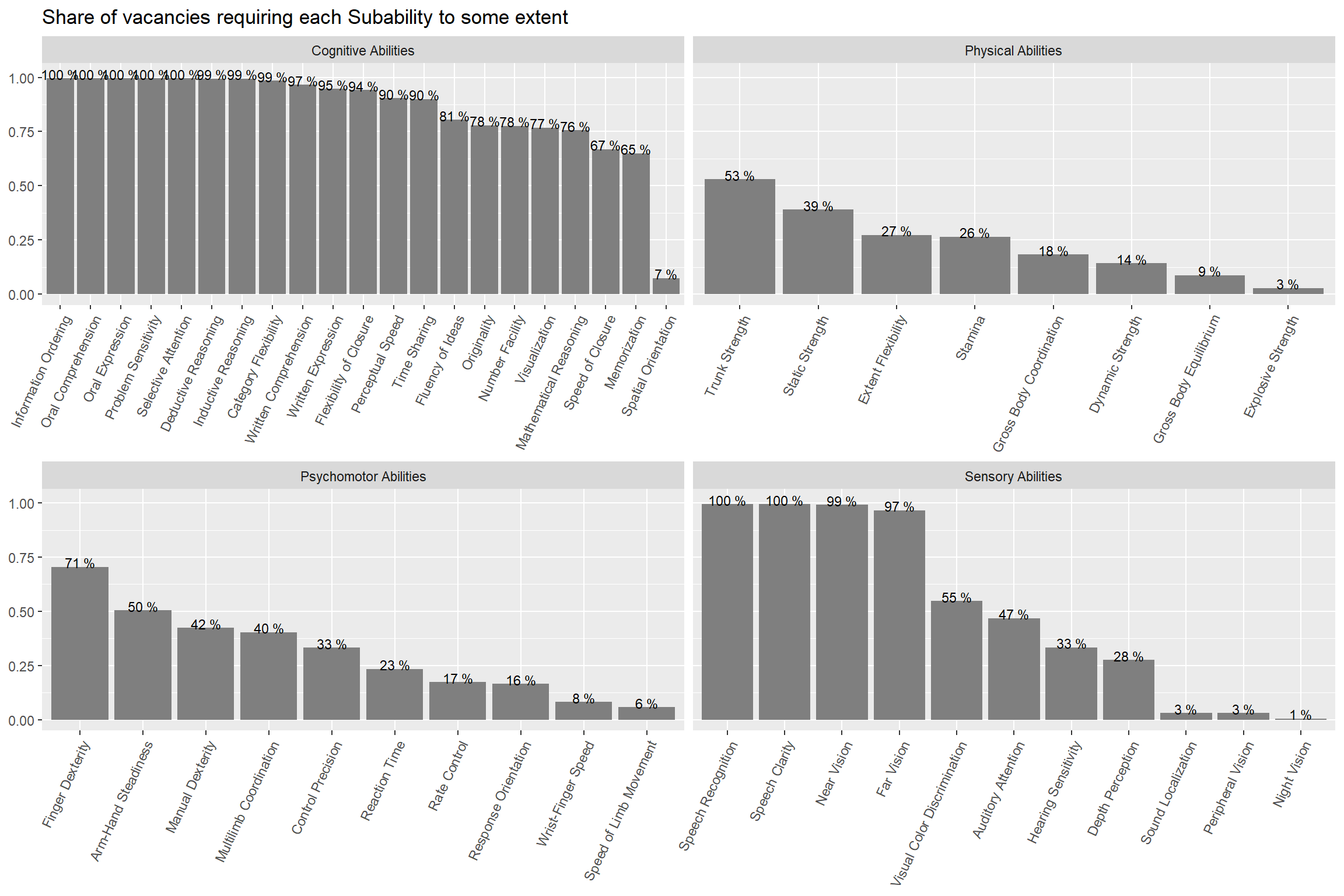
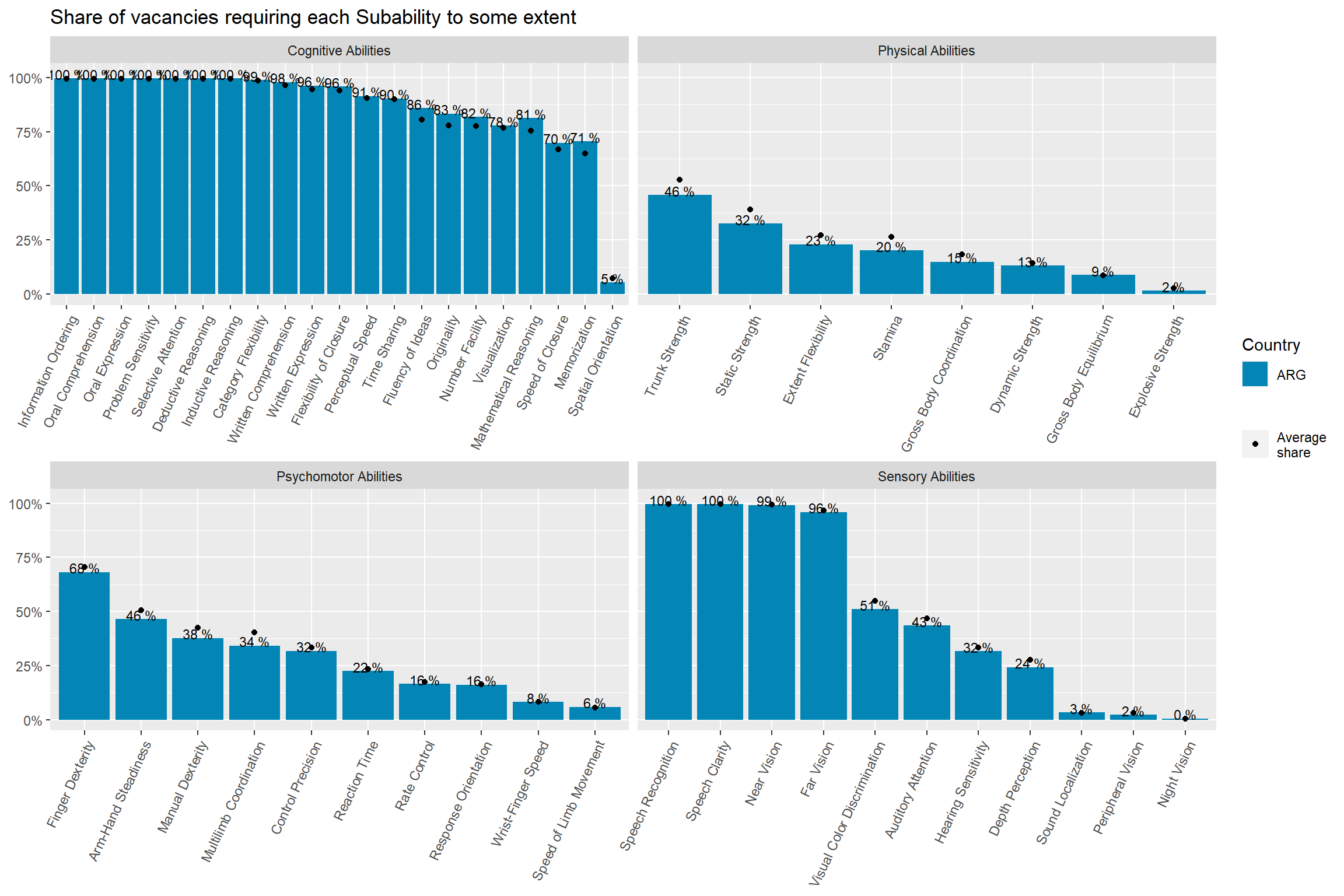
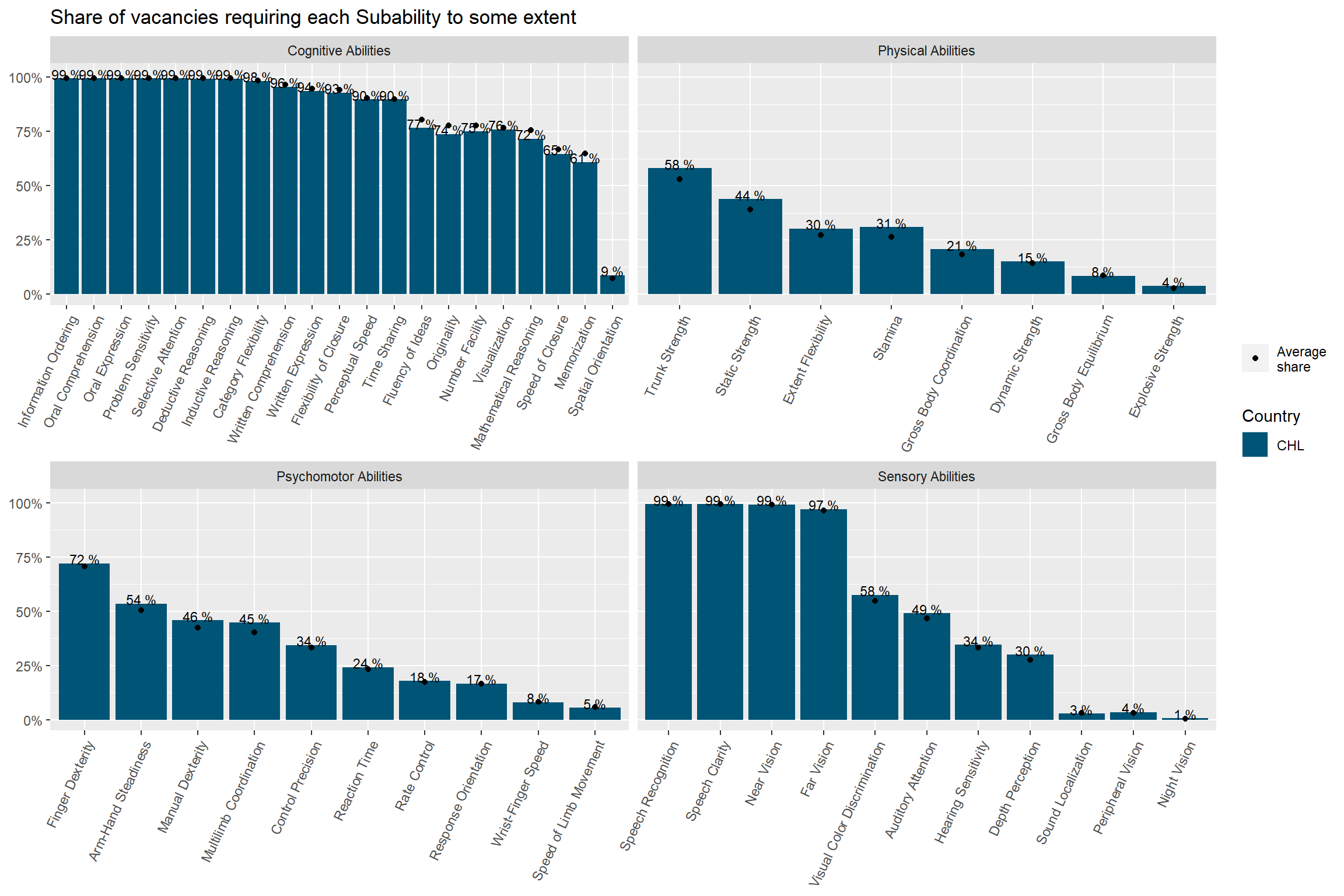
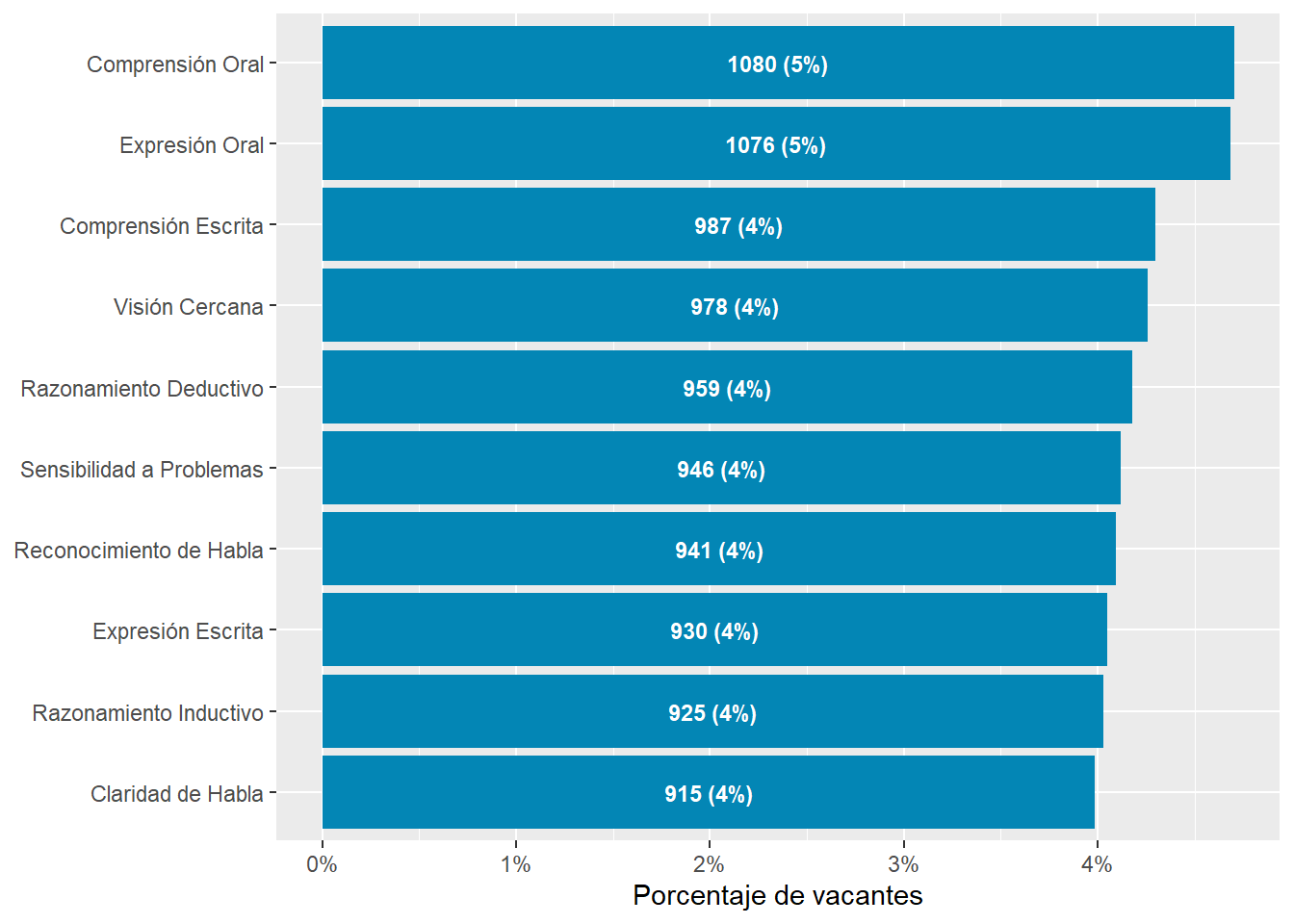
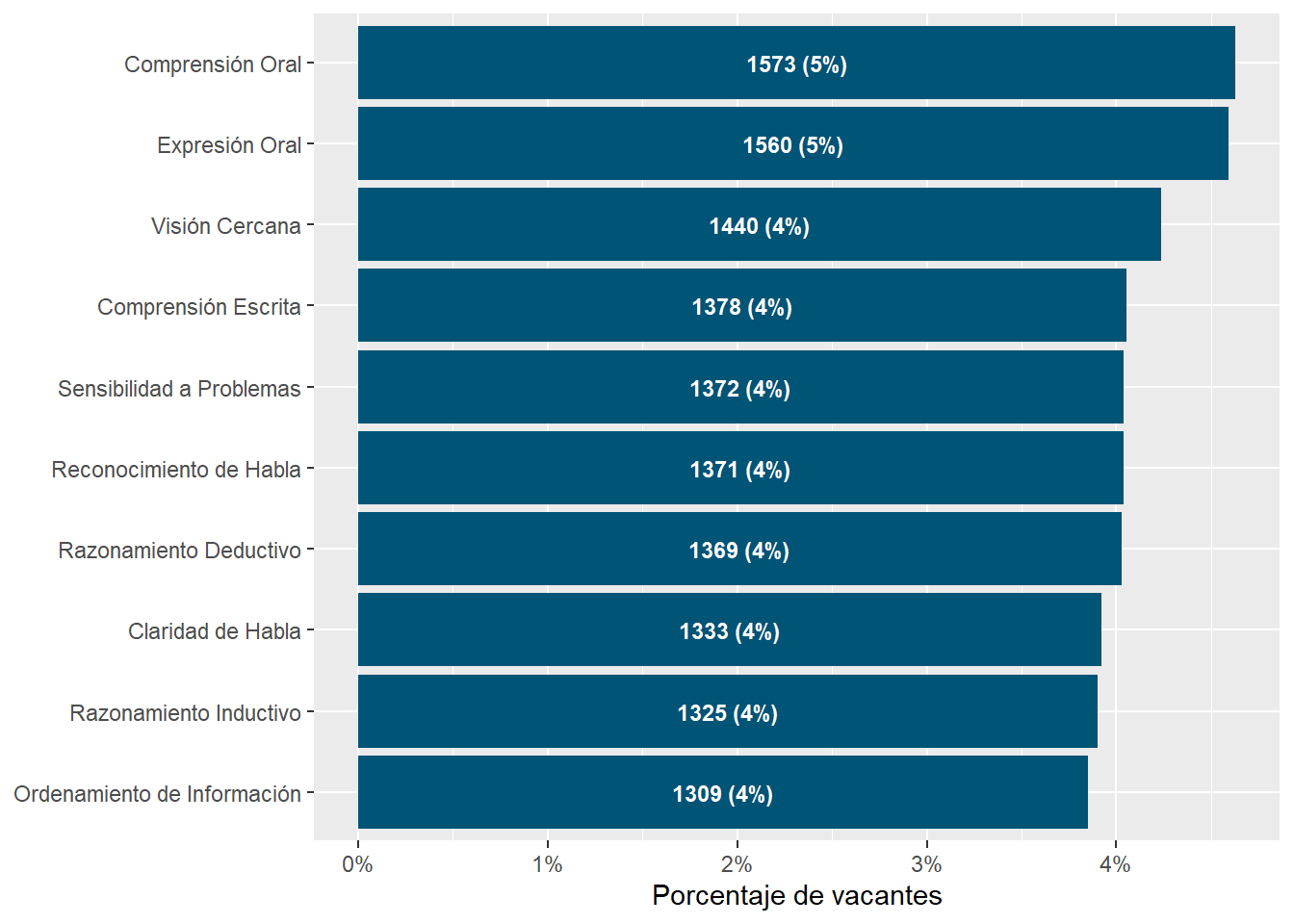
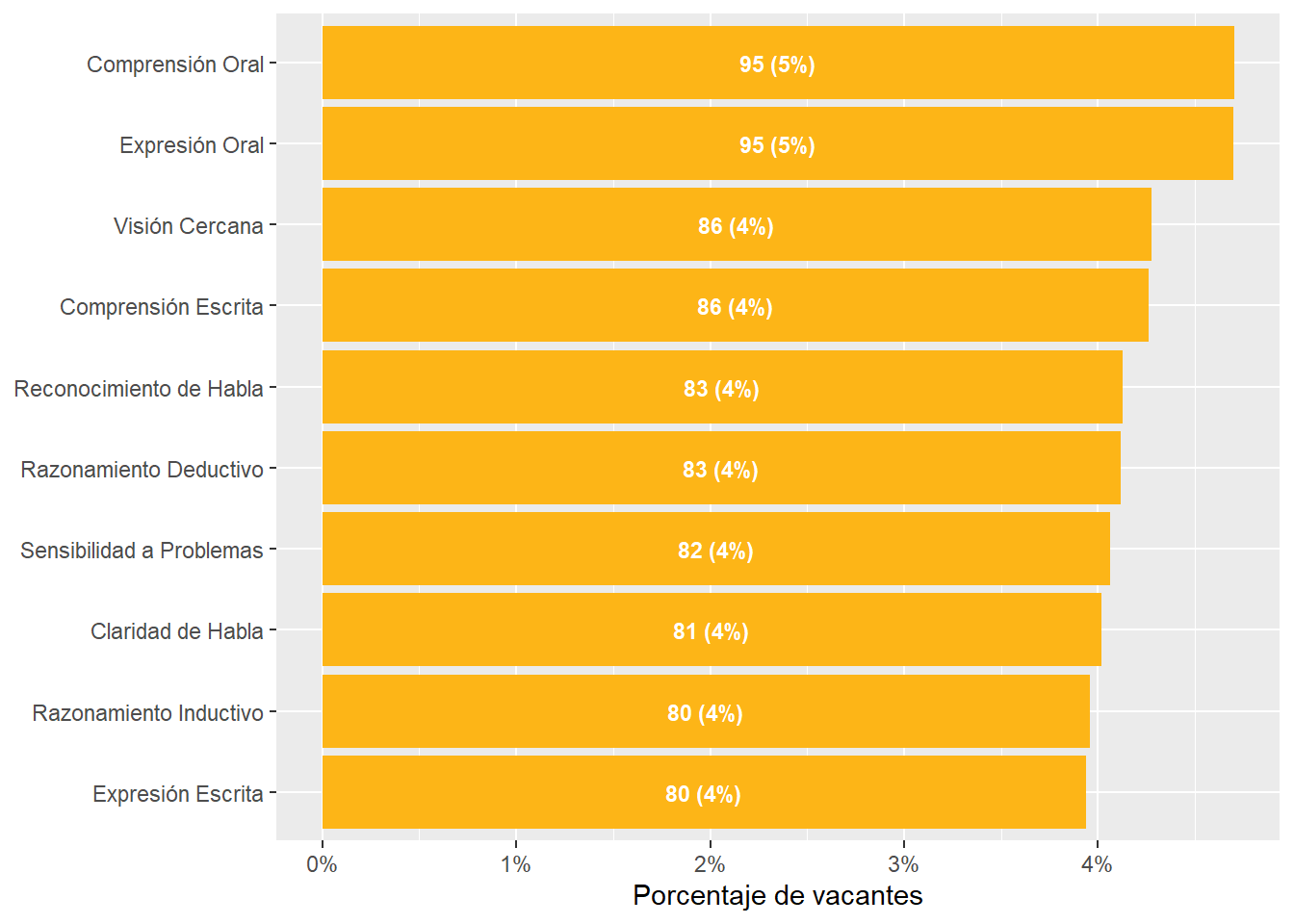
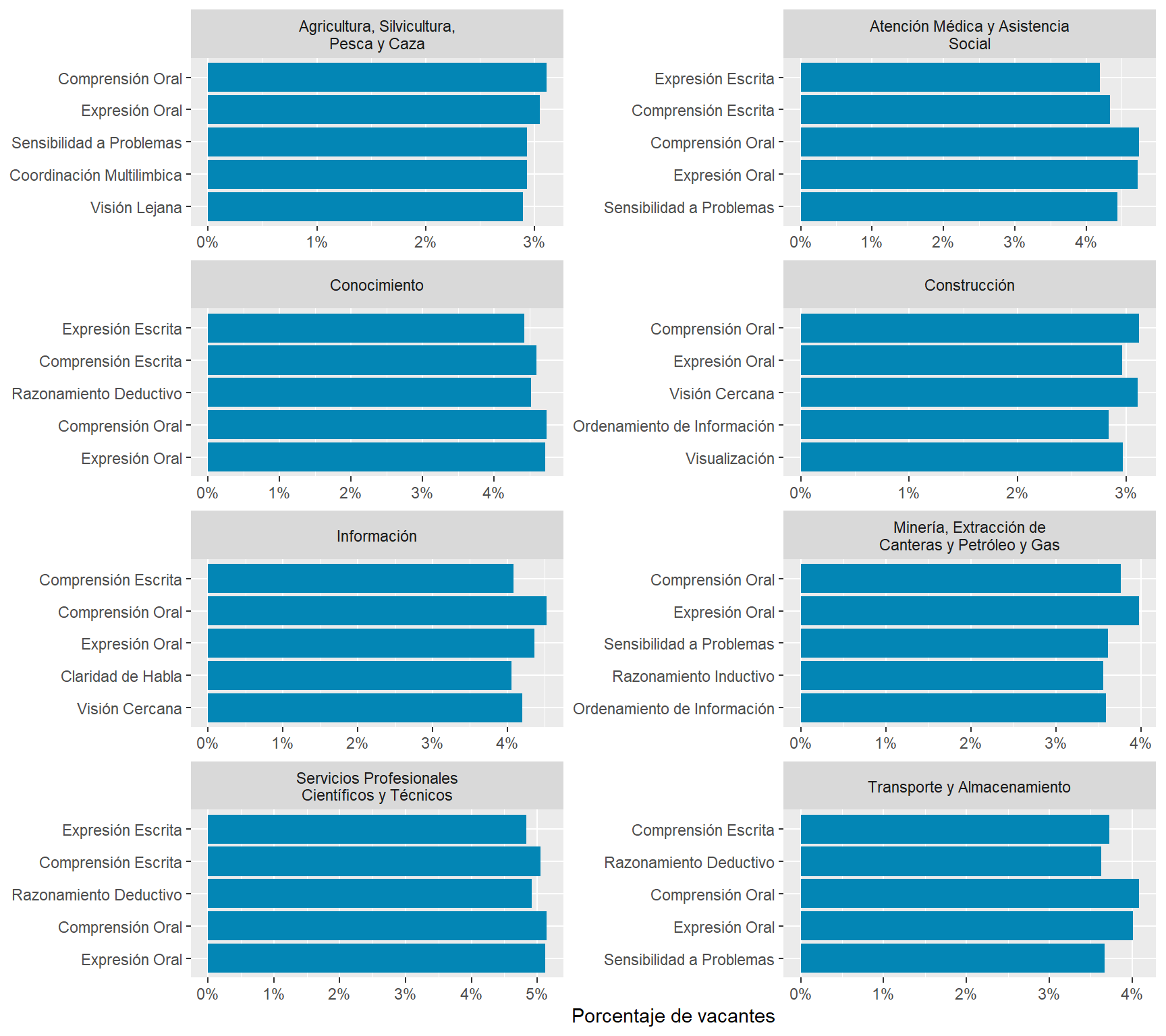
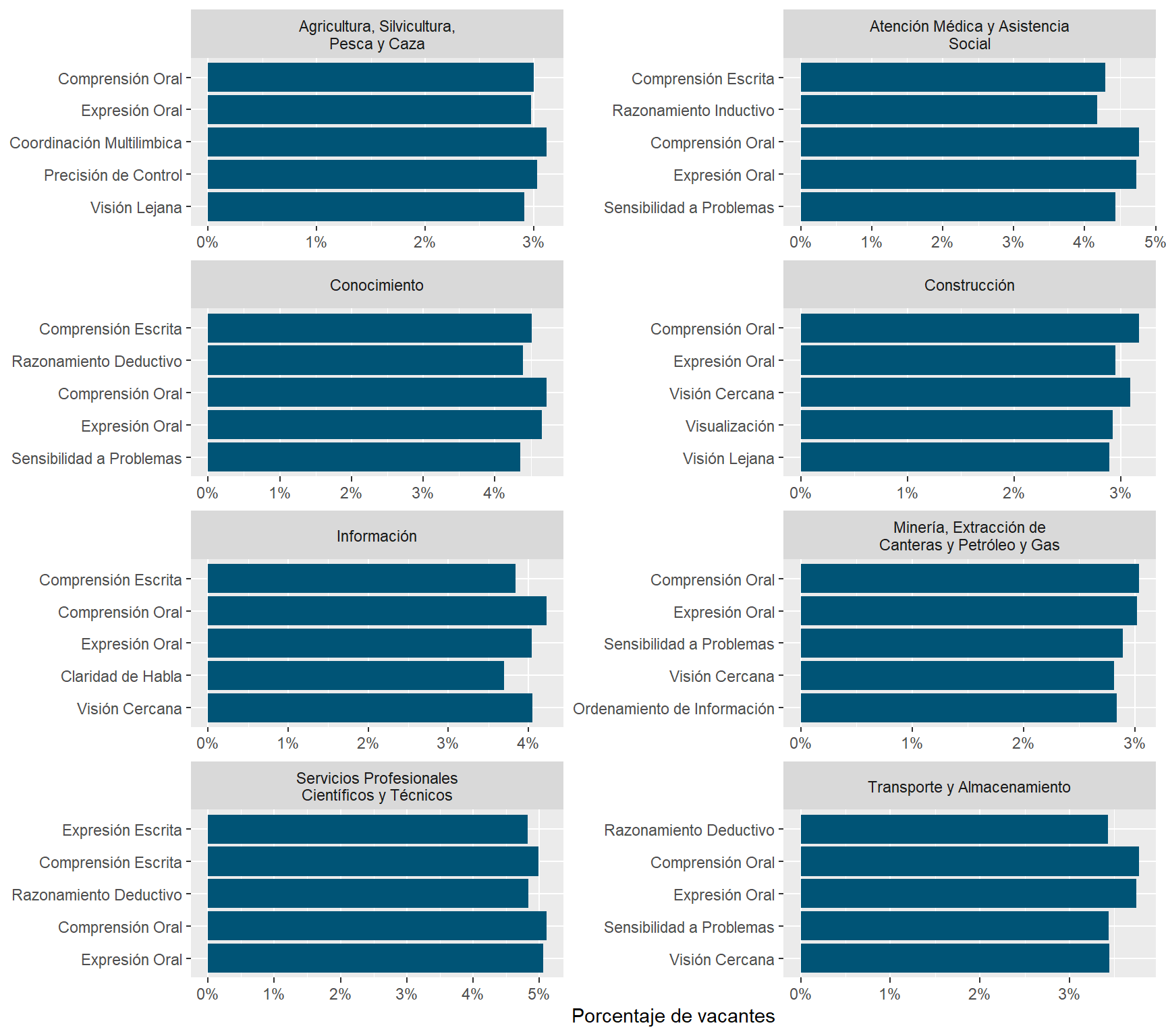
Oral Comprehension and Oral Expression are the most in-demand sub abilities, followed by Near Vision, Written Comprehension, and Deductive Reasoning. Argentina and Uruguay demand this skills with a higher intensity than Chile.
Number facility and Mathematical Reasoning rank 21th and 22th in the ranking of most demanded sub abilities. Argentina and Uruguay demand this skills with a higher intensity than Chile.
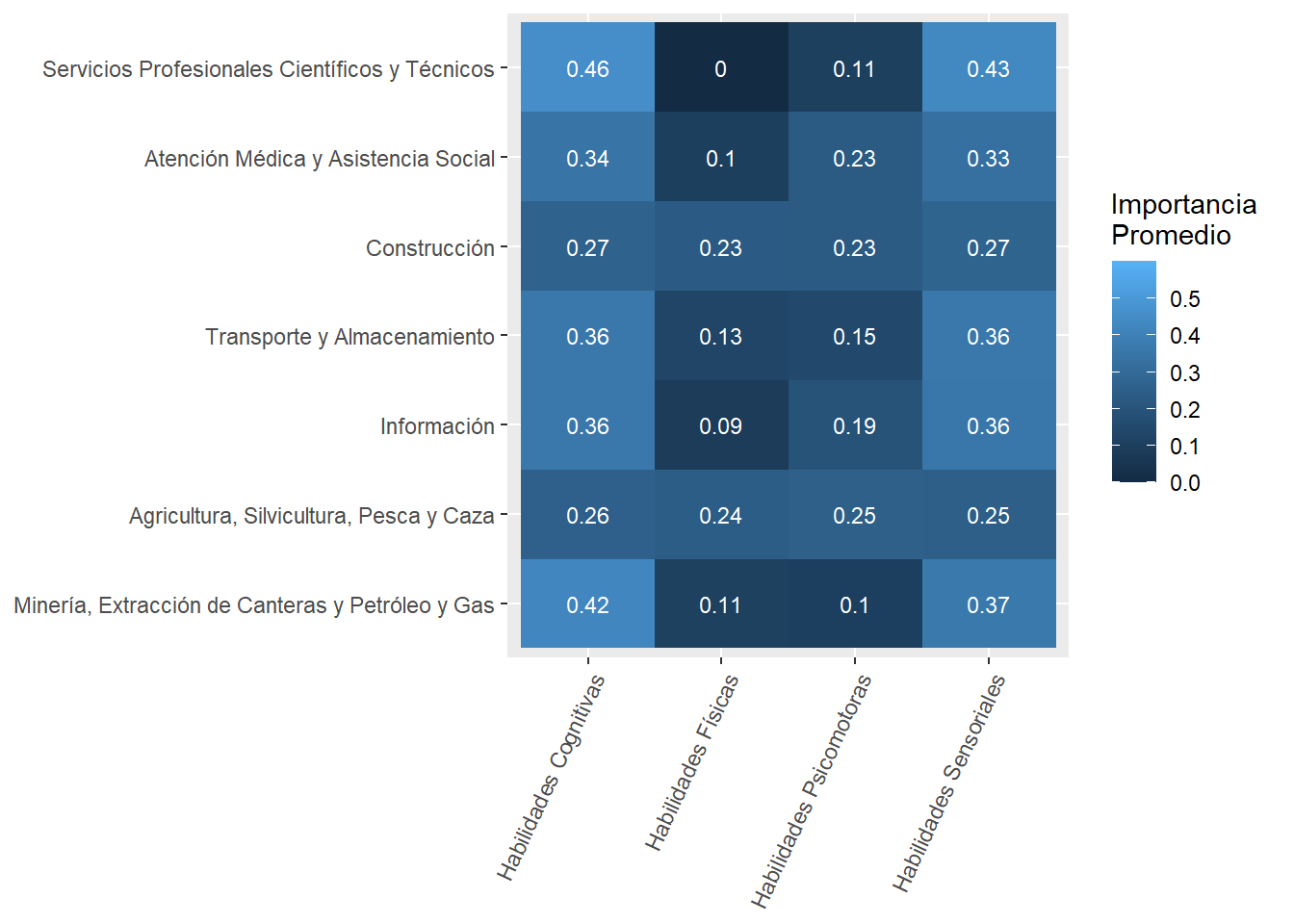
We compared the prevalence of sub-abilites job postings contrasted it what O*NET experts think are the typical importance and mastery levels of each skill within an occupation. We got a strong positive correlation, which suggests our text mining algorithms were able to capture some of the knowledge occupational experts have.
subabilities_df %>%ggplot(aes(x=reorder(subabilities,-group_share),y=group_share))+geom_col(fill="gray50")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+facet_wrap(vars(ability),scales ="free_x")+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies requiring each Subability to some extent",x=NULL,y=NULL)
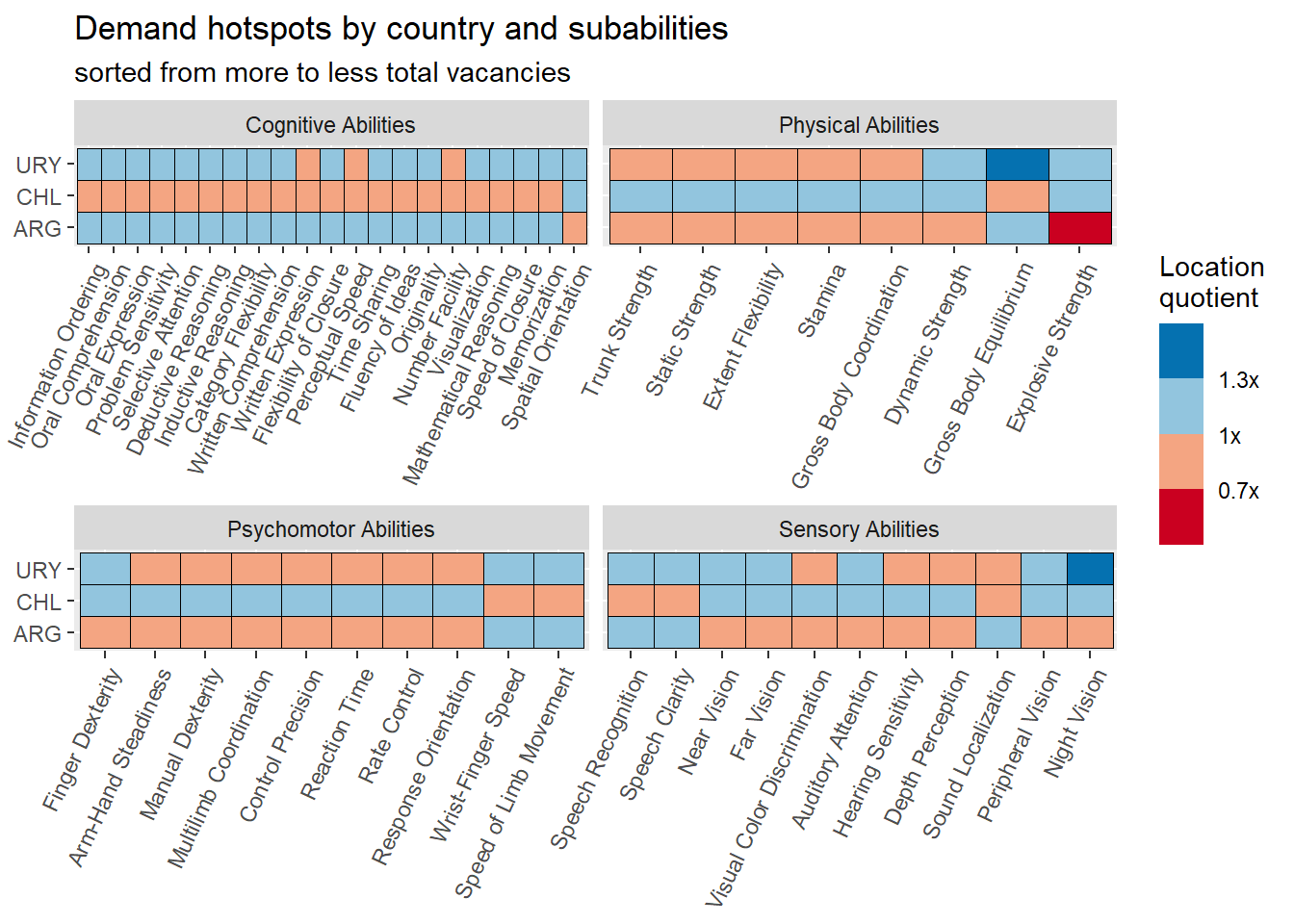
country_subabilities_df %>%ggplot(aes(x=reorder(subabilities,-group_share ),y=country_code, fill=group_in_country_share /group_share ))+geom_tile(color="black")+theme(axis.text.x =element_text(angle =65, hjust=1))+scale_fill_fermenter(palette ="RdBu",direction =1, breaks=c(0.35,0.7,1,1.3),labels =function(x) paste0( x, 'x'))+facet_wrap(vars(ability),scales ="free_x")+labs(title ="Demand hotspots by country and subabilities",subtitle ="sorted from more to less total vacancies",fill="Location\nquotient",y=NULL,x=NULL)
Code
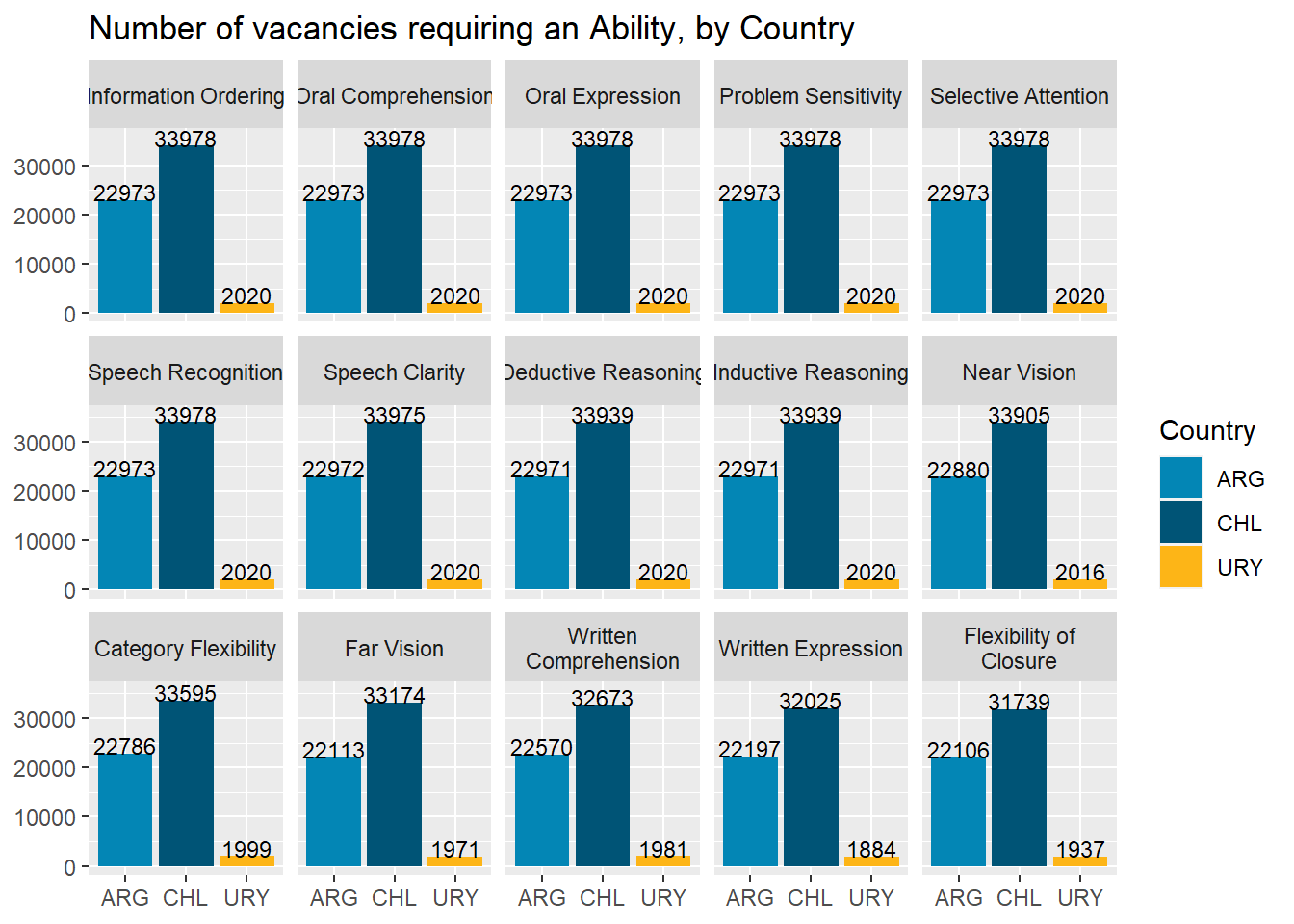
top_subabilities<-subabilities_df %>%top_n(15, group_share) %>%pull(subabilities)country_var_chart(agg_data=filter(country_subabilities_df,subabilities %in% top_subabilities),country ="country_code",category ="subabilities")[[3]]+scale_fill_manual(values=country_colors)+labs(title ="Number of vacancies requiring an Ability, by Country",fill="Country",shape=NULL,x=NULL,y=NULL)
As we said before, sectors and sub-skills aren’t discretely assign to each online vacancies. Instead, each sector and skill has a weight on each job vacancy associated with the chances the firm belongs to that sector (or demands that skill).
To offer a tractable measure of the skills demand by sector we’re simply going to assign a 1 to the sector with the maximum chances of being the vacancy’s sector. Then we either count the number of times an ability (or subability) is required by a vacancy in the chosen sectors, or their average importance within the latter.
Another way is just counting the percentage of all postings within a country in which both the skill and the sector had a higher than average weight. We’ll try different specifications and use the most satisfactory one in the final deliverable.
This is the frequency in which each sectors is a vacancy’s most-likely sector:
mainsector_abilities_df<-country_var_count_groups(data=south_cone_df,country ='main_sector',variable_names=abilities, name_of_categories="abilities") %>%mutate(abilities=str_replace_all(abilities,"_"," "),abilities=str_to_title(abilities),abilities=str_replace_all(abilities," Of "," of ")) sector_skills_matrix(data_agg = mainsector_abilities_df,ability_val =NULL,metric ="mean")
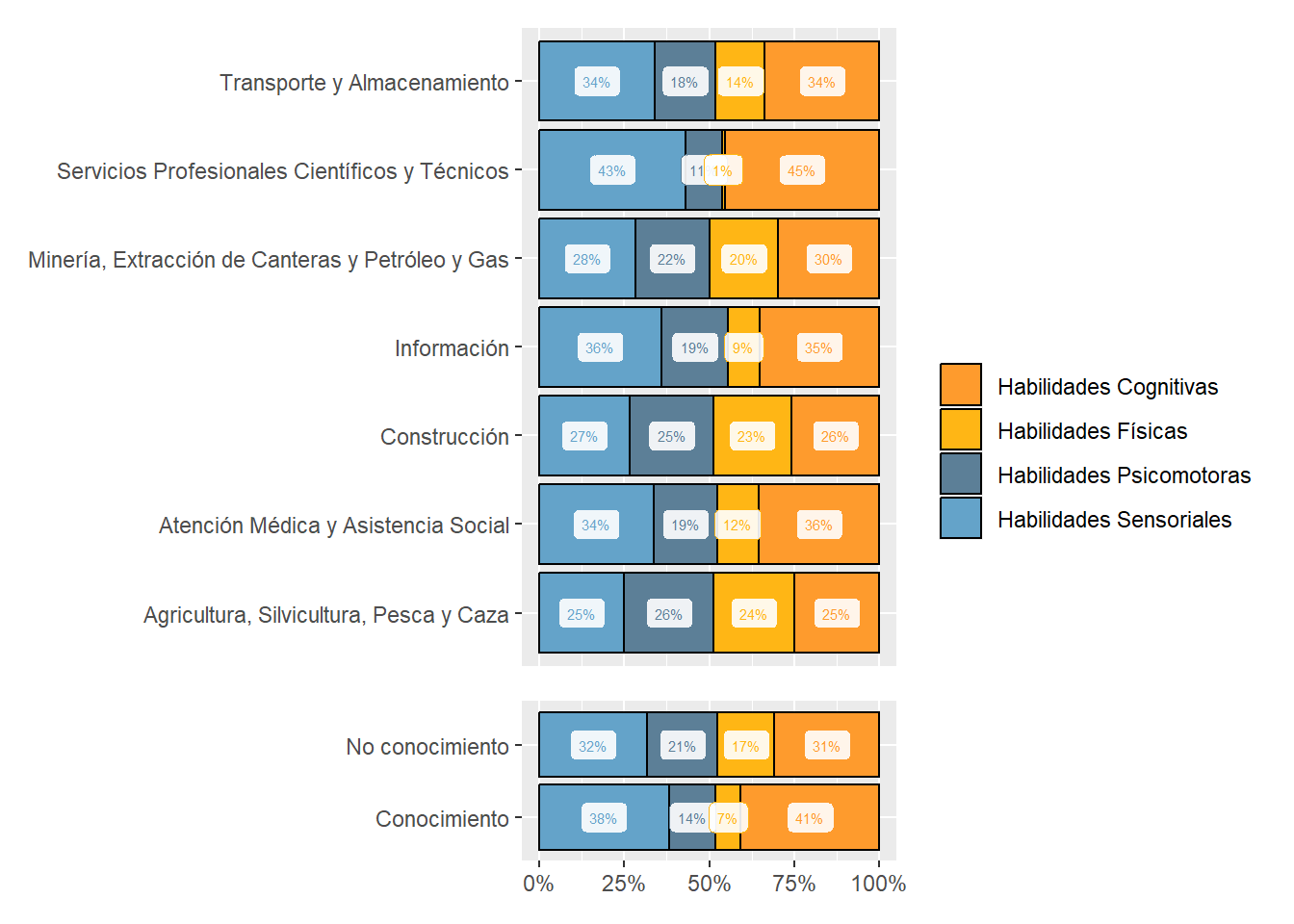
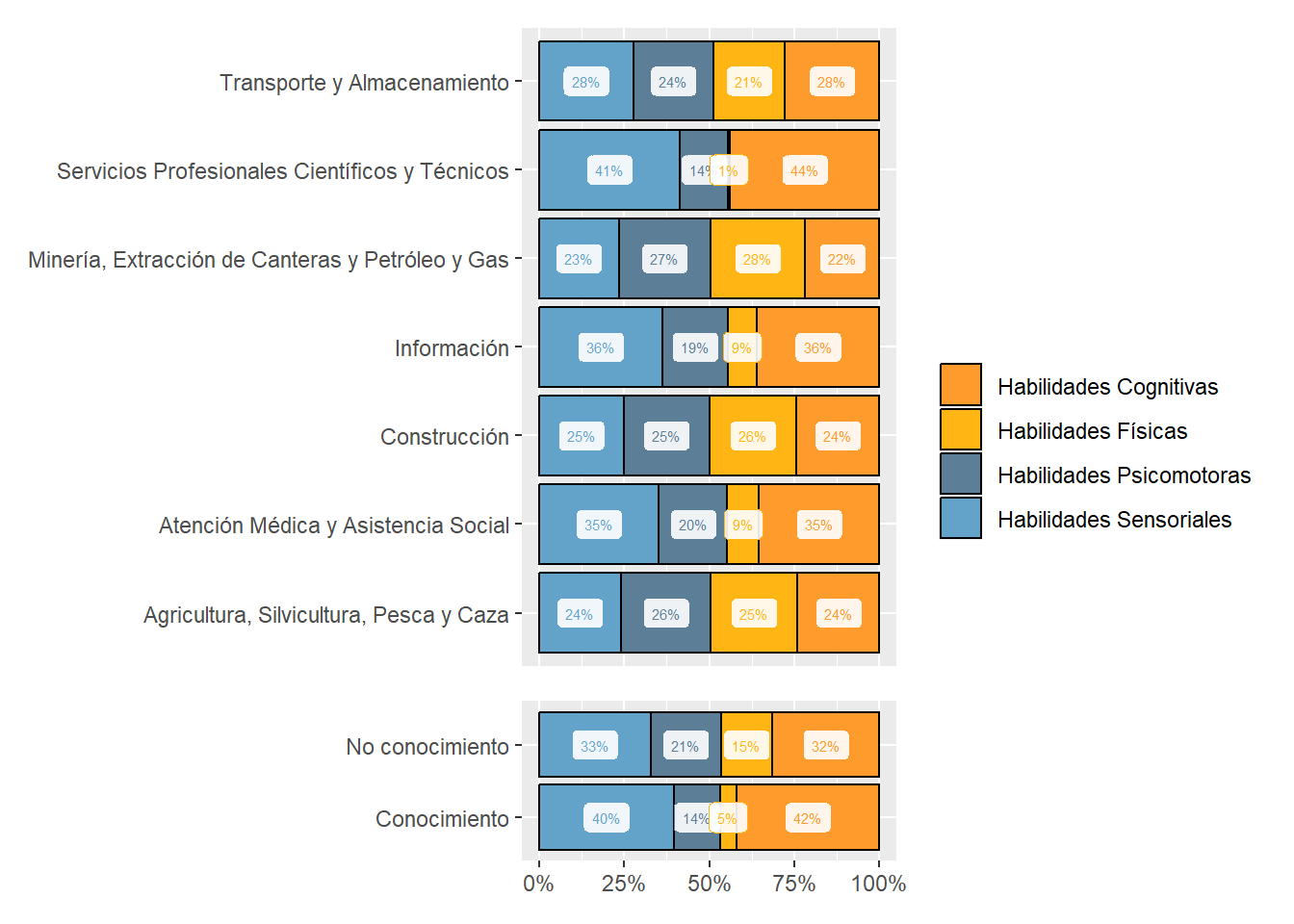
Figure 18: Subabilities by sector
Code
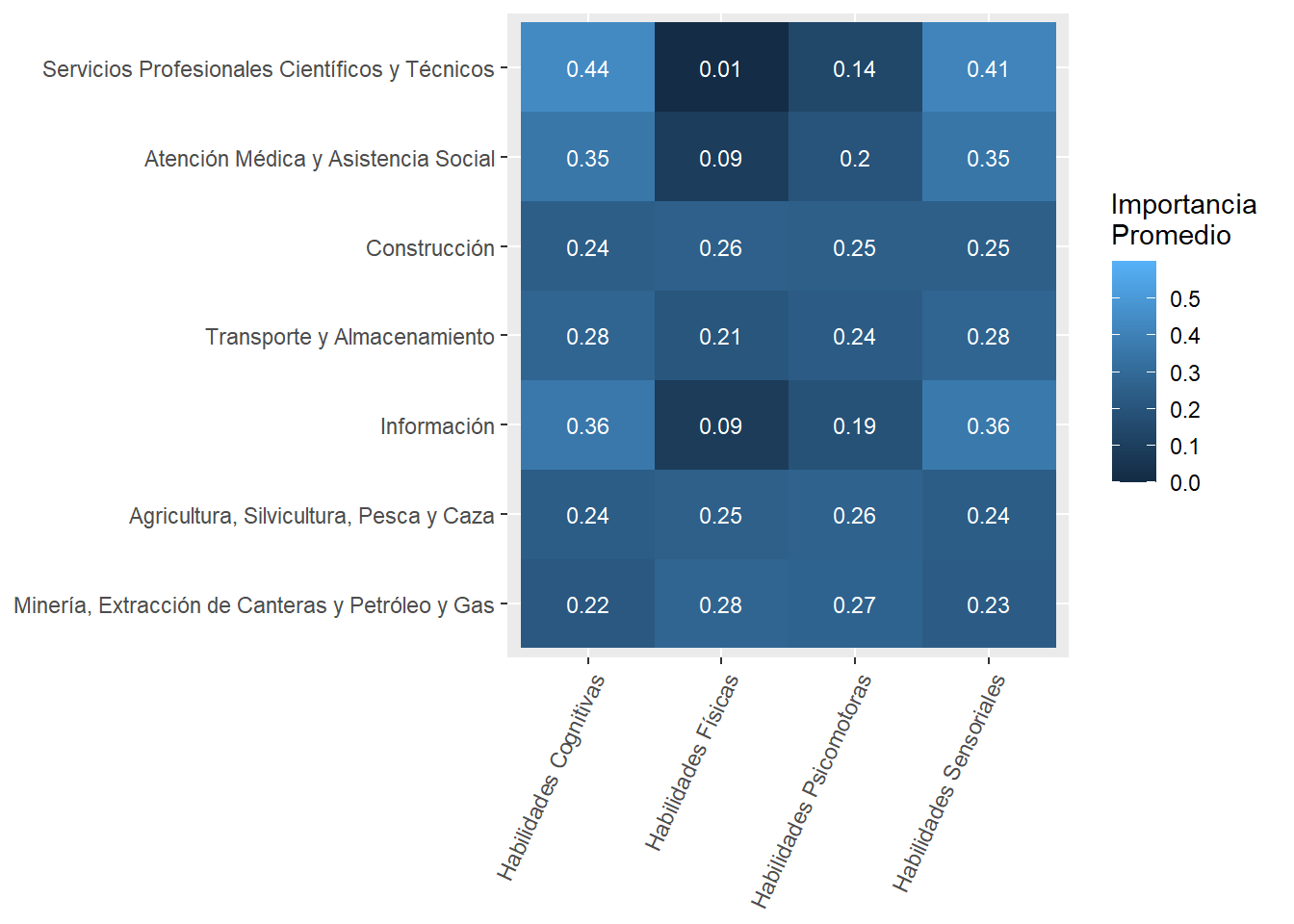
mainsector_subabilities_df<-country_var_count_groups(data=south_cone_df,country ='main_sector',variable_names=subabilities, name_of_categories="subabilities") %>%mutate(subabilities=str_replace_all(subabilities,"_"," "),subabilities=str_to_title(subabilities),subabilities=str_replace_all(subabilities," Of "," of ")) %>%left_join(abilities_taxonomy)purrr::map(c("Cognitive Abilities","Psychomotor Abilities","Physical Abilities","Sensory Abilities"), sector_skills_matrix,data_agg=mainsector_subabilities_df,metric="mean")
[[1]]
[[2]]
[[3]]
[[4]]
Job zones
41% of job vacancies in the South Cone require “(2) Some preparation”, while 25% require “(4) Considerable preparation”, and another 25% requires “(3) Middle preparation”. Only 8% of the demand is focused on the “(1) no preparation” and “(5) a lot of preparation” extremes.
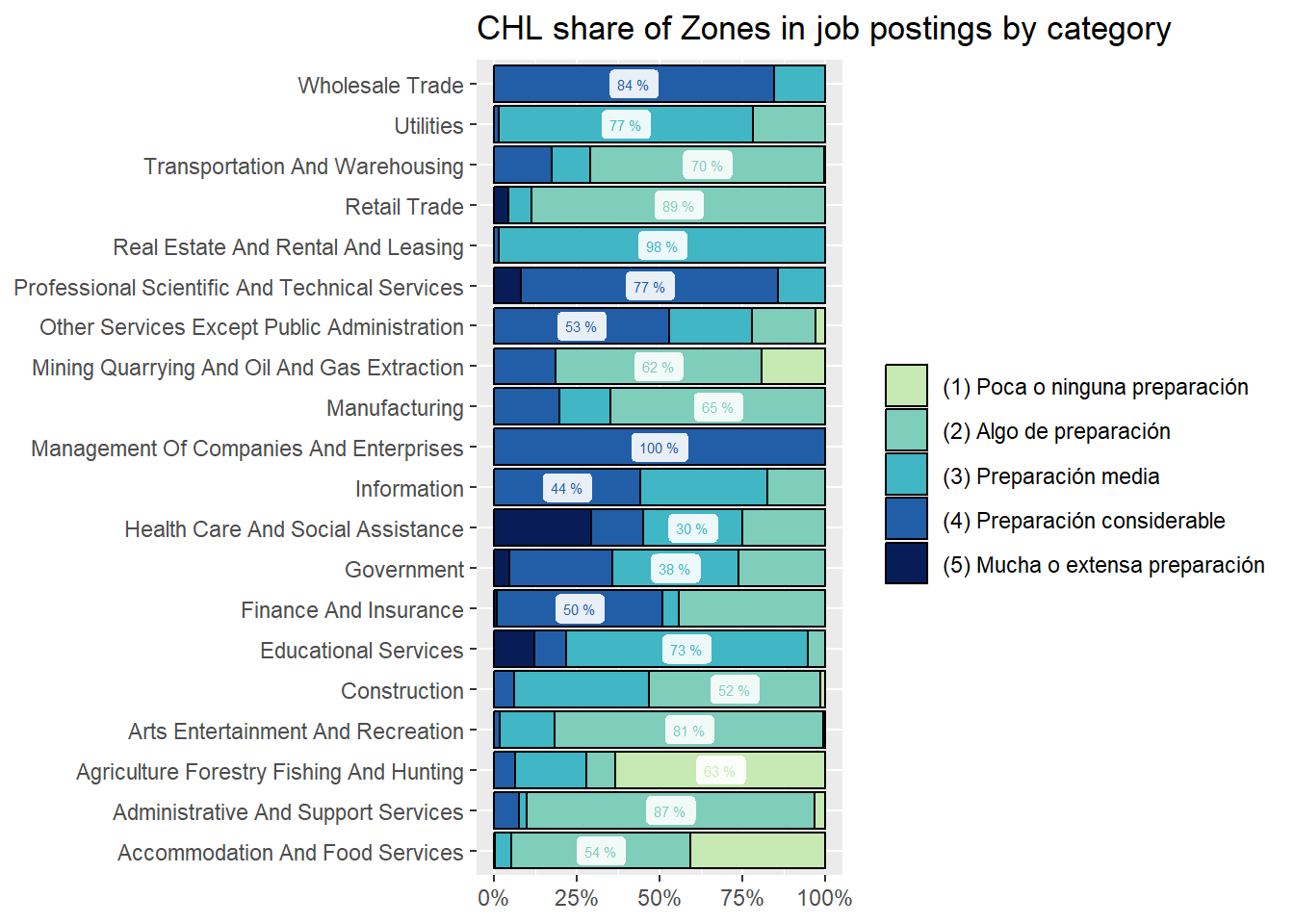
46% of job postings in Chile demand “(2) Some preparation”. It’s the country most concentrated in that area of demand by a considerable margin.
30.5% of job postings in Argentina demand “(4) Considerable preparation”. It’s the country most concentrated in that area of demand by a moderate margin.
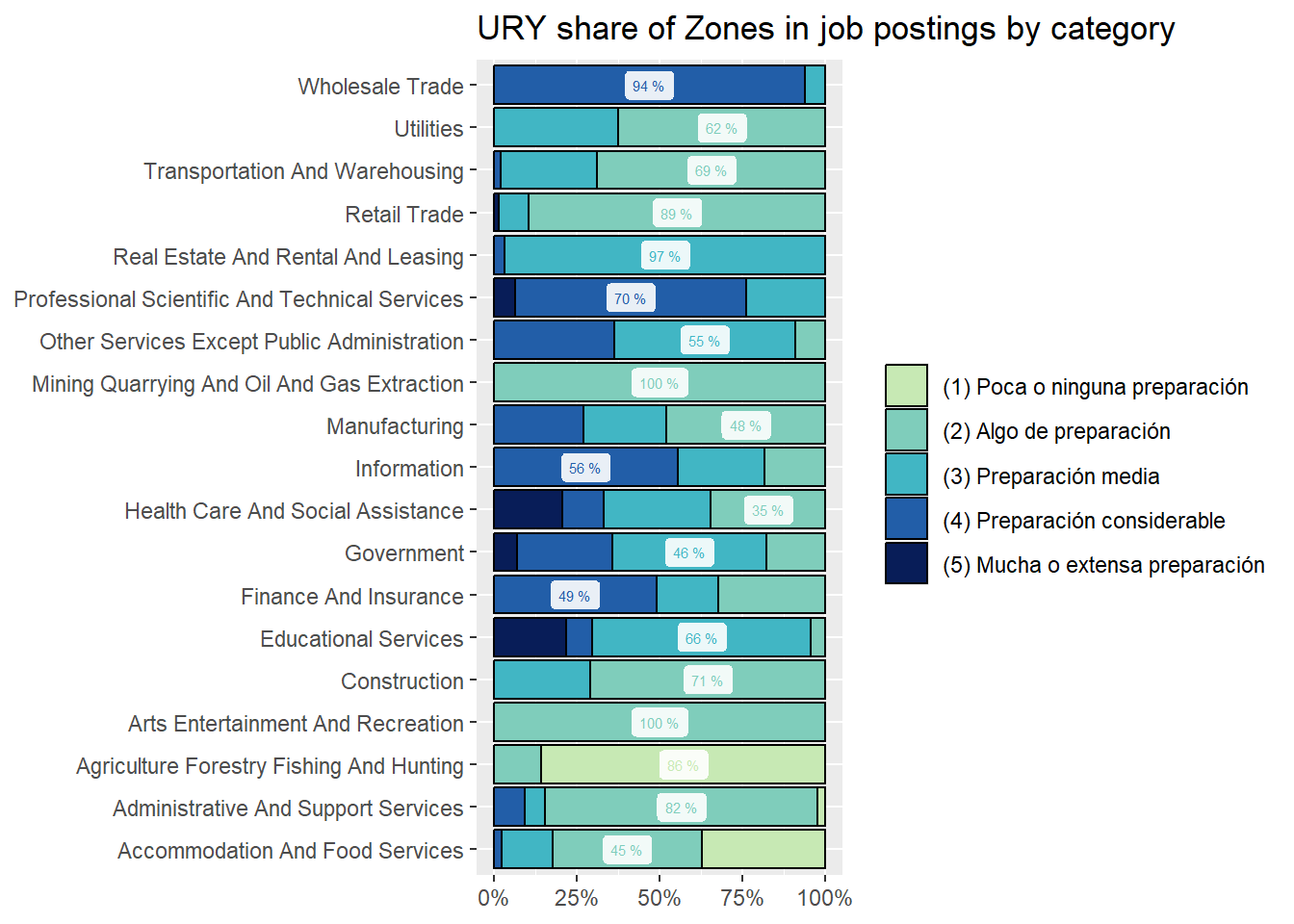
29.6% of job postings in Uruguay demand “(3) Middle preparation”. It’s the country most concentrated in that area of demand by a moderate margin.
Code
zones_df<-country_var_count(data = south_cone_df,category ="zones_label",country=NULL)zones_country_df<-country_var_count(data = south_cone_df,category ="zones_label",country="country_code")zones_df %>%ggplot(aes(x=zones_label,y=group_share))+geom_col(fill="gray50")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by Zone",x=NULL,y=NULL)
country_var_chart(zones_country_df,country ="country_code",category ="zones_label")[[1]]+scale_fill_manual(values=country_colors)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by zone",subtitle ="Only showing 20 most common",fill="Country",shape=NULL,x=NULL,y=NULL)
Figure 23: Jobzones
Code
country_var_chart(zones_country_df,country ="country_code",category ="zones_label")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Job zones distribution in online vacancies data",x=NULL,fill=NULL,fill=NULL)
Code
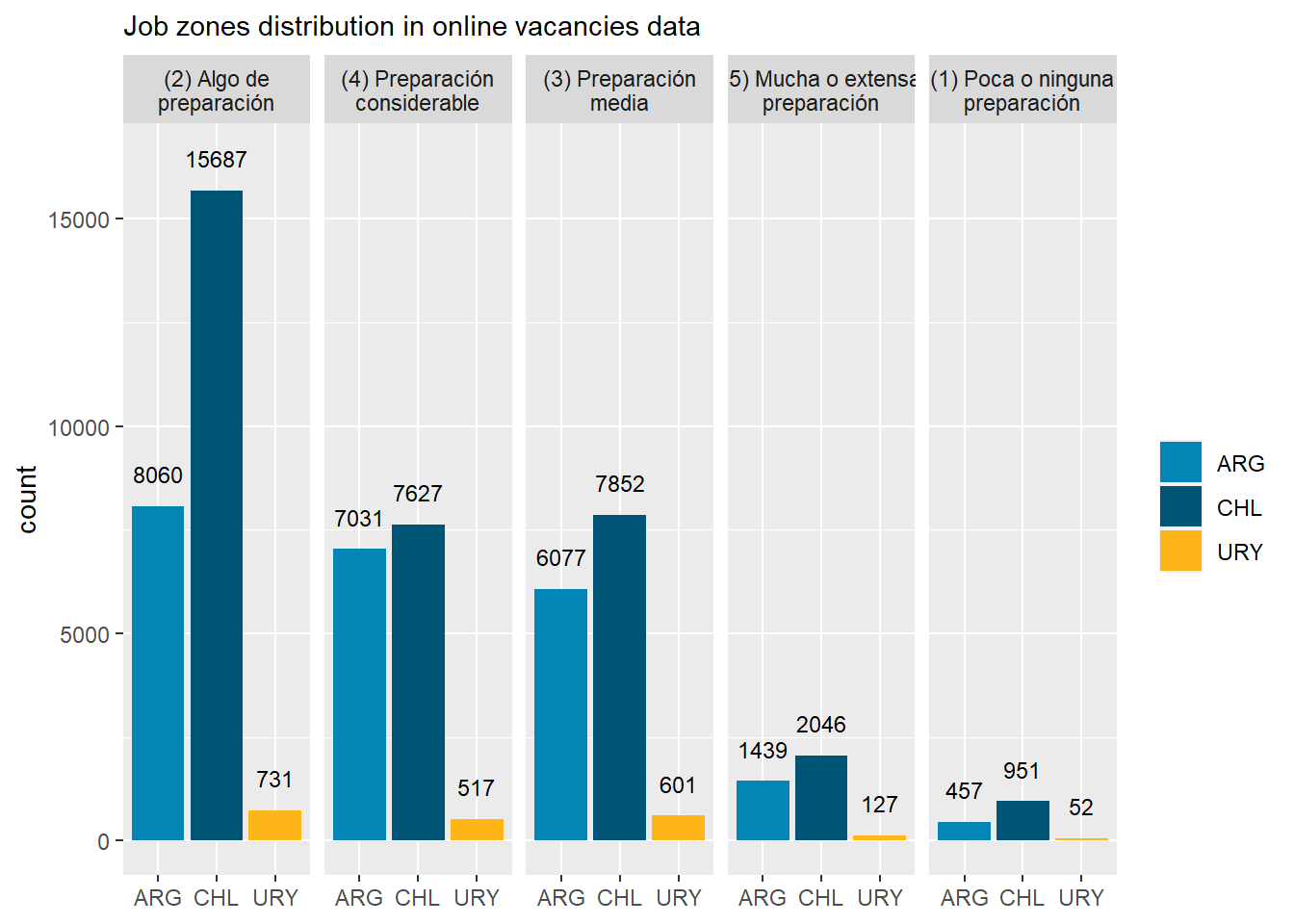
country_var_chart(zones_country_df,country ="country_code",category ="zones_label")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Job zones distribution in online vacancies data",x=NULL,fill=NULL,fill=NULL)
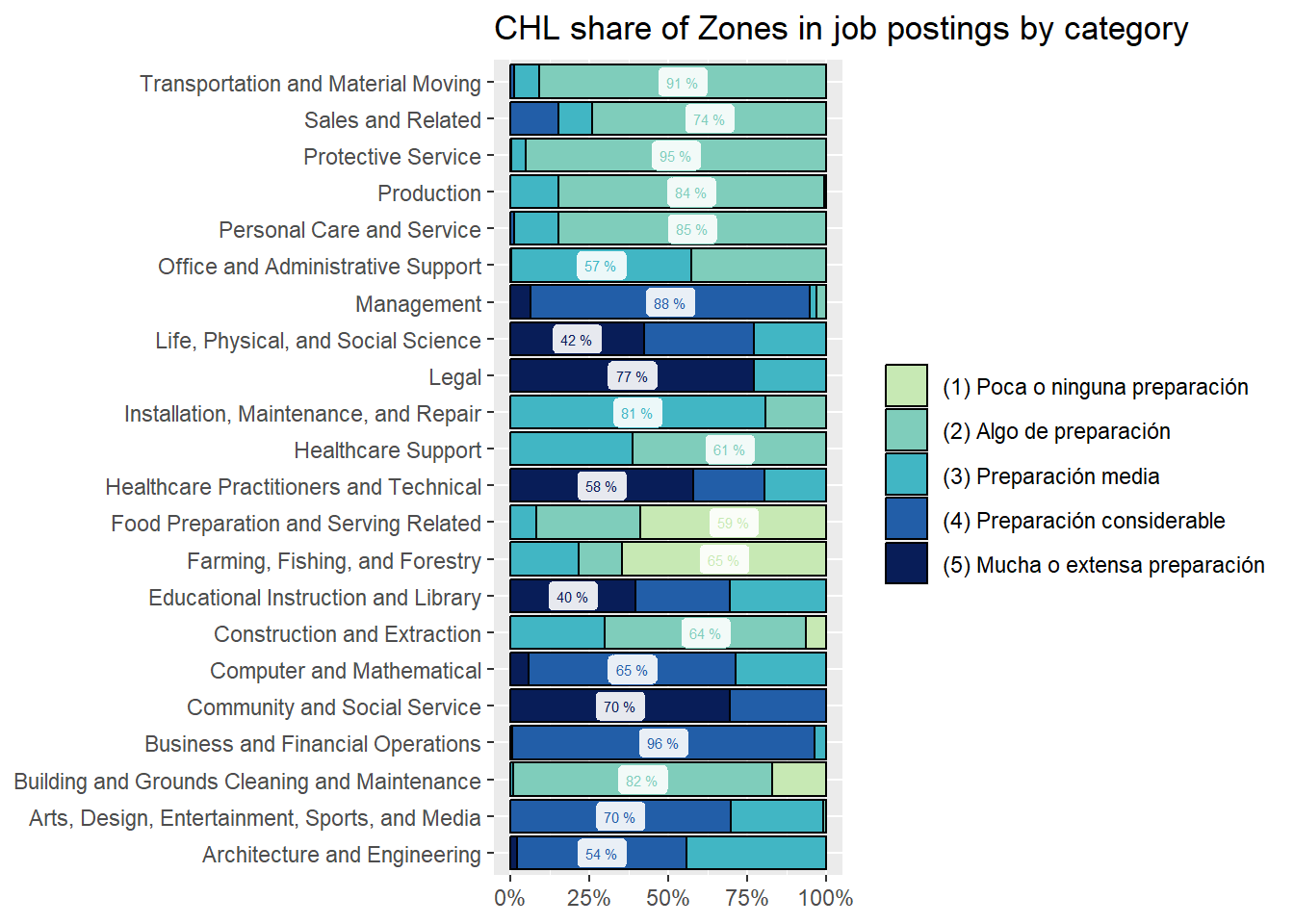
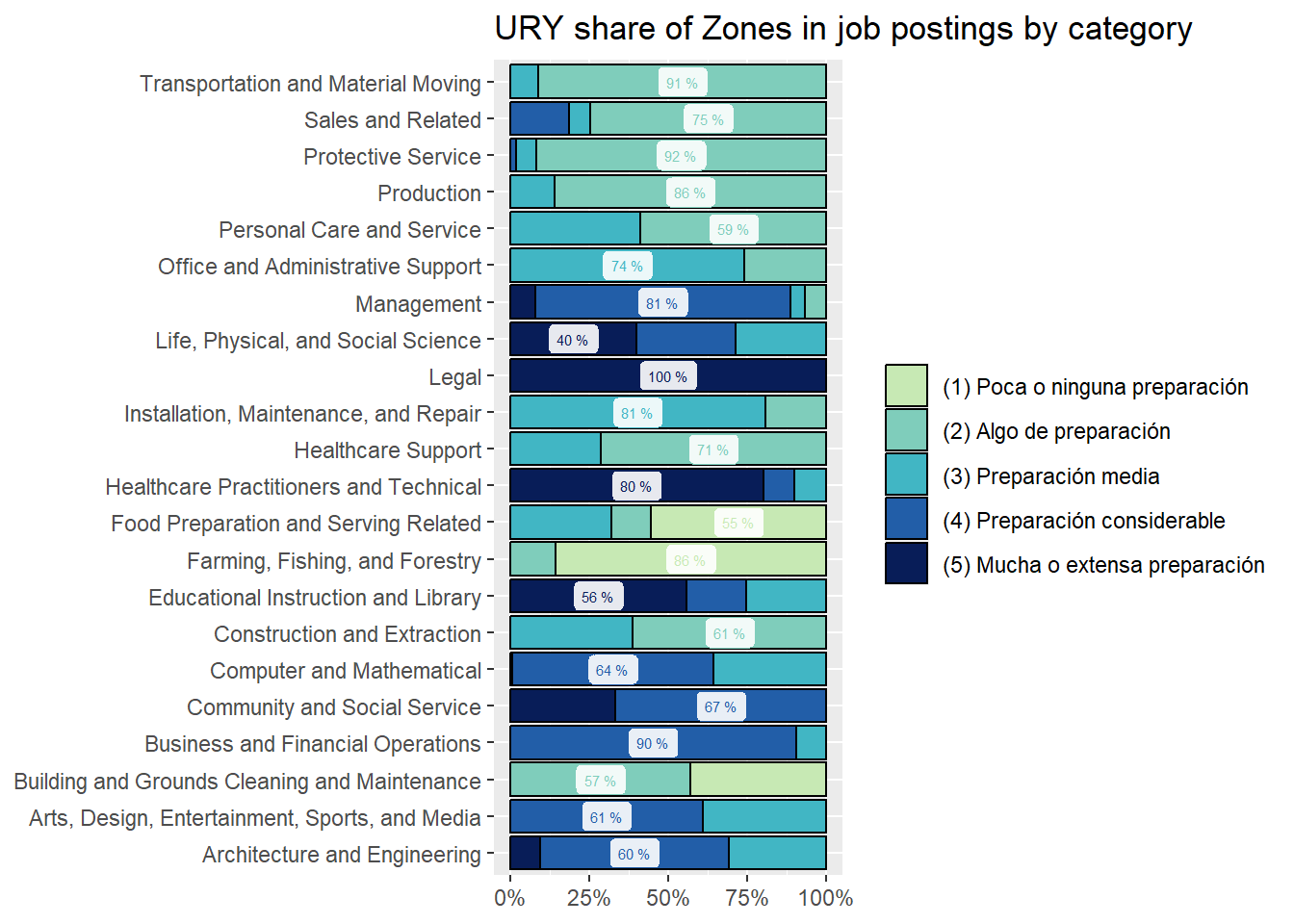
zones_sector_df<-country_var_count(south_cone_df,category ="zones_label",country="main_sector")zones_sector_df %>%ggplot(aes(x=main_sector,y=group_in_country_share))+geom_col(aes(fill=zones_label),position ="fill", color="black")+geom_label(data=group_by(zones_sector_df,main_sector) %>%mutate(label_y=ifelse(group_in_country_share==max(group_in_country_share),paste(round(group_in_country_share,2)*100,"%"),NA)),aes(label=label_y, color=zones_label),alpha=.9, size=2, position =position_fill(vjust =0.5), show.legend =FALSE)+coord_flip()+scale_y_continuous(labels = scales::percent_format())+scale_fill_manual(values=RColorBrewer::brewer.pal(9,"YlGnBu")[c(3,4,5,7,9)])+scale_color_manual(values=RColorBrewer::brewer.pal(9,"YlGnBu")[c(3,4,5,7,9)])+labs(title ="Share of Zones in job postings by Main Sector",fill=NULL,color=NULL,y=NULL,x=NULL)
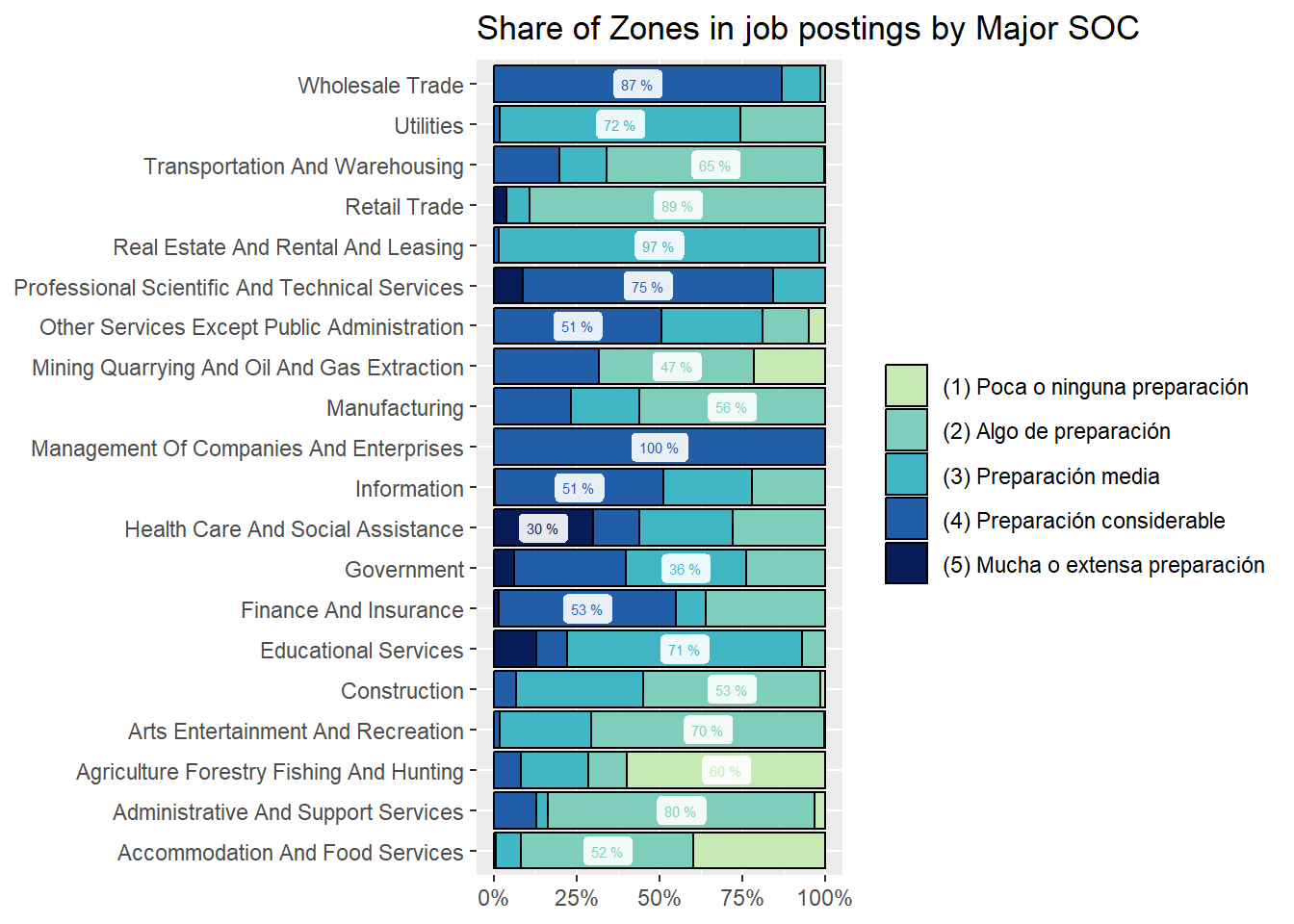
zones_soc_df<-country_var_count(south_cone_df %>%mutate(major_group_title =str_remove_all(major_group_title," Occupations")),category ="zones_label",country="major_group_title")zones_sector_df %>%ggplot(aes(x=main_sector,y=group_in_country_share))+geom_col(aes(fill=zones_label),position ="fill", color="black")+geom_label(data=group_by(zones_sector_df,main_sector) %>%mutate(label_y=ifelse(group_in_country_share==max(group_in_country_share),paste(round(group_in_country_share,2)*100,"%"),NA)),aes(label=label_y, color=zones_label),alpha=.9, size=2, position =position_fill(vjust =0.5), show.legend =FALSE)+coord_flip()+scale_y_continuous(labels = scales::percent_format())+scale_fill_manual(values=RColorBrewer::brewer.pal(9,"YlGnBu")[c(3,4,5,7,9)])+scale_color_manual(values=RColorBrewer::brewer.pal(9,"YlGnBu")[c(3,4,5,7,9)])+labs(title ="Share of Zones in job postings by Major SOC",fill=NULL,color=NULL,y=NULL,x=NULL)
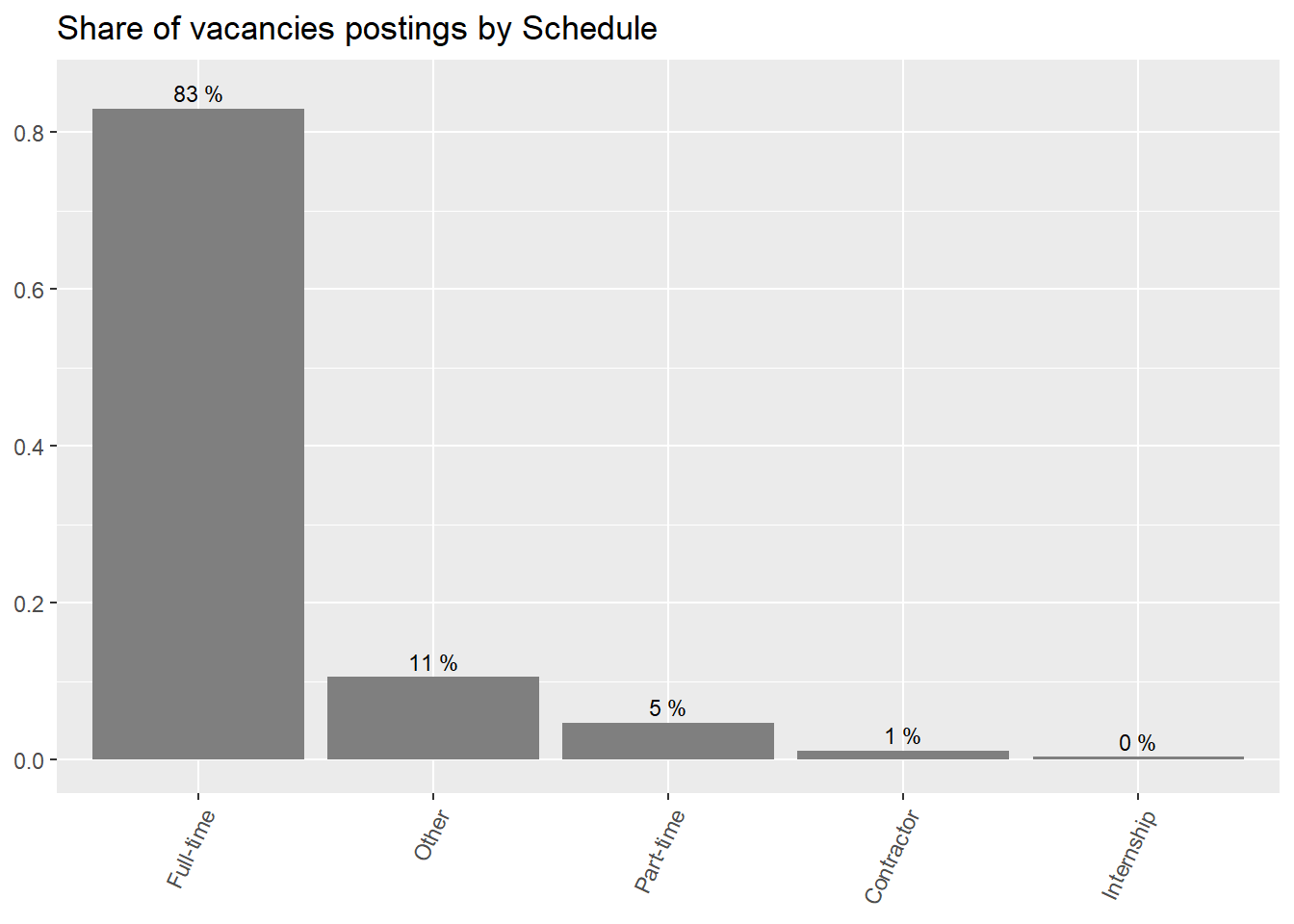
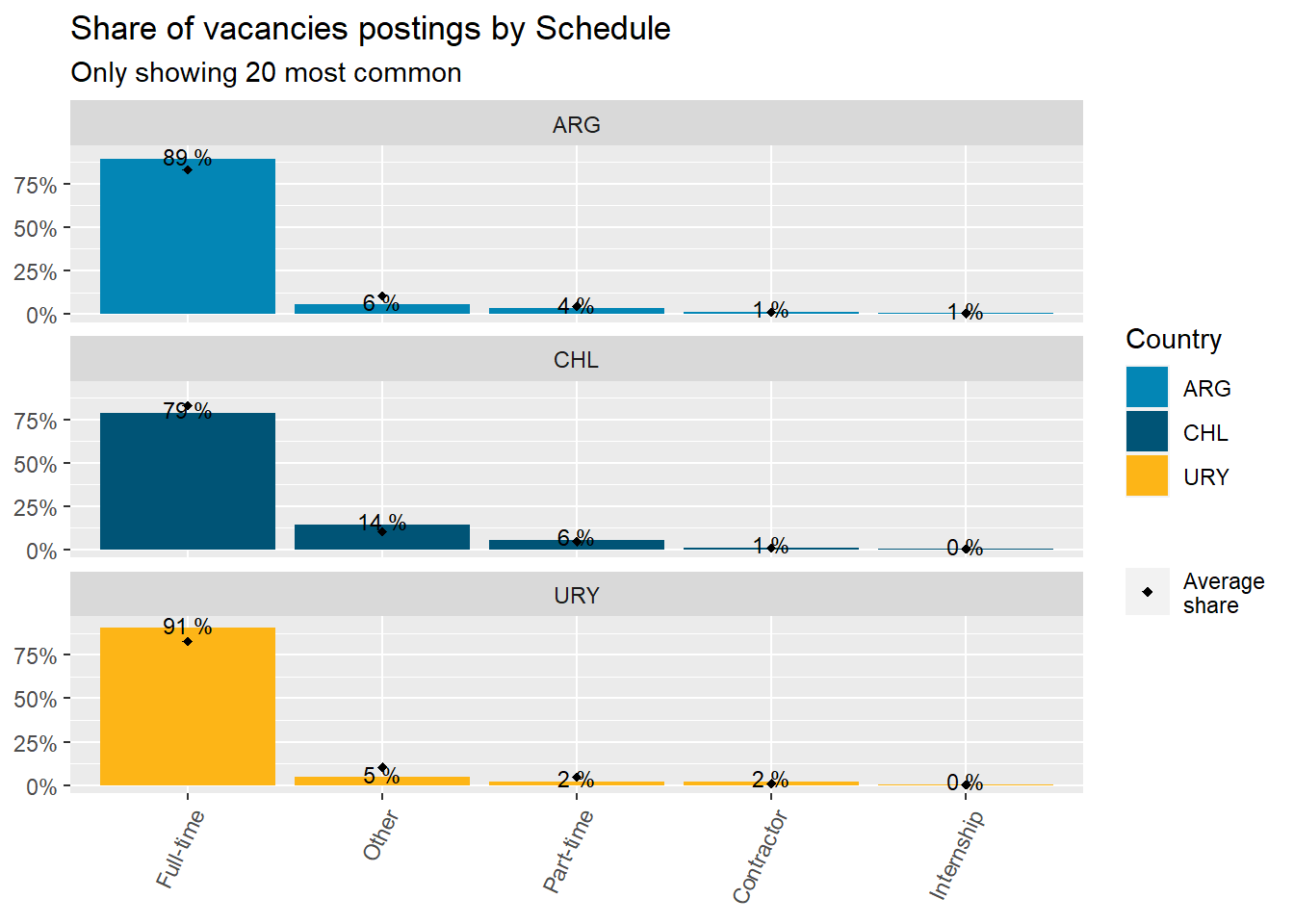
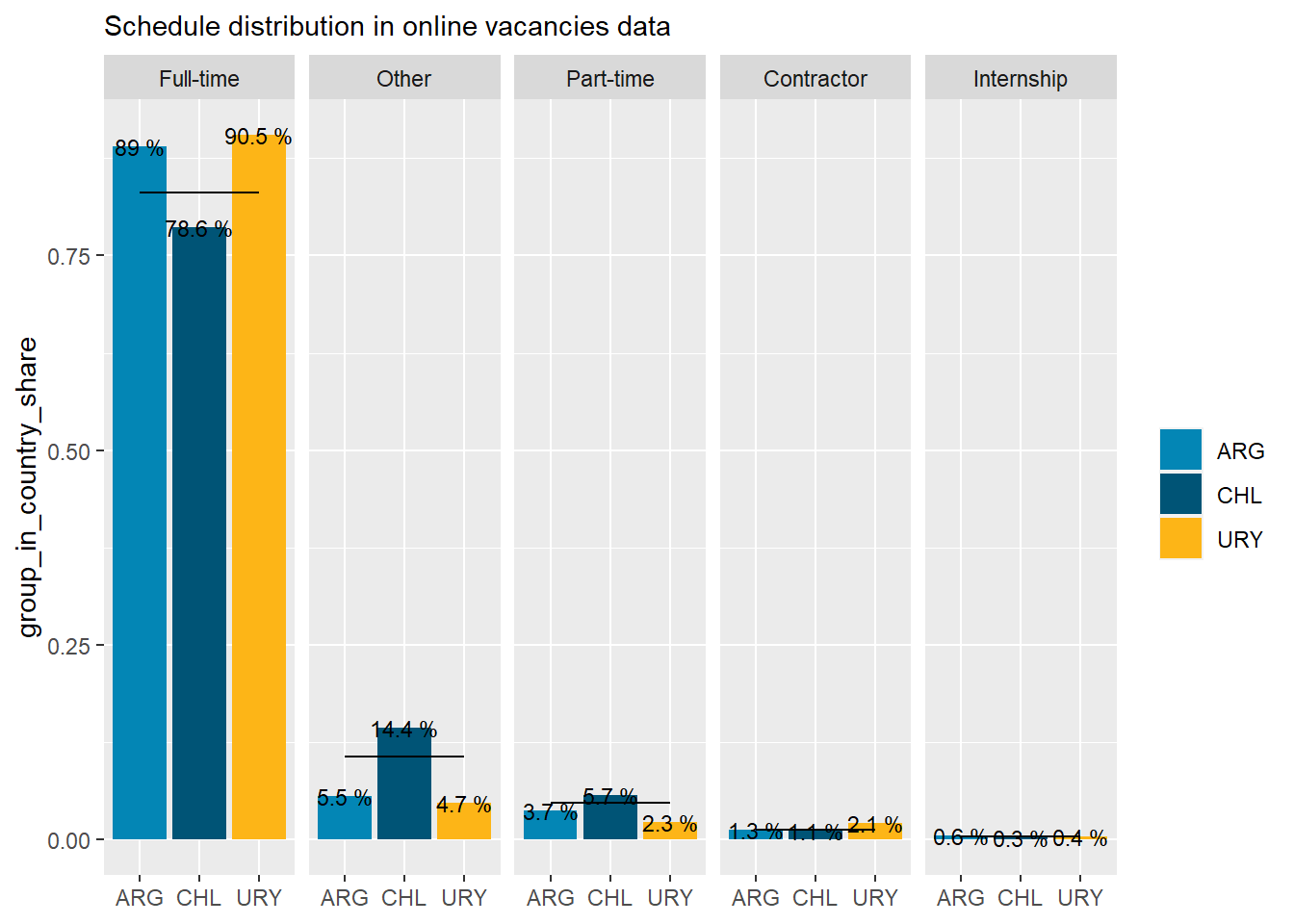
14% of postings in Chile correspond to “Other”. This needs clarification. This is associated with the lower than average share of full-time positions in Chile.
5.7% of Chile job postings correspond to “Part-time” roles (about 1 percent point above average).
The contractor mode is more prevalent in Uruguay job postings (almost twice the average). This would be consistent with the rumors about many Uruguay firms outsourcing Argentinean workers. This should be corroborated with remote work data.
schedule_df %>%ggplot(aes(x=reorder(schedule,-group_share),y=group_share))+geom_col(fill="gray50")+geom_text(aes(label=paste(round(group_share,2)*100,"%")), size=3,nudge_y =0.02)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by Schedule",x=NULL,y=NULL)
Figure 29: ?(caption)
Code
country_var_chart(schedule_country_df, category ="schedule",country="country_code")[[1]]+scale_fill_manual(values=country_colors)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of vacancies postings by Schedule",subtitle ="Only showing 20 most common",fill="Country",shape=NULL,x=NULL,y=NULL)
Figure 30: ?(caption)
Code
country_var_chart(schedule_country_df, category ="schedule",country="country_code")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Schedule distribution in online vacancies data",x=NULL,fill=NULL)
Code
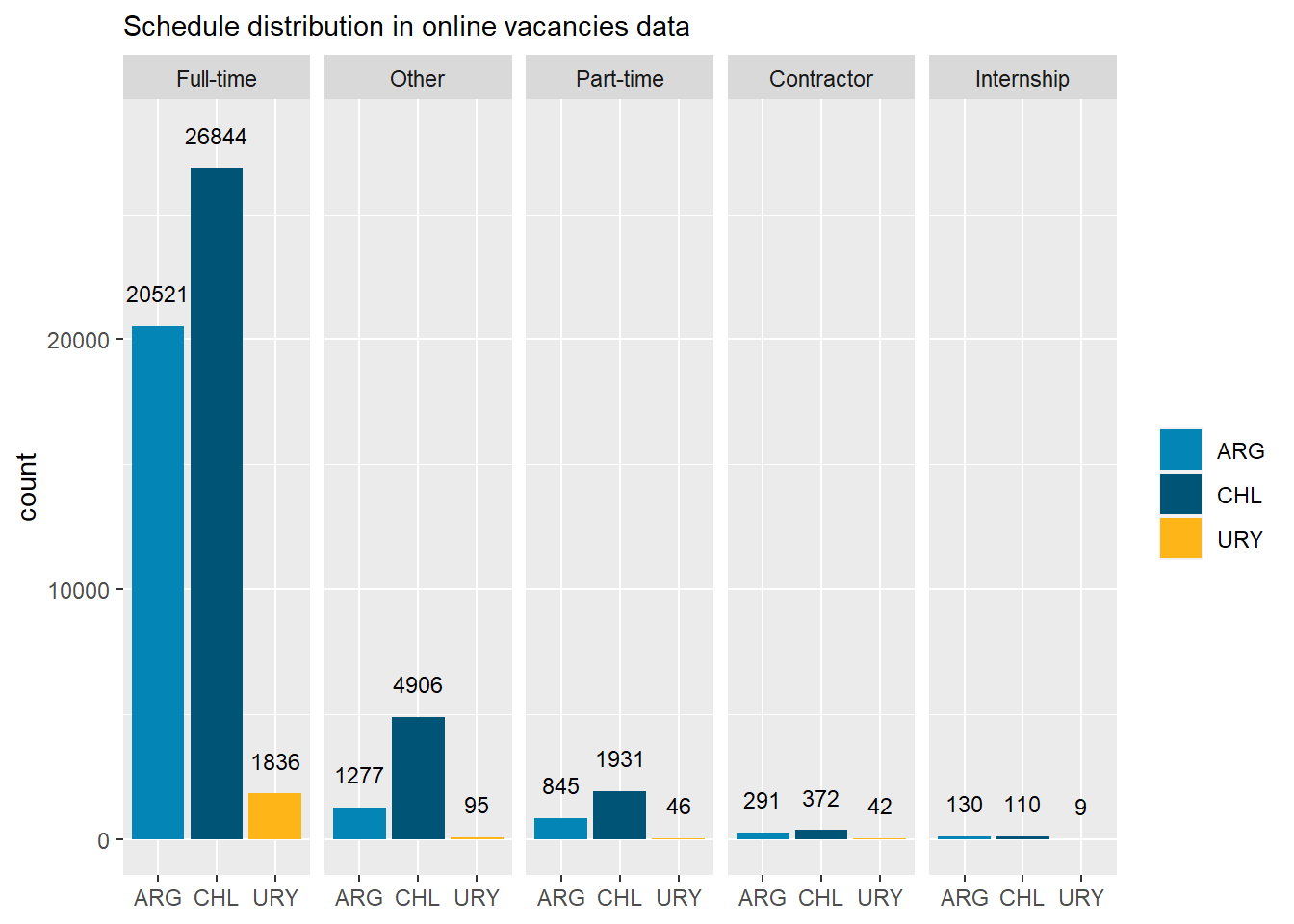
country_var_chart(schedule_country_df, category ="schedule",country="country_code")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Schedule distribution in online vacancies data",x=NULL,fill=NULL)
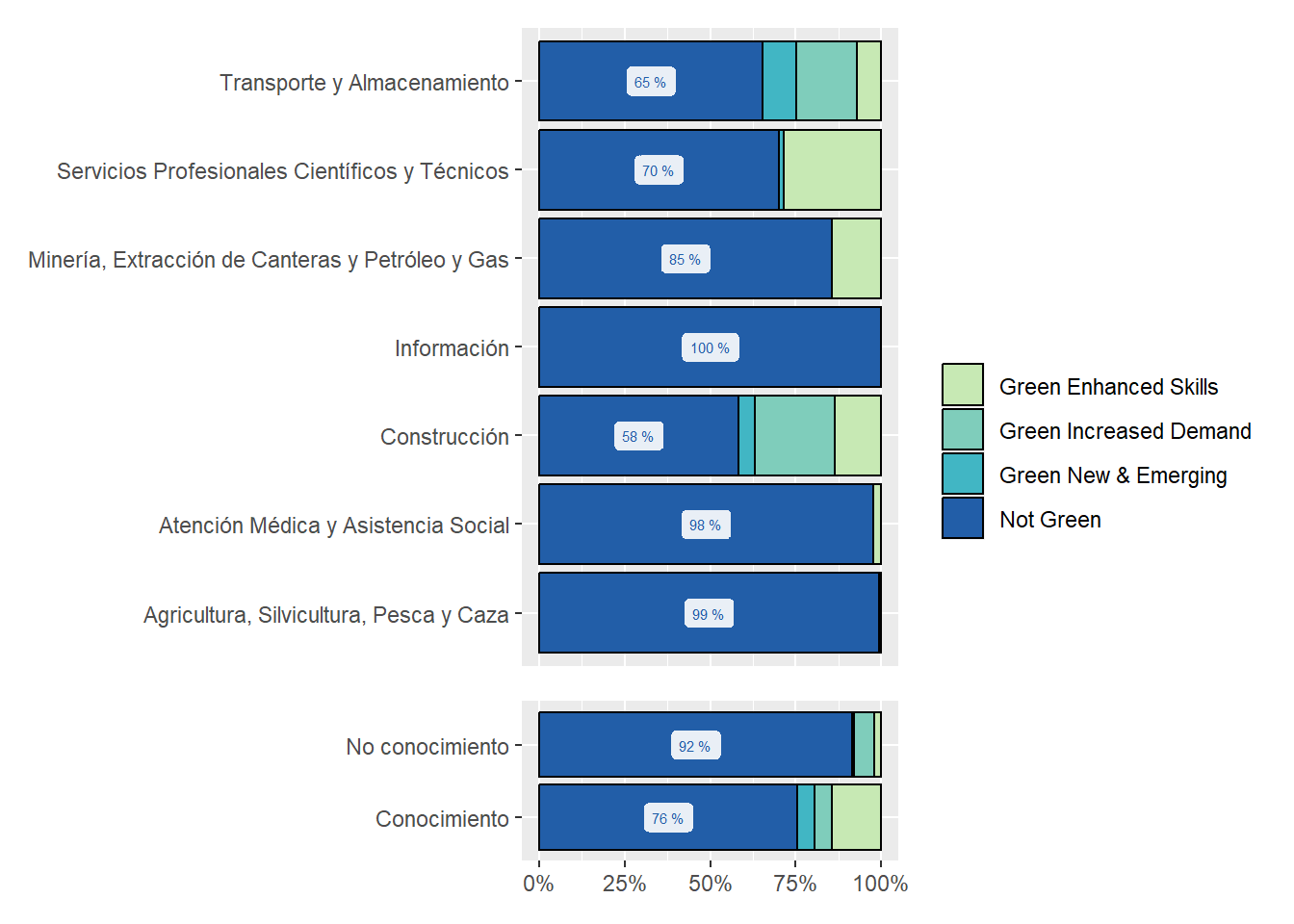
Green jobs
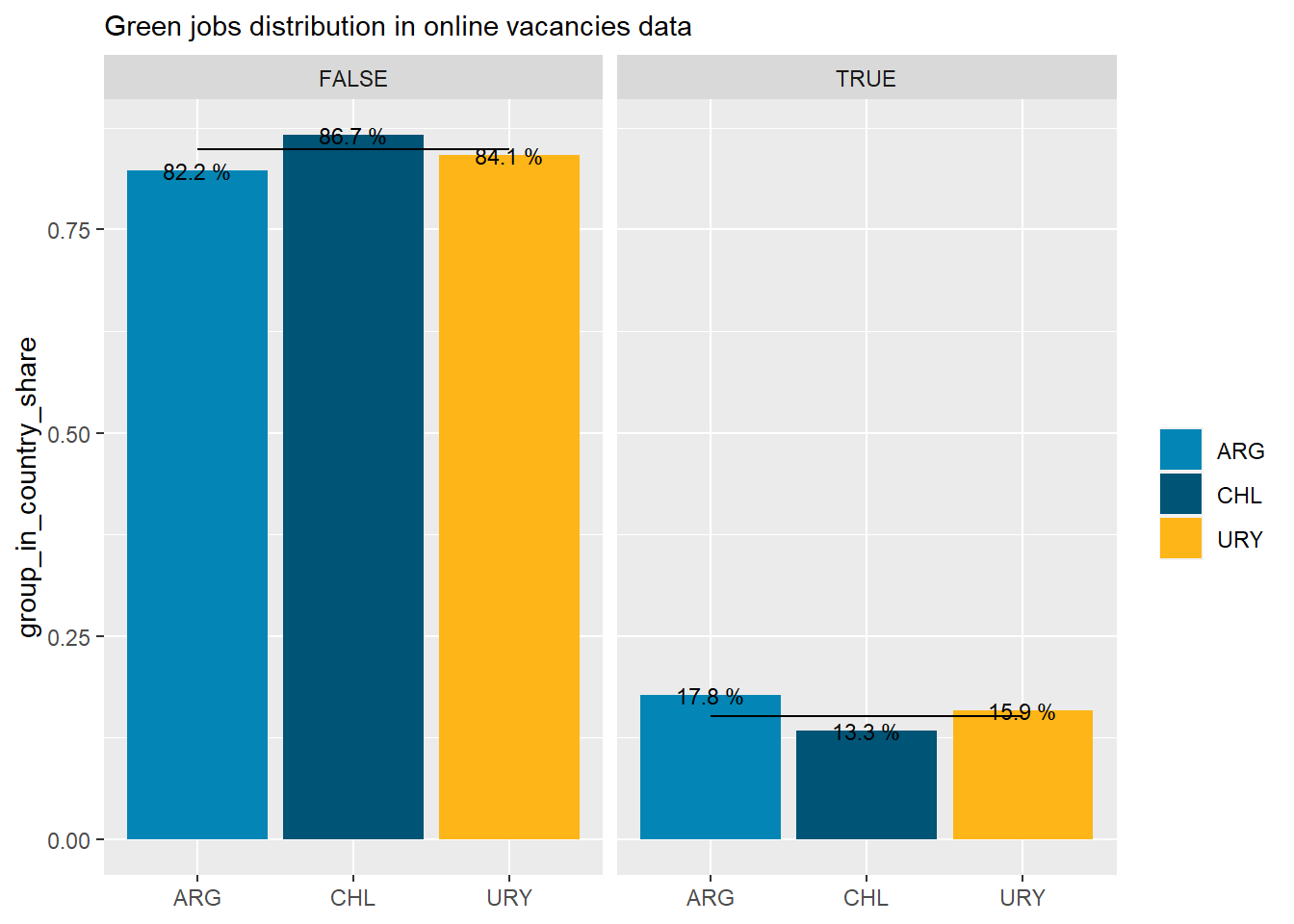
Green jobs represent 15% of all online job postings.
Argentina has the highest share of green jobs in its’ job postings (17%).
Within green jobs, the most demanded are classified as “Green Increased Demand” (45%).
Green job postings in Argentina are 48% “Green Increased Demand”, 37% are “Green enhanced skills”, and 14% are “Green New & Emerging”.
Greener regions in terms of online vacancies are Santiago, Buenos Ares, Valparaíso, Concepción, Rosario, Córdoba y Antofagasta. Buenos aires, Concepción, Rosario, Córdoba, and Antofagasta are overrepresented in the sample of green online vacancies.
country_var_chart(green_country_df_1, category ="green_job_bin",country="country_code")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Green jobs distribution in online vacancies data",x=NULL, fill=NULL)
Figure 31: Green jobs distribution, by country
Code
country_var_chart(green_country_df_1, category ="green_job_bin",country="country_code")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Green jobs distribution in online vacancies data",x=NULL, fill=NULL)
Code
## Decomposition of green jobsgreen_country_df_2<-country_var_count(data =filter(south_cone_df, green_job_bin==TRUE),category ="green_job",country="country_code")country_var_table(data=green_country_df_2, category ="green_job",country="country_code",interactive =FALSE)
Table 4: Green job types distribution
green_job
Vacancies
% of Vacancies
% of ARG
% of CHL
% of URY
Green Increased Demand
4042
45.00%
48.43%
42.06%
42.86%
Green Enhanced Skills
3654
40.68%
37.59%
43.36%
42.24%
Green New & Emerging
1286
14.32%
13.98%
14.58%
14.91%
sum
—
8,982.00
1.00
1.00
1.00
1.00
Code
country_var_chart(green_country_df_2, category ="green_job",country="country_code")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Green jobs types in online vacancies data",x=NULL,y=NULL,fill=NULL)
Figure 32: Green job types distribution by country
Code
country_var_chart(green_country_df_2, category ="green_job",country="country_code")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Green jobs types in online vacancies data",x=NULL,y=NULL,fill=NULL)
country_var_count(south_cone_df, category ="rm",country="green_job_bin") %>%arrange(desc(group_vacancies)) %>%filter(green_job_bin==1) %>%mutate(ratio=round(group_in_country_share/group_share,2)) %>%mutate(share=scales::percent(group_in_country_share,accuracy=1),group_share=scales::percent(group_share, accuracy=2)) %>%arrange(desc(group_vacancies)) %>%filter(group_vacancies>500) %>%ungroup() %>%select(region=rm,`Job postings`=group_vacancies,`share in all data`=group_share,`share in green`=group_in_country_share,ratio) %>%head(15) %>% kableExtra::kable()
Table 5: Green jobs distribution, by region
region
Job postings
share in all data
share in green
ratio
Santiago
13725
24%
0.1871521
0.81
Buenos Aires (GZM)
9313
16%
0.1845914
1.17
Valparaíso
4932
8%
0.0676909
0.81
Concepción
3774
6%
0.0659096
1.03
Rosario
2316
4%
0.0503229
1.29
Gran Temuco
2125
4%
0.0210421
0.59
Coquimbo
1913
4%
0.0292808
0.91
Córdoba
1810
4%
0.0360721
1.18
Mendoza
1734
2%
0.0338455
1.16
Antofagasta
1477
2%
0.0351815
1.41
Puerto Montt
1251
2%
0.0227121
1.08
Metropolitana
1220
2%
0.0218214
1.06
Tarapacá
1168
2%
0.0237141
1.20
Corrientes
1074
2%
0.0191494
1.06
Región Metropolitana Confluencia
889
2%
0.0180361
1.20
Code
country_var_count(south_cone_df, category ="rm",country="green_job_bin")%>%arrange(desc(group_vacancies)) %>%filter(green_job_bin==TRUE) %>%mutate(green_all_ratio=group_in_country_share/group_share) %>%arrange(desc(green_all_ratio)) %>%filter(group_vacancies>500) %>%ggplot(aes(x=group_share,y=group_in_country_share))+geom_point()+geom_label_repel(aes(label=rm), size=2)+geom_abline(slope =1,intercept =0)+coord_fixed()+labs(subtitle ="Those above the line are more intensive in green vacancies",caption ="Cities with more than 1000 job postings",y="Share of green jobs postings",x="Share of all job postings")
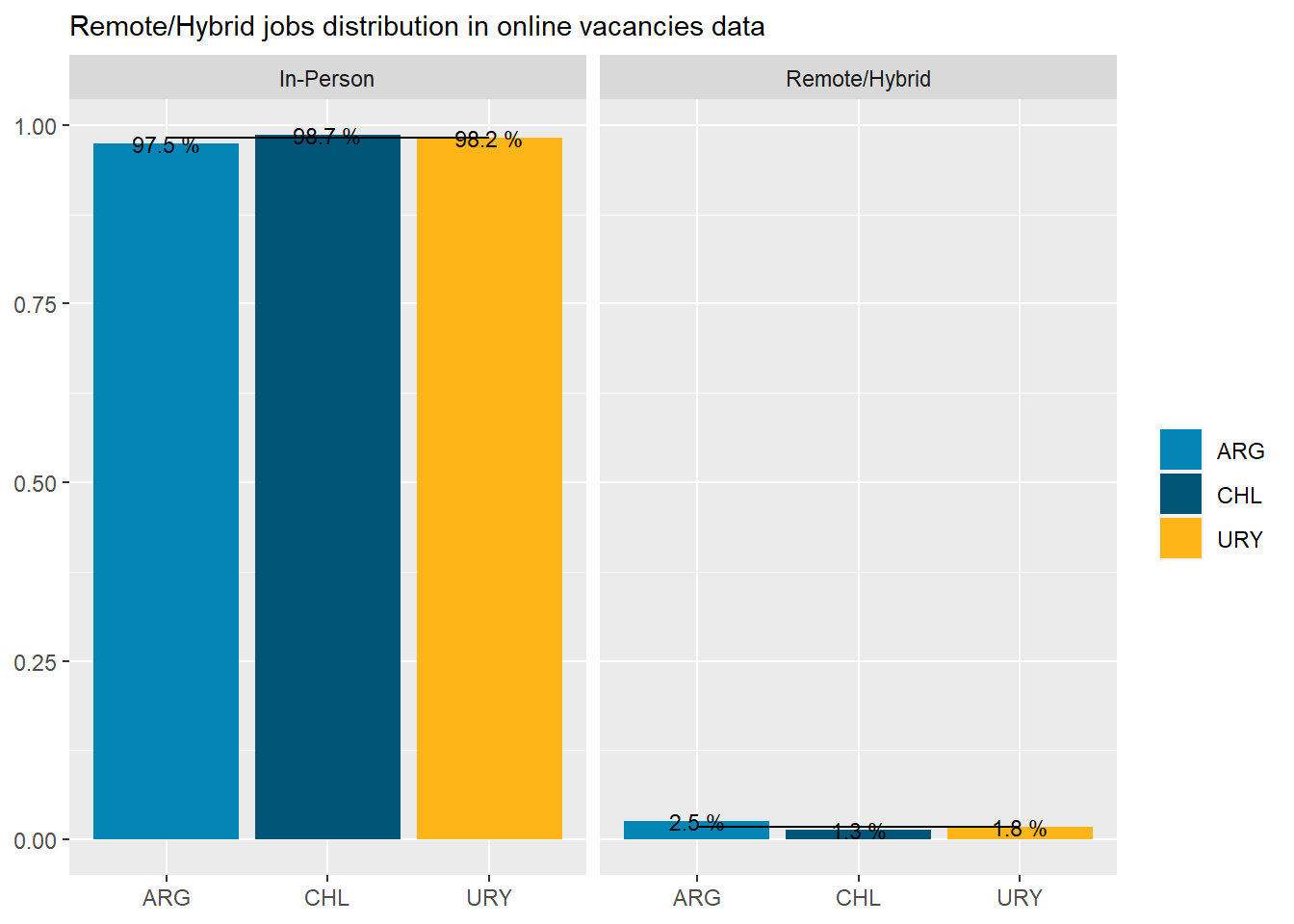
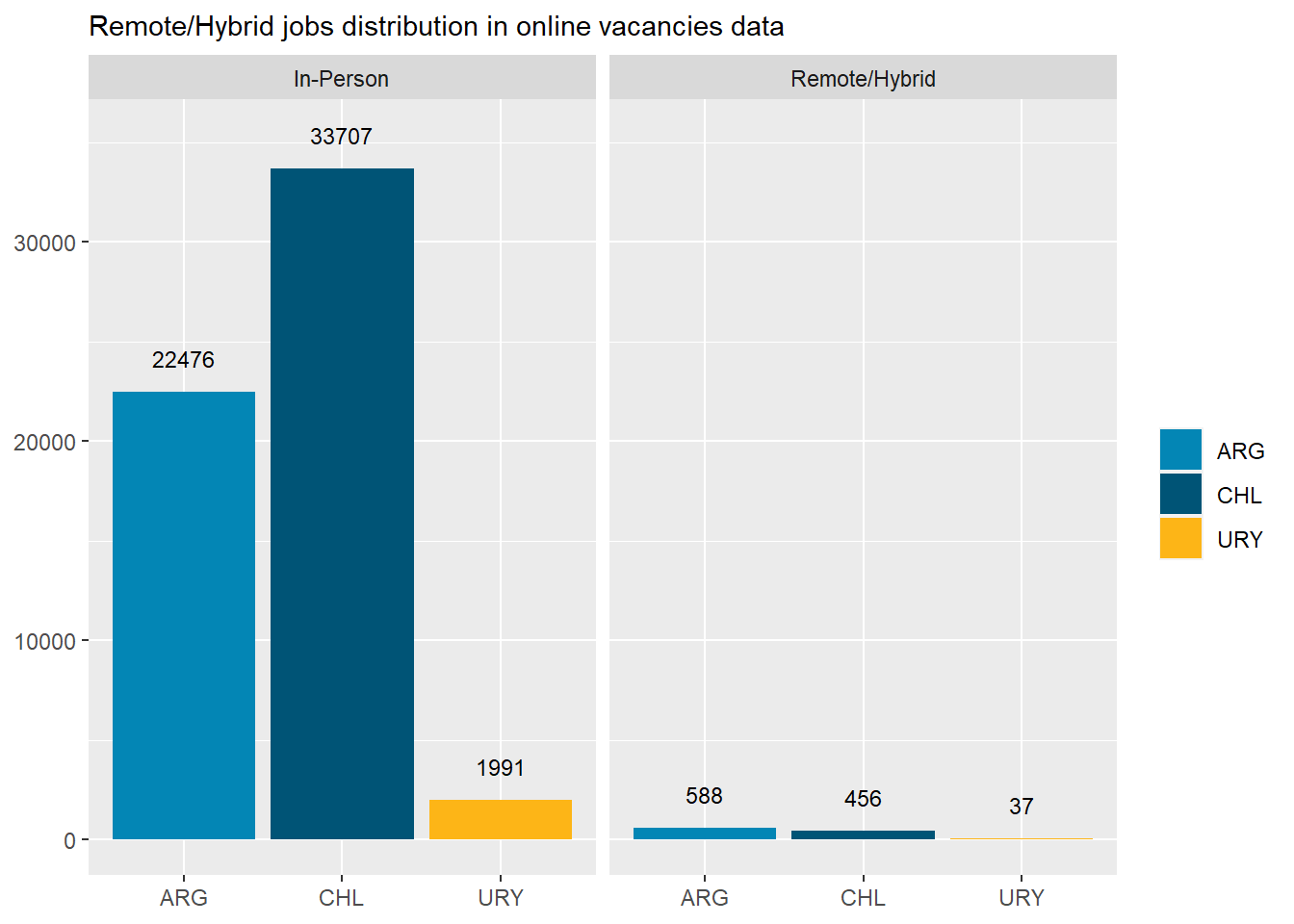
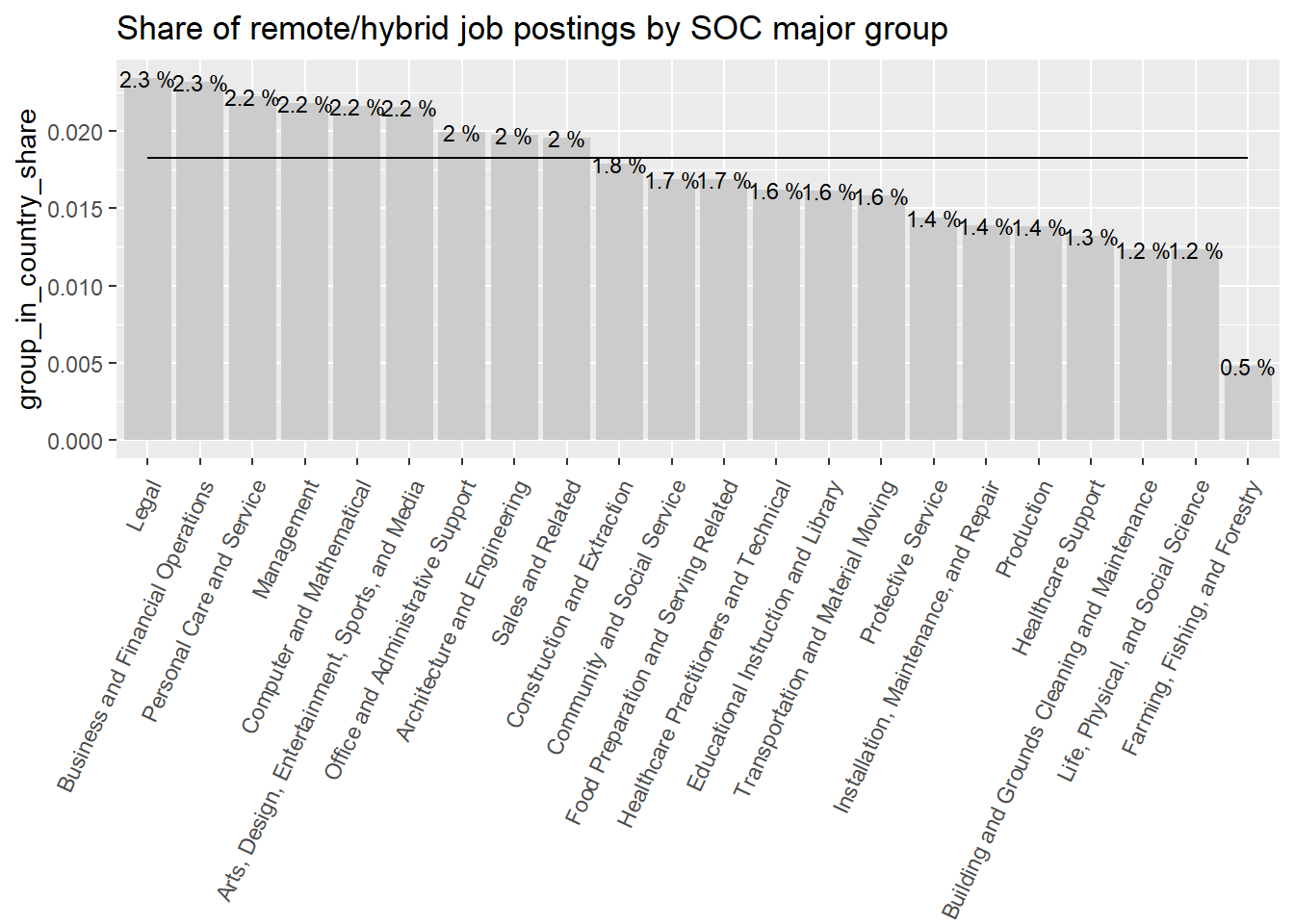
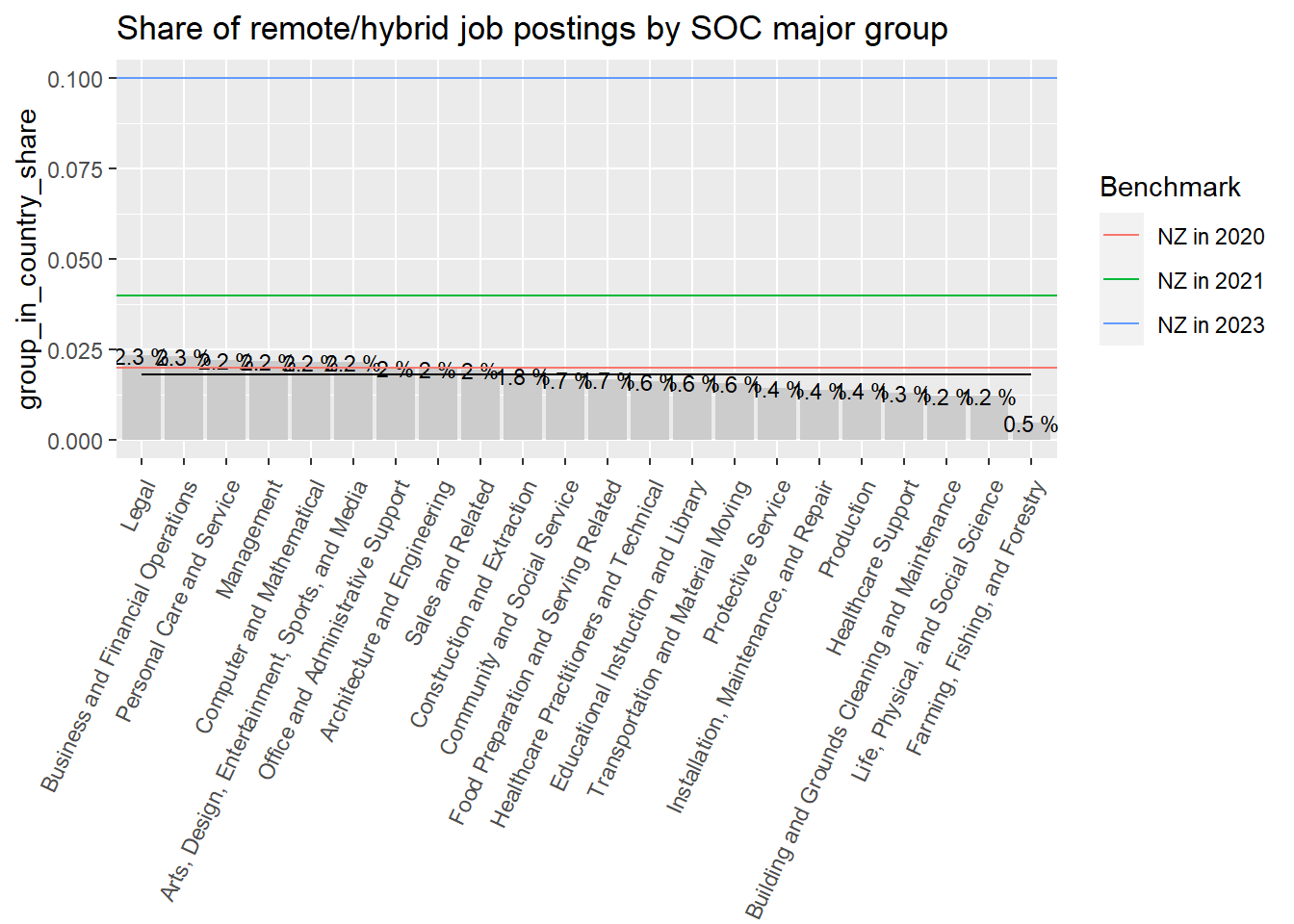
Only 1.8% of jobs postings are classified remote. This contrast with 10% and 12% for countries like New Zeland and Australia, which aren’t much different than Chile according to remote work surveys at the firm level. This gap is puzzling.
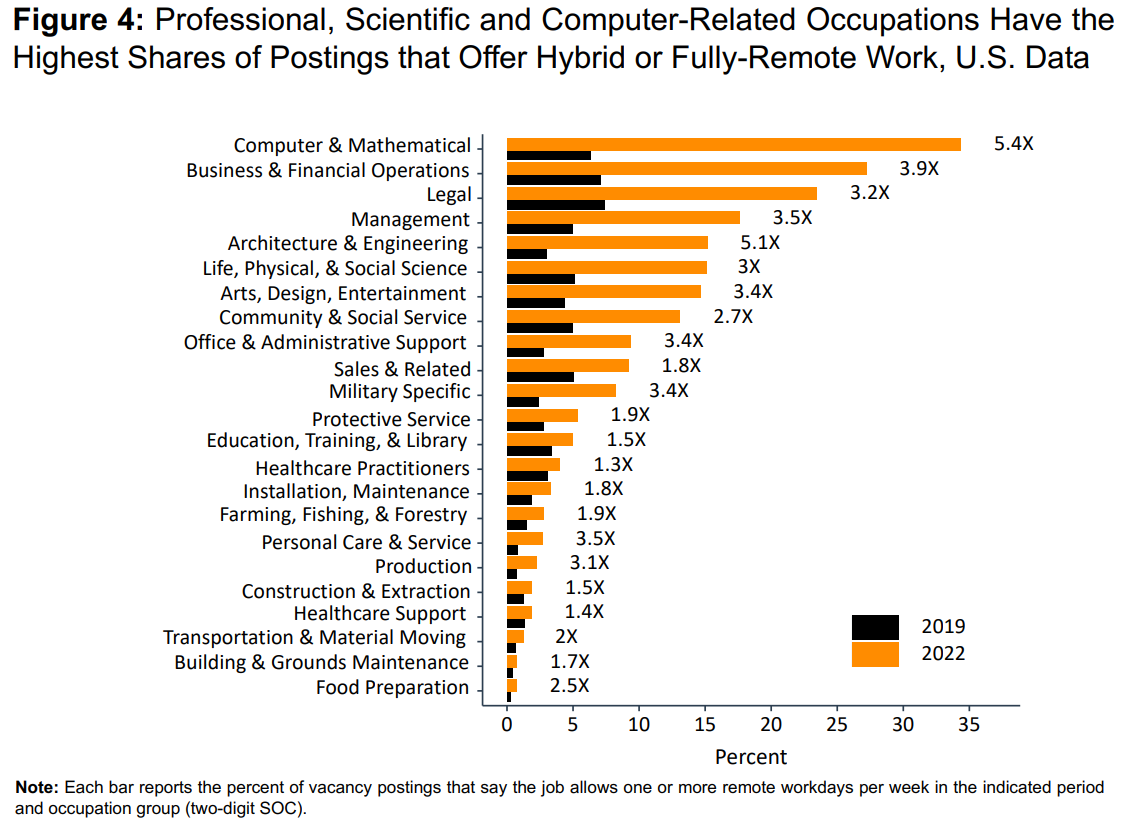
The occupational major groups with the highest shares of remote postings are “Legal”, “Business and Financial Operations”, “Personal Care and Service” (weird), “Management”, and “Computer and Mathematical” occupations, in that order. This is different from the ranking of remote online vacancies found by Lightcast in English speaking countries: “Computer and Mathematical”, “Business and Financial Operations”, “Legal”, “Management”, and “Architecture and Engineering.”
country_var_chart(remote_country_df, category ="remote",country="country_code")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Remote/Hybrid jobs distribution in online vacancies data",x=NULL,y=NULL,fill=NULL)
Figure 39: Remote work distribution by country
Code
country_var_chart(remote_country_df, category ="remote",country="country_code")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Remote/Hybrid jobs distribution in online vacancies data",x=NULL,y=NULL,fill=NULL)
Code
remote_df_2<-country_var_count(data =mutate(south_cone_df,remote=ifelse(remote==1,"Remote/Hybrid","In-Person")),category ="remote",country="major_group_title")remote_df_3<-rbind(country_var_count(data =mutate(filter(south_cone_df,country_code=="ARG"),remote=ifelse(remote==1,"Remote/Hybrid","In-Person")),category ="remote",country="major_group_title") %>%mutate(country_code="ARG"),country_var_count(data =mutate(filter(south_cone_df,country_code=="CHL"),remote=ifelse(remote==1,"Remote/Hybrid","In-Person")),category ="remote",country="major_group_title") %>%mutate(country_code="CHL"),country_var_count(data =mutate(filter(south_cone_df,country_code=="URY"), remote=ifelse(remote==1,"Remote/Hybrid","In-Person")),category ="remote",country="major_group_title") %>%mutate(country_code="URY") )%>%# I don't need the share of remote jobs in each country.select(-group_vacancies,-group_share) %>%# I want only remote shares of major groups in each countryfilter(remote=="Remote/Hybrid") (chart_rmw<-remote_df_2 %>%filter(remote=="Remote/Hybrid") %>%ggplot(aes(x=reorder(str_remove(major_group_title,"Occupations"),-group_in_country_share),y=group_in_country_share))+geom_col(fill="gray80")+geom_line(aes(y=group_share,group=remote))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of remote/hybrid job postings by SOC major group",x=NULL))
Figure 40: ?(caption)
Code
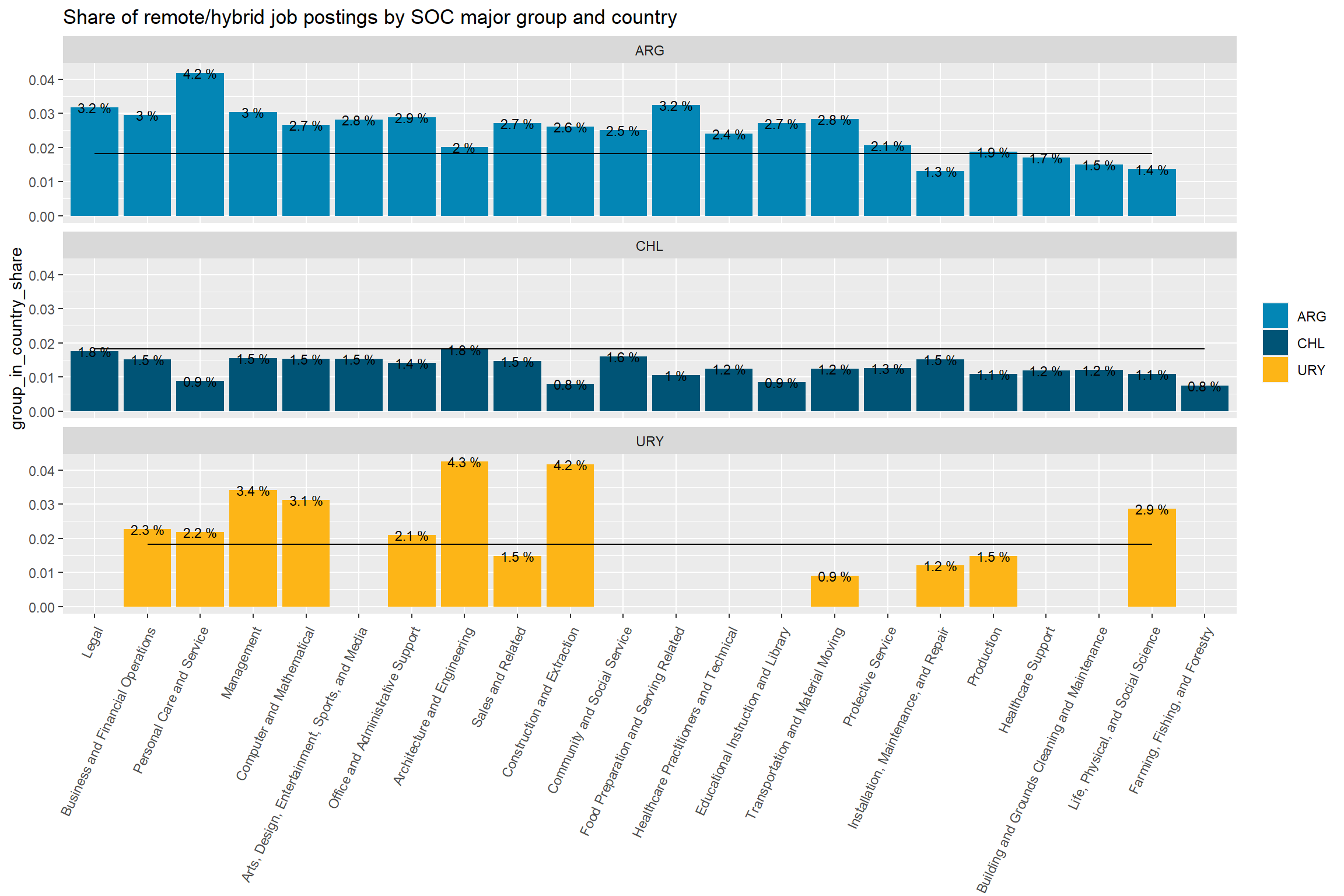
remote_df_3 %>%# attach the share of remote vacancies in each group left_join(remote_df_2 %>%filter(remote=="Remote/Hybrid") %>%select(major_group_title,share_of_remote_in_group=group_in_country_share, group_share)) %>%# plot the share of remote vacancies in each group, by countryggplot(aes(x=reorder(str_remove(major_group_title,"Occupations"),-share_of_remote_in_group),y=group_in_country_share)) +geom_col(aes(fill=country_code))+geom_line(aes(y=group_share,group=remote))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+scale_fill_manual(values=country_colors)+facet_wrap(vars(country_code),ncol=1) +theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of remote/hybrid job postings by SOC major group and country",fill=NULL,x=NULL)
chart_rmw+geom_hline(aes(yintercept=0.02,color="NZ in 2020"))+geom_hline(aes(yintercept=0.04,color="NZ in 2021"))+geom_hline(aes(yintercept=0.1,color="NZ in 2023"))+labs(color="Benchmark")
Figure 42: ?(caption)
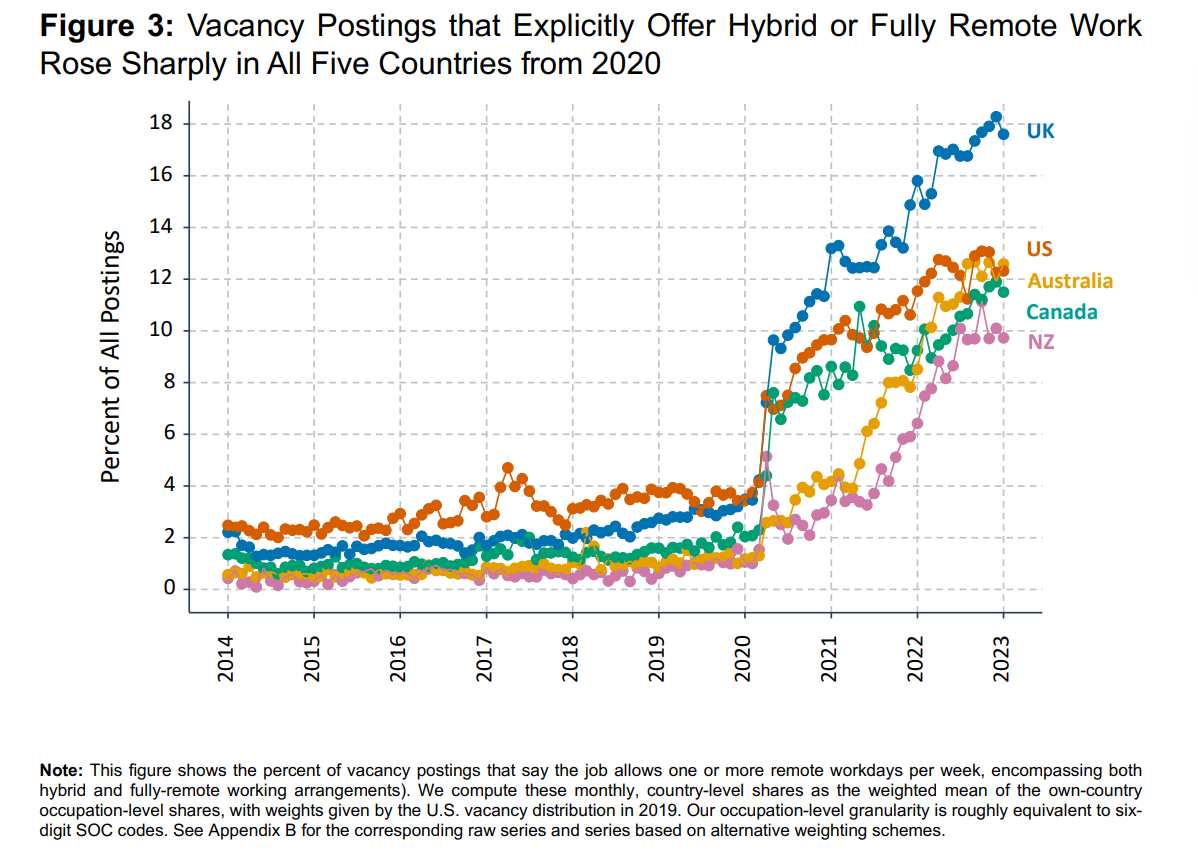
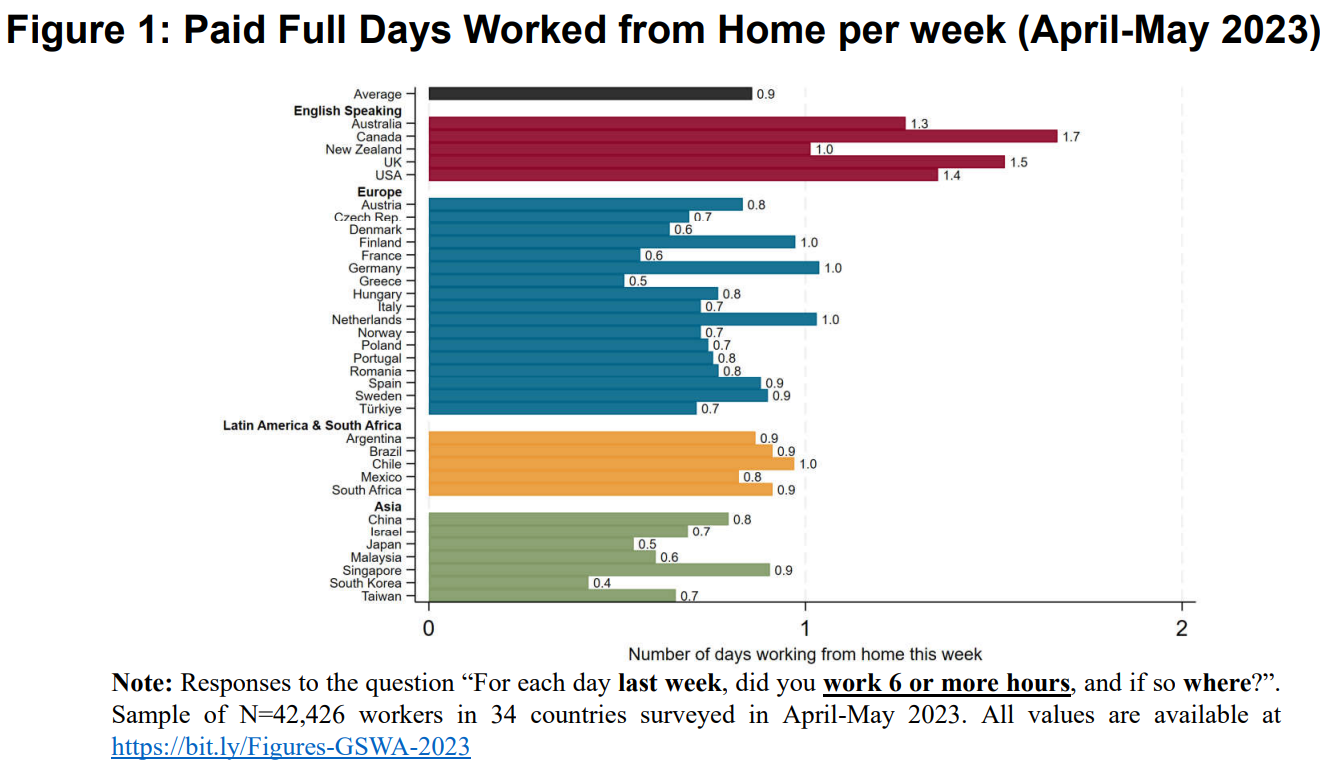
The Global Survey of Work (GSWA) arrangements looked at 34 countries in April-May 2023 and reports that Latin American workers work from home (WFH) 0.9 days a week on average, (which coincides with the global average) while workers in New Zeland and Australia work from home an average of 1 and 1.3 days, respectively. According to this, we should expect job vacancies to show WFH rates in Chile (1.8%) to be at least close to New Zeland (10%).
The GSWA review also shows Chileans work from home more than Argentineans, which refuses our results. Of course, this could be due to the difference in sector compositions between the GSWA and online job vacancies.
Figure 43: bloom1
How does it allign with Dingle & Neiman (2020)?
Does a 1.8% share of remote job vacancies make sense when we take into account the occupations these vacancies are concentrated in? We’ll use Dingle and Neiman (2020) definition of teleworkable occupations and calculate the percentage of online job postings that fall in that category and see whether it’s lower than the observed in English Speaking countries. Dingle and Neiman (2020) define teleworkable occupations as those not involving evidently ‘in-place’ actvities and can be perfomed remotely.
Take a look at the classification of a few occupations:
Code
onet_teleworkable<-read_csv("raw/ONET_28_0/onet_teleworkable_r.csv")print(paste(c("Not-teleworkable occupations in ONET 28.0:","Teleworkable occupations in ONET 28.0:"),table(onet_teleworkable$teleworkable),"(",round(table(onet_teleworkable$teleworkable)/nrow(onet_teleworkable),2),")" ) )
[1] “Not-teleworkable occupations in ONET 28.0: 565 ( 0.65 )” [2] “Teleworkable occupations in ONET 28.0: 308 ( 0.35 )”
The table below show the share of online vacancies in occupations that could be performed remotely. 42% of all job vacancies could be feasibly performed from home according the the average work context and activities of the occupations they were assigned on. It’s below the 50% share I spotted on US job postings between 2020-2021, but it’s large considering they only account for 35% of all occupational codes and around 35% of employment in the US at the onset of the pandemic.
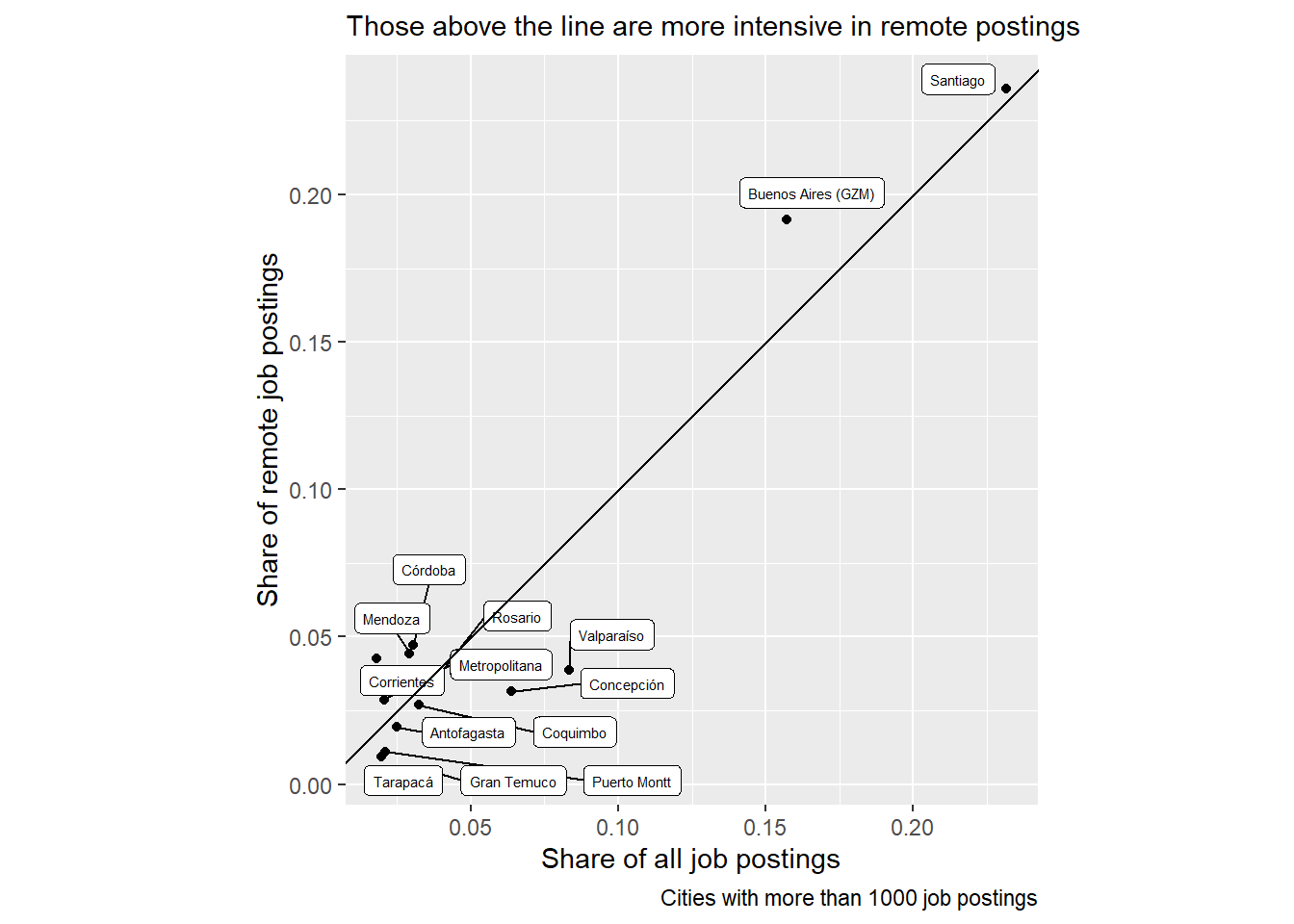
Is there any spatial concentration pattern in remote postings?
Do we see more remote postings in large or small cities? No at a glance. It’d be worth controlling for sectorial composition of employment to test this hypothesis.
Code
country_var_count(data = south_cone_df, category ="rm",country="remote") %>%arrange(desc(group_vacancies)) %>%filter(remote==1) %>%mutate(ratio=round(group_in_country_share/group_share,2)) %>%mutate(share=scales::percent(group_in_country_share,accuracy=2),group_share=scales::percent(group_share, accuracy=2)) %>%arrange(desc(group_vacancies)) %>%filter(group_vacancies>500) %>%ungroup() %>%select(region=rm,`Job postings`=group_vacancies,`share in all data`=group_share,`share in remote`=share,ratio) %>%head(15) %>% kableExtra::kable()
Table 7: Remote work by Metropolitan Region
region
Job postings
share in all data
share in remote
ratio
Santiago
13725
24%
24%
1.02
Buenos Aires (GZM)
9313
16%
20%
1.22
Valparaíso
4932
8%
4%
0.47
Concepción
3774
6%
4%
0.49
Rosario
2316
4%
4%
0.95
Gran Temuco
2125
4%
0%
0.13
Coquimbo
1913
4%
2%
0.83
Córdoba
1810
4%
4%
1.54
Mendoza
1734
2%
4%
1.52
Antofagasta
1477
2%
2%
0.78
Puerto Montt
1251
2%
2%
0.53
Metropolitana
1220
2%
2%
1.39
Tarapacá
1168
2%
0%
0.47
Corrientes
1074
2%
4%
2.35
Región Metropolitana Confluencia
889
2%
2%
0.74
Code
country_var_count(data=south_cone_df,category ="rm",country="remote") %>%arrange(desc(group_vacancies)) %>%filter(remote==TRUE) %>%mutate(remote_all_ratio=group_in_country_share/group_share) %>%arrange(desc(remote_all_ratio)) %>%filter(group_vacancies>1000) %>%ggplot(aes(x=group_share,y=group_in_country_share))+geom_point()+geom_label_repel(aes(label=rm), size=2)+geom_abline(slope =1,intercept =0)+coord_fixed()+labs(subtitle ="Those above the line are more intensive in remote postings",caption ="Cities with more than 1000 job postings",y="Share of remote job postings",x="Share of all job postings")
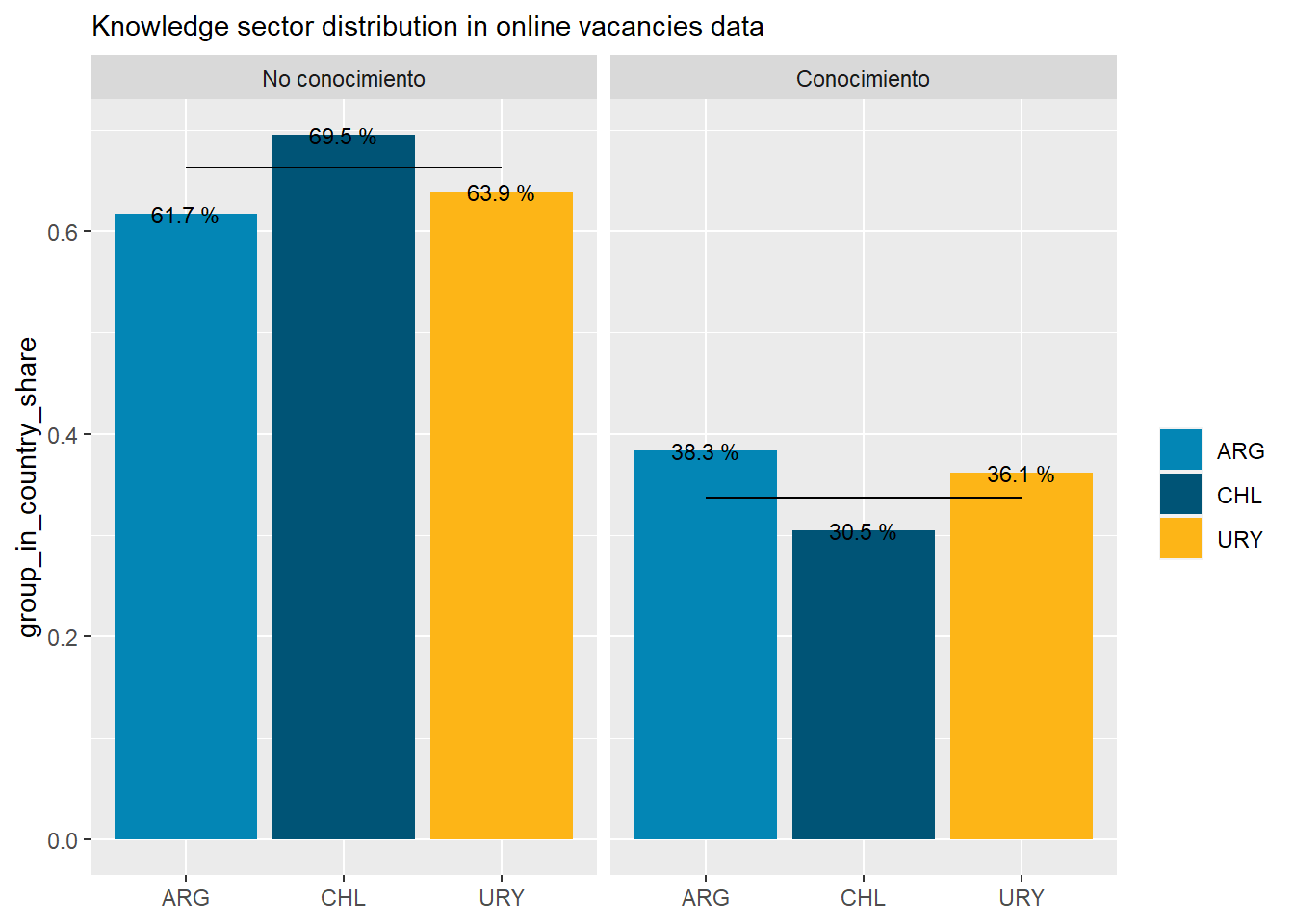
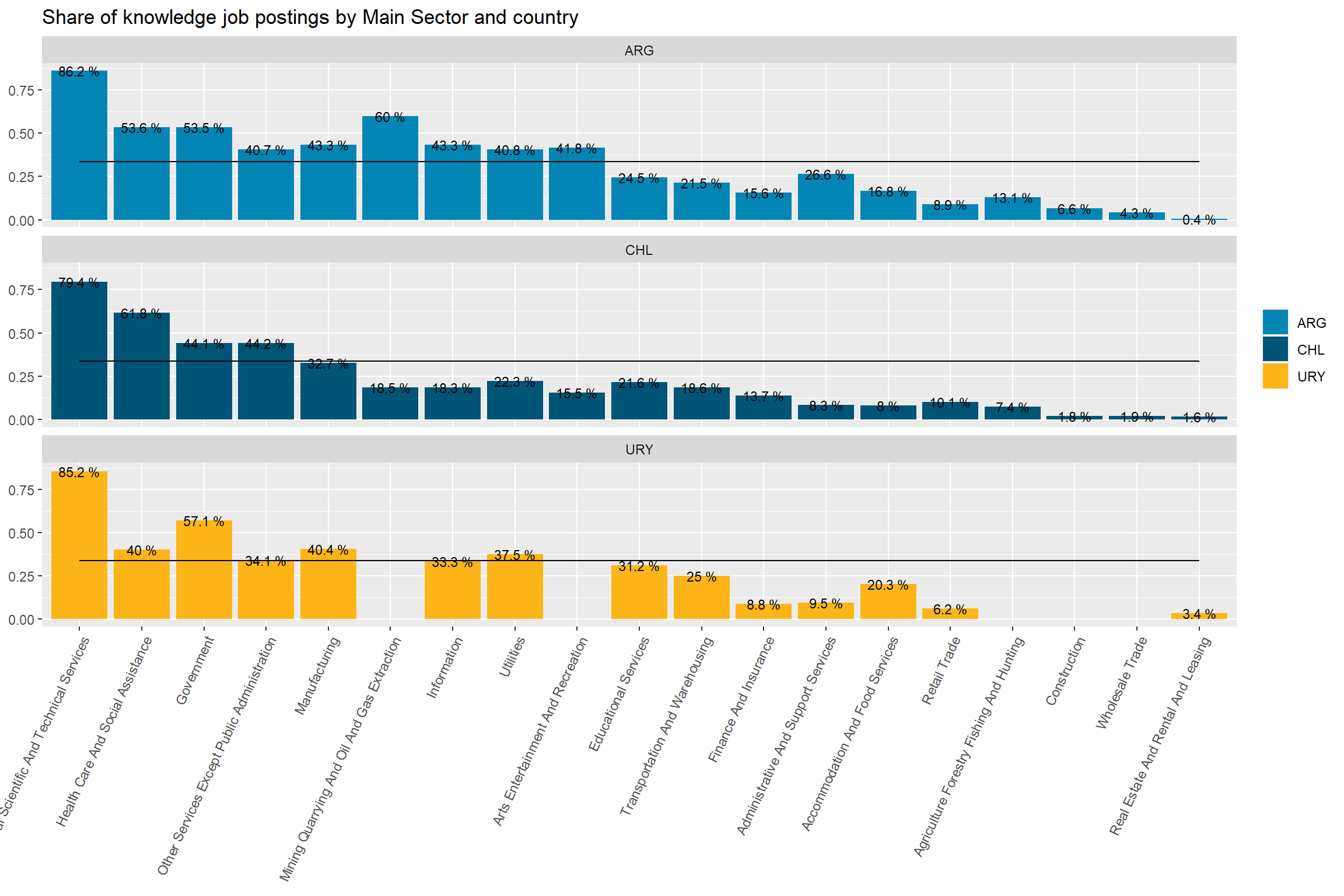
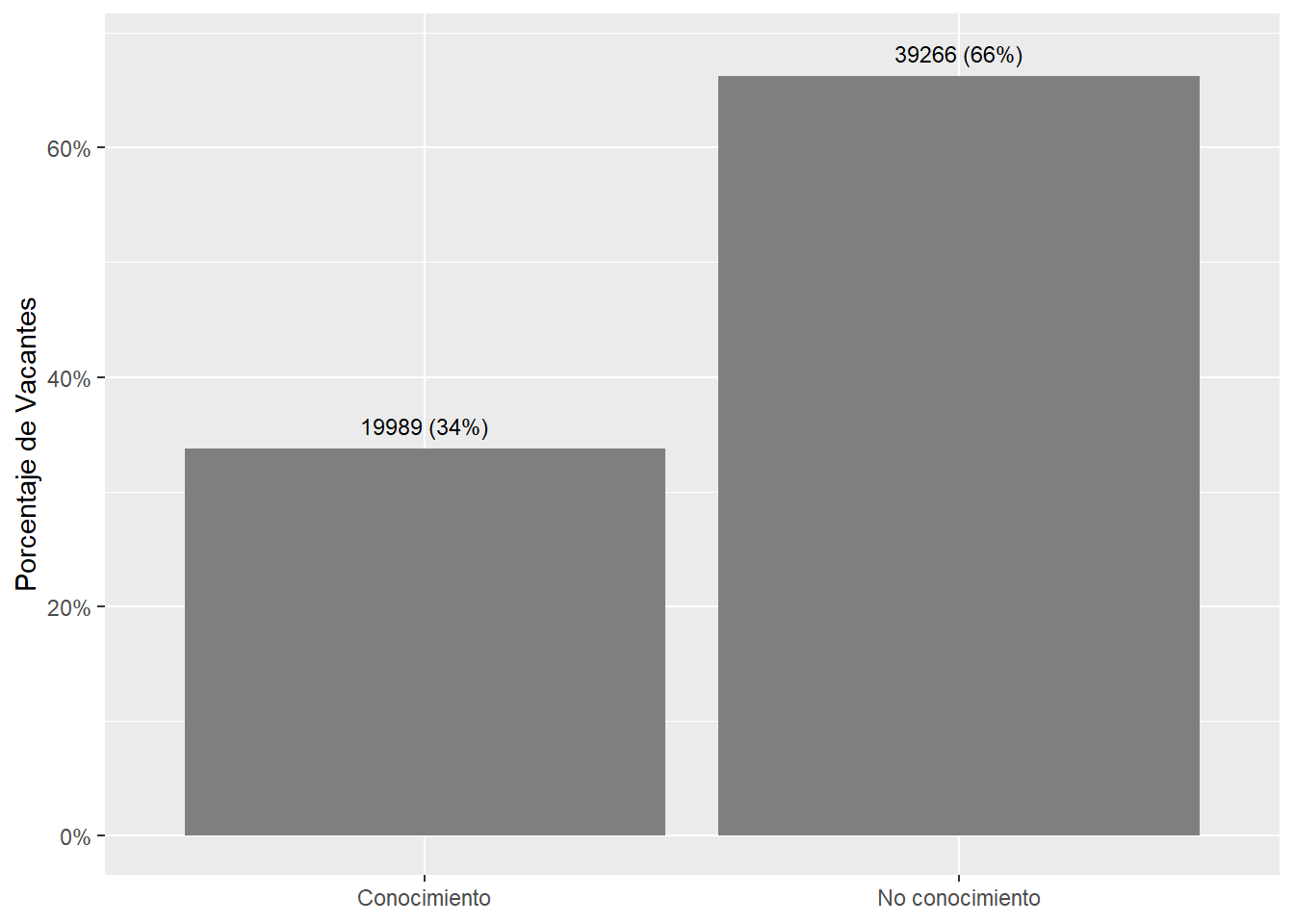
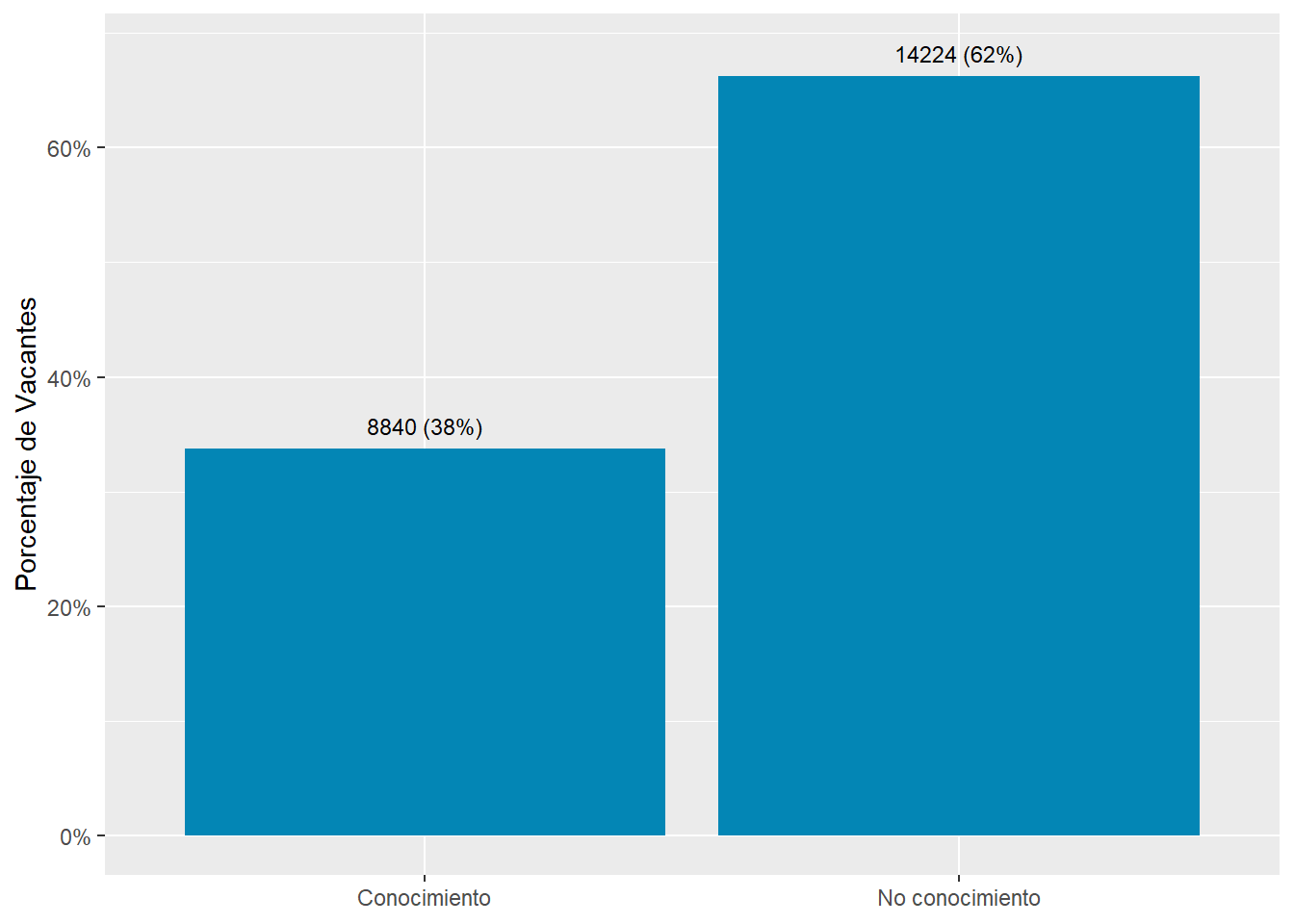
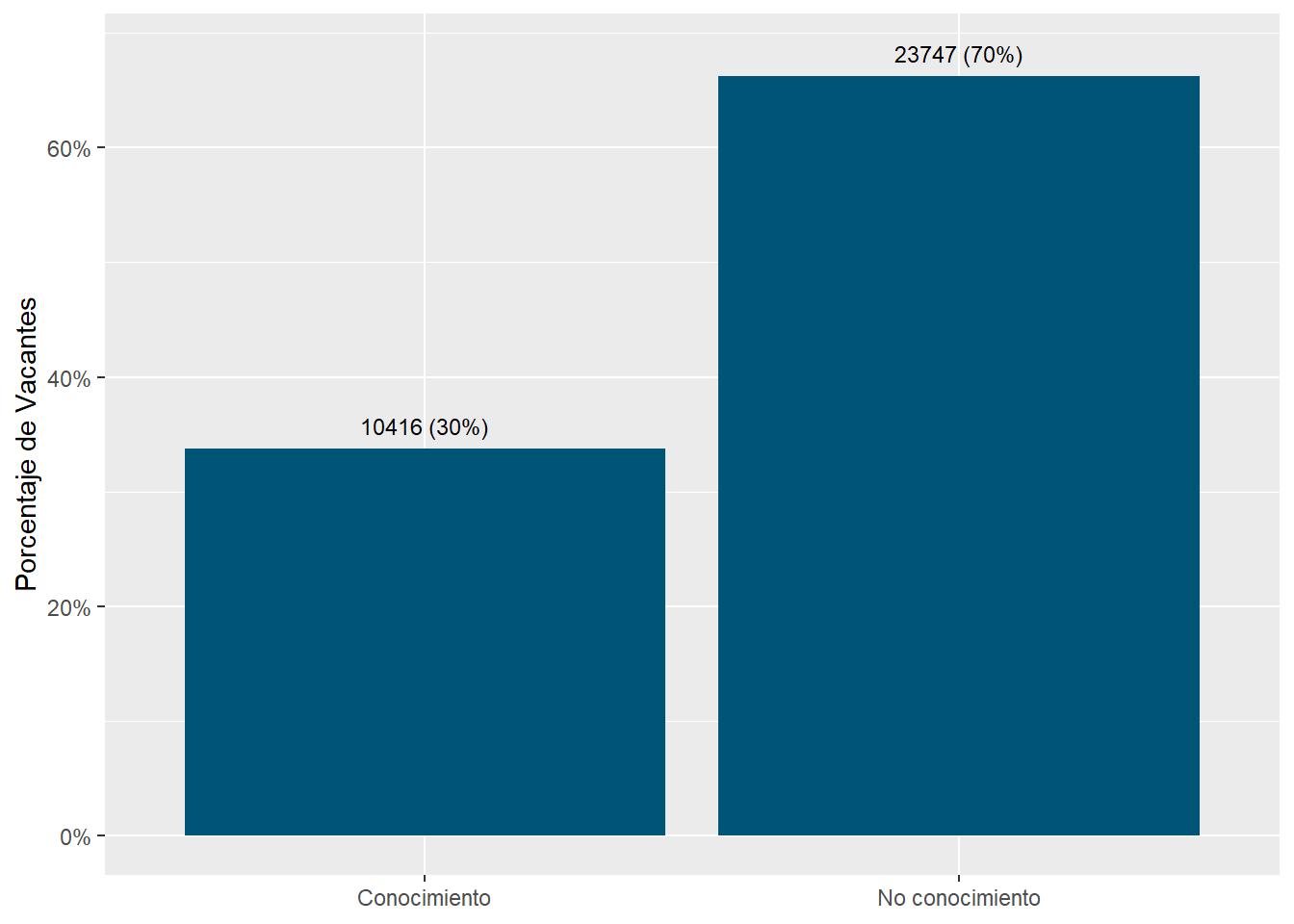
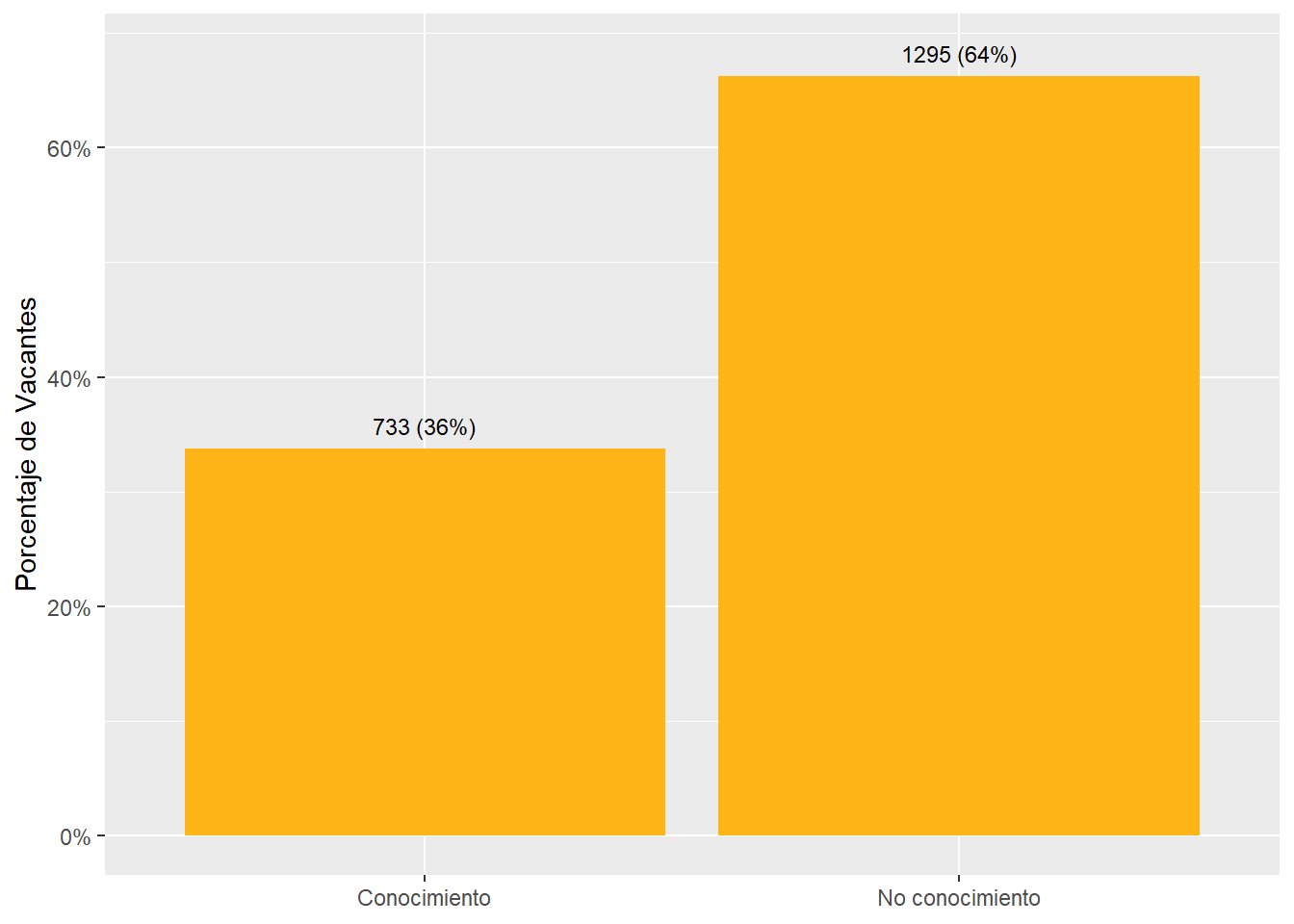
country_var_chart(area_country_df_1,category ="area",country="country_code")[[2]]+scale_fill_manual(values=country_colors)+labs(subtitle="Knowledge sector distribution in online vacancies data",x=NULL,fill=NULL)country_var_chart(area_country_df_1,category ="area",country="country_code")[[3]]+scale_fill_manual(values=country_colors)+labs(subtitle="Knowledge sector distribution in online vacancies data",x=NULL,fill=NULL)
Figure 45: TRUE
Figure 46: TRUE
Knowledge jobs across occupations
Code
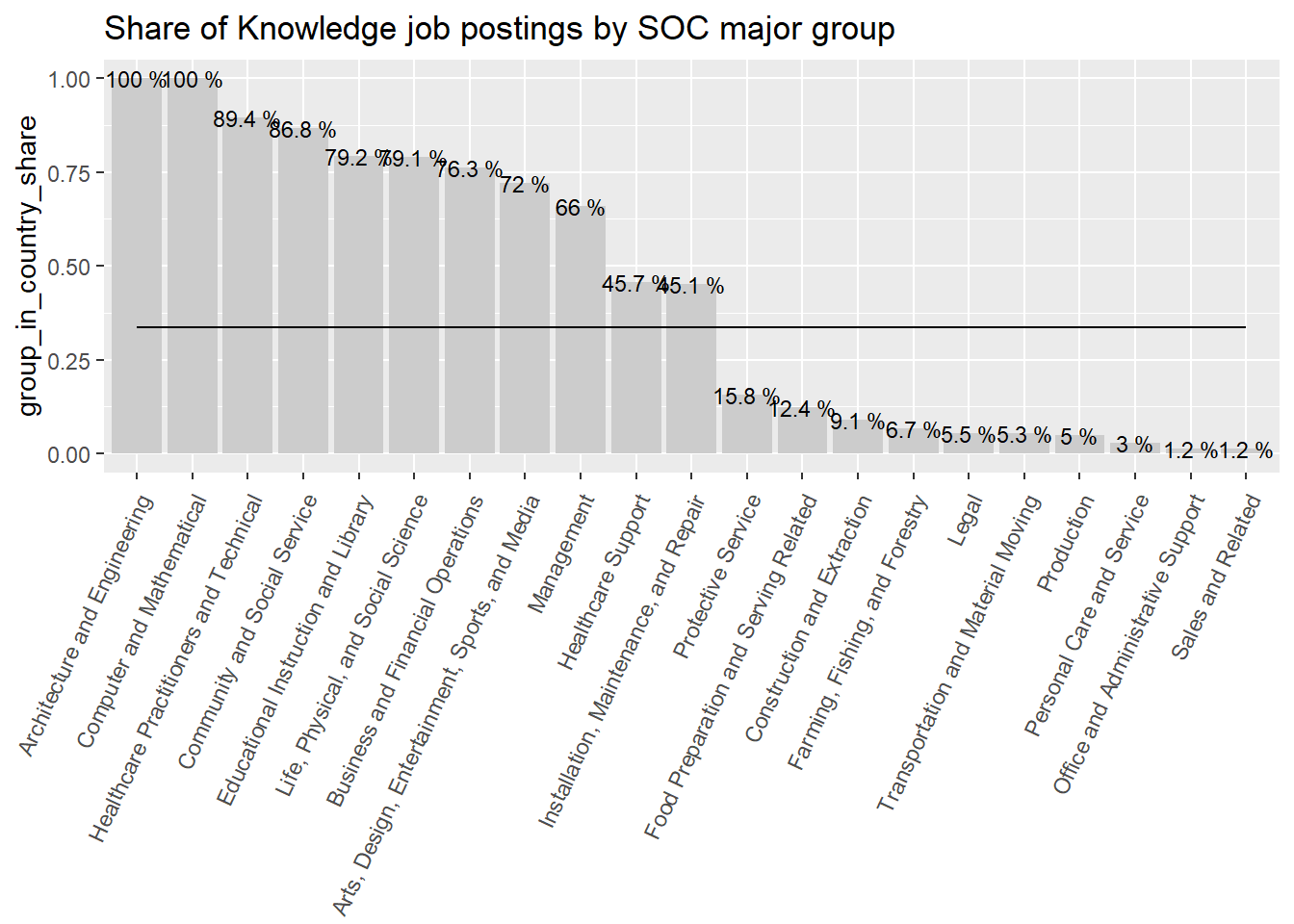
area_df_2<-country_var_count(data = south_cone_df,category ="area",country="major_group_title")area_df_3<-rbind(country_var_count(data =filter(south_cone_df,country_code=="ARG"),category ="area",country="major_group_title") %>%mutate(country_code="ARG"),country_var_count(data =filter(south_cone_df,country_code=="CHL"),category ="area",country="major_group_title")%>%mutate(country_code="CHL"),country_var_count(data =filter(south_cone_df,country_code=="URY"),category ="area",country="major_group_title")%>%mutate(country_code="URY") )%>%# I don't need the share of area jobs in each country.select(-group_vacancies,-group_share) %>%# I want only area shares of the knowledge groups in each countryfilter(area=="Conocimiento") area_df_2 %>%filter(area=="Conocimiento") %>%ggplot(aes(x=reorder(str_remove(major_group_title,"Occupations"),-group_in_country_share),y=group_in_country_share))+geom_col(fill="gray80")+geom_line(aes(y=group_share,group=area))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of Knowledge job postings by SOC major group",x=NULL)
Figure 47: ?(caption)
Code
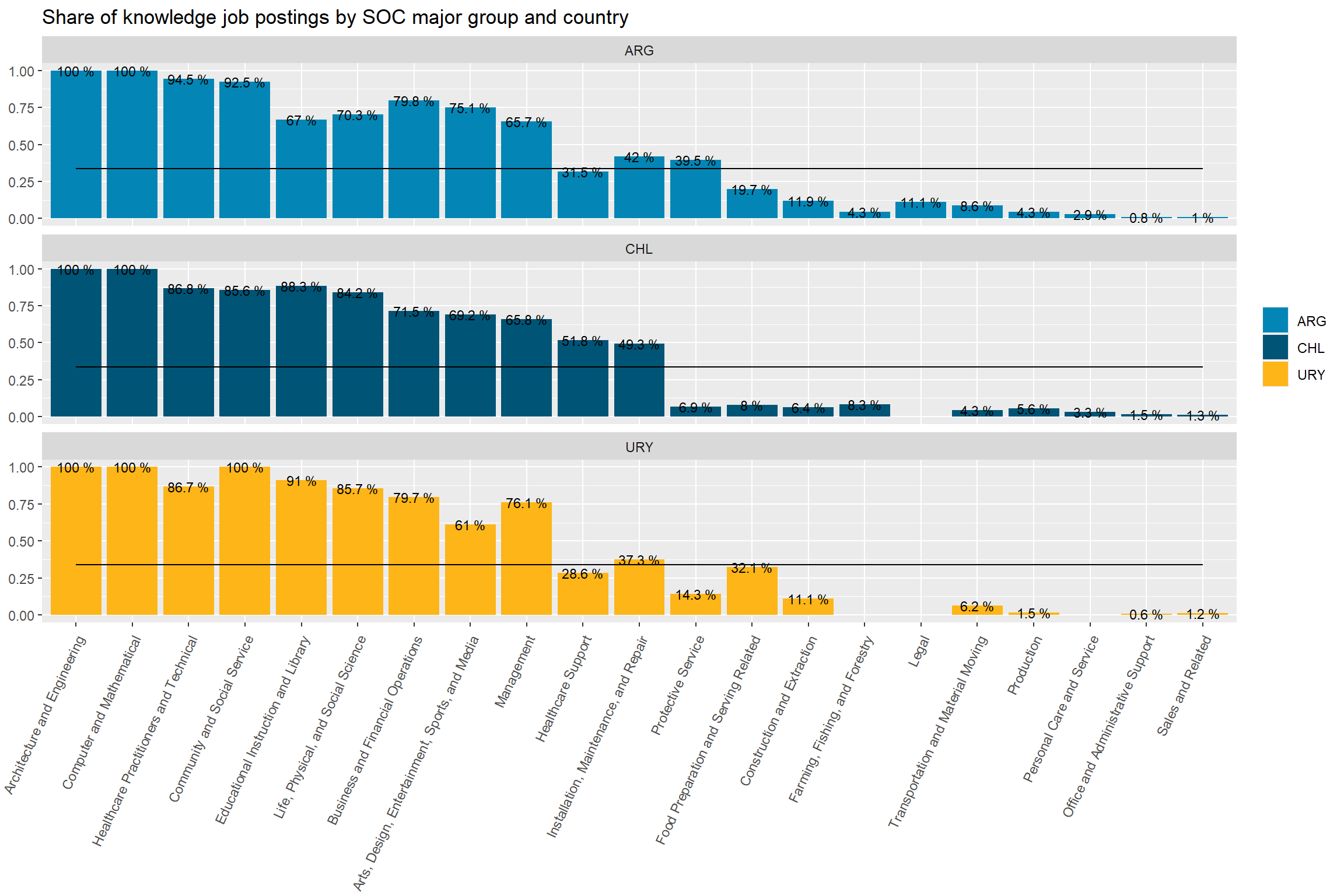
area_df_3 %>%# attach the share of remote vacancies in each group left_join(area_df_2 %>%filter(area=="Conocimiento") %>%select(major_group_title,share_of_remote_in_group=group_in_country_share, group_share)) %>%# plot the share of remote vacancies in each group, by countryggplot(aes(x=reorder(str_remove(major_group_title,"Occupations"),-share_of_remote_in_group),y=group_in_country_share))+geom_col(aes(fill=country_code))+geom_line(aes(y=group_share,group=area))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+scale_fill_manual(values=country_colors)+facet_wrap(vars(country_code),ncol=1) +theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of knowledge job postings by SOC major group and country",x=NULL,y=NULL,fill=NULL)
Figure 48: ?(caption)
Knowledge jobs across industries
Code
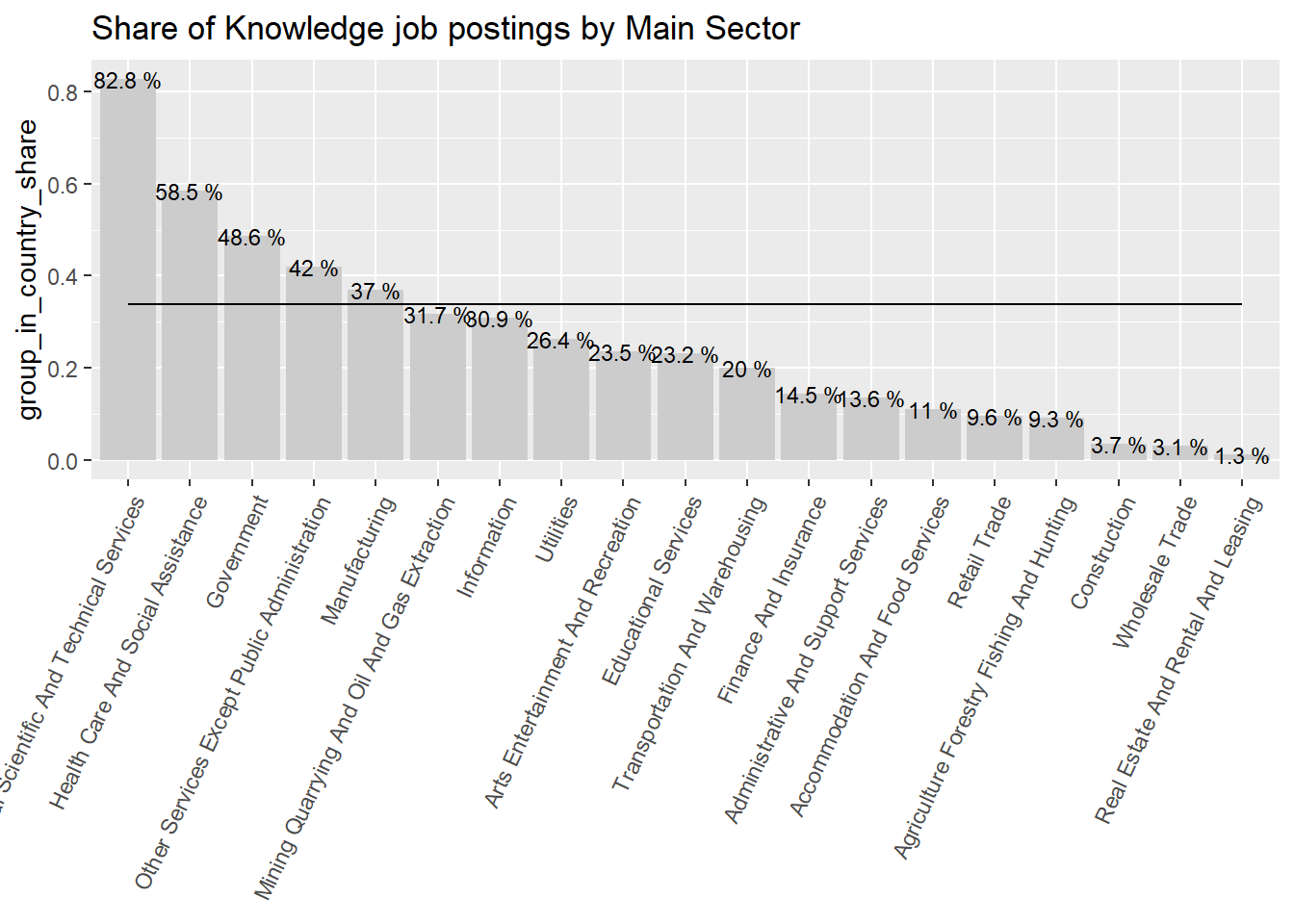
area_sector_df<-country_var_count(data = south_cone_df ,category ="area",country="main_sector")area_sector_df %>%filter(area=="Conocimiento") %>%ggplot(aes(x=reorder(main_sector,-group_in_country_share),y=group_in_country_share))+geom_col(fill="gray80")+geom_line(aes(y=group_share,group=area))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of Knowledge job postings by Main Sector",x=NULL)
Figure 49: ?(caption)
Code
area_sector_country_df<-rbind(country_var_count(data =filter(south_cone_df ,country_code=="ARG"),category ="area",country="main_sector") %>%mutate(country_code="ARG"),country_var_count(data =filter(south_cone_df ,country_code=="CHL"),category ="area",country="main_sector")%>%mutate(country_code="CHL"),country_var_count(data =filter(south_cone_df ,country_code=="URY"),category ="area",country="main_sector")%>%mutate(country_code="URY") )%>%# I don't need the share of area jobs in each country.select(-group_vacancies,-group_share) %>%# I want only area shares of the knowledge groups in each countryfilter(area=="Conocimiento") area_sector_country_df %>%# attach the share of remote vacancies in each group left_join(area_sector_df %>%filter(area=="Conocimiento") %>%select(main_sector,share_of_remote_in_group=group_in_country_share, group_share)) %>%# plot the share of remote vacancies in each group, by countryggplot(aes(x=reorder(main_sector,-share_of_remote_in_group),y=group_in_country_share))+geom_col(aes(fill=country_code))+geom_line(aes(y=group_share,group=area))+geom_text(aes(label=paste(round(group_in_country_share,3)*100,"%")), size=3)+scale_fill_manual(values=country_colors)+facet_wrap(vars(country_code),ncol=1) +theme(axis.text.x =element_text(angle =65, hjust=1))+labs(title ="Share of knowledge job postings by Main Sector and country",x=NULL,y=NULL,fill=NULL)
Figure 50: ?(caption)
Location of Knowledge jobs across regions
Code
country_var_count(data=south_cone_df,category ="rm",country="area") %>%arrange(desc(group_vacancies)) %>%filter(area=="Conocimiento") %>%mutate(ratio=round(group_in_country_share/group_share,2)) %>%mutate(share=scales::percent(group_in_country_share,accuracy=2),group_share=scales::percent(group_share, accuracy=2)) %>%arrange(desc(group_vacancies)) %>%filter(group_vacancies>500) %>%ungroup() %>%select(Region=rm,`Job postings`=group_vacancies,`% in all data`=group_share,`% in knowledge jobs`=share,Ratio=ratio) %>%head(15) %>% kableExtra::kable()
?(caption)
Region
Job postings
% in all data
% in knowledge jobs
Ratio
Santiago
13725
24%
20%
0.86
Buenos Aires (GZM)
9313
16%
16%
1.07
Valparaíso
4932
8%
8%
0.88
Concepción
3774
6%
6%
0.93
Rosario
2316
4%
4%
1.14
Gran Temuco
2125
4%
4%
0.91
Coquimbo
1913
4%
2%
0.88
Córdoba
1810
4%
4%
1.17
Mendoza
1734
2%
4%
1.18
Antofagasta
1477
2%
4%
1.27
Puerto Montt
1251
2%
2%
0.97
Metropolitana
1220
2%
2%
1.10
Tarapacá
1168
2%
2%
1.16
Corrientes
1074
2%
2%
1.21
Región Metropolitana Confluencia
889
2%
2%
1.29
Regions
There are three geographic aggregation variables in the data. This is the count of unique, missing, and empty values each of these indicator has.
This is a look at the most frequent values of ‘city’ and ‘city_name’ in Chile:
city evidently has low levels of details within Santiago and Valparaiso Regions.
city_name has more granularity, but there are lots of cases where it defaults to region name (when it doesn’t guess a city name, imputes the Region name)
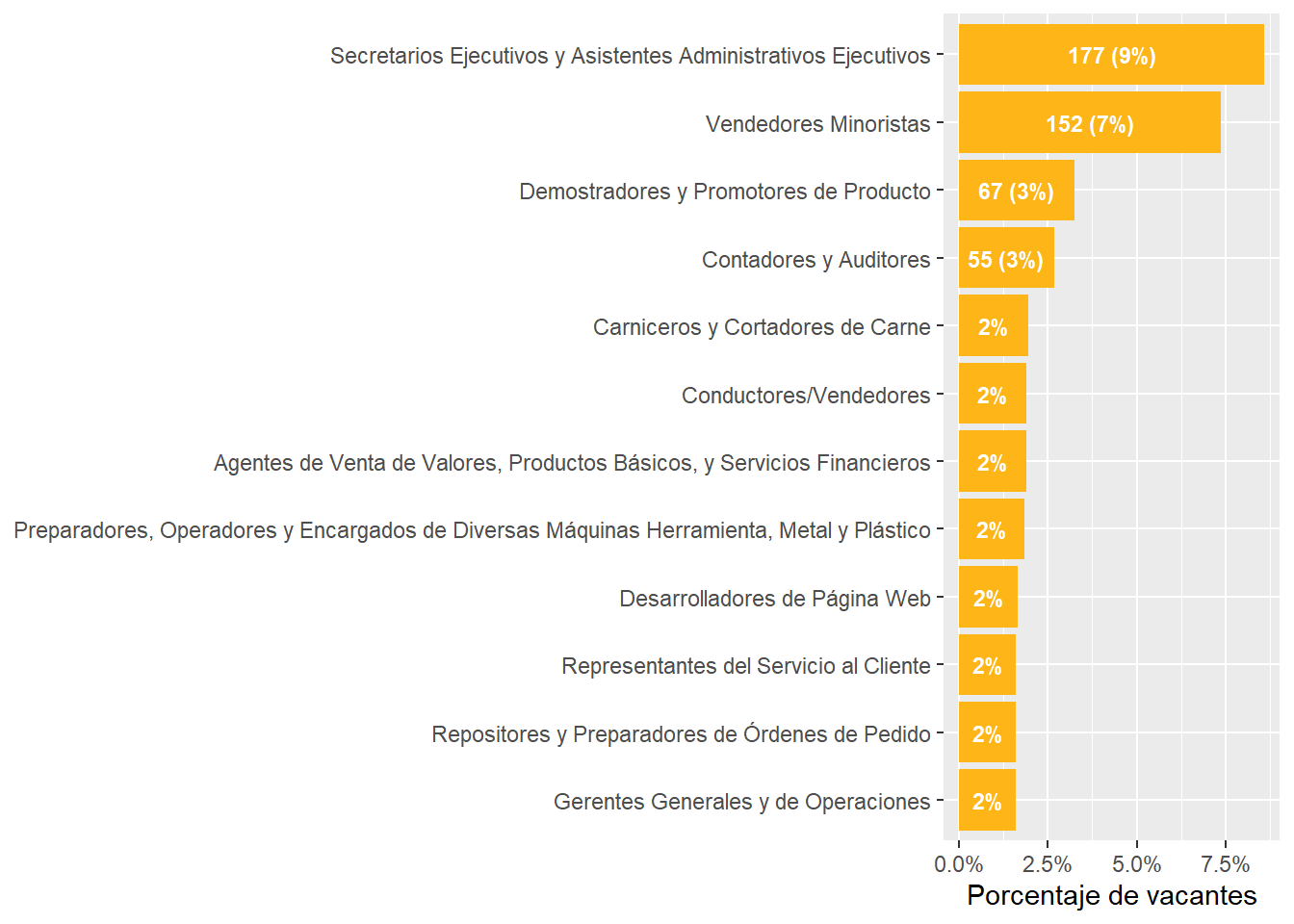
Which are the most important firms across countries and regions?
Emprego en Argentina, Confidencial en Chile, Gallito Trabajo en Uruguay.
HR agencies seem to represent most of the postings (at least this month).
There are many cases where they list the place of the vacancy instead of the company. Mostly in Argentina.
Code
country_var_count(data = south_cone_df, country ="country_code",category ="firm") %>%country_region_table(country ="country_code",category ="firm",top_number =10)
?(caption)
rank
ARG
CHL
URY
1
Emprego, 2447 (10.6%)
Confidencial, 2130 (6.2%)
Gallito Trabajo, 88 (4.3%)
2
Confidencial, 748 (3.2%)
Progestion Chile, 890 (2.6%)
ManpowerGroup, 61 (3%)
3
Mendoza, Capital, Mendoza, Argentina, 327 (1.4%)
Adecco Chile, 678 (2%)
Inclusion Cloud, 48 (2.4%)
4
Adecco Argentina S.A., 261 (1.1%)
Manpower Chile, 677 (2%)
Superprof, 33 (1.6%)
5
Grupo Gestión, 259 (1.1%)
Fundación Integra, 575 (1.7%)
Aldeas Infantiles SOS Uruguay, 30 (1.5%)
6
ManpowerGroup, 230 (1%)
Cygnus, 569 (1.7%)
Advice, 26 (1.3%)
7
Buenos Aires, CABA, Argentina, 225 (1%)
ACTIVOS CHILE, 448 (1.3%)
Adecco, 25 (1.2%)
8
Tusclases, 214 (0.9%)
Eurofirms Chile, 432 (1.3%)
confidential, 24 (1.2%)
9
LatinHire, 198 (0.9%)
XinerLink, 416 (1.2%)
Randstad Uruguay, 22 (1.1%)
10
Wurth Argentina S.a, 132 (0.6%)
Walmart Chile, 296 (0.9%)
Securitas Uruguay, 22 (1.1%)
Which are the most important firms in the most demanded roles:
Code
top_occupations<-c(# "Architecture and Engineering Occupations","Sales and Related Occupations",# "Healthcare Practitioners and Technical Occupations","Computer and Mathematical Occupations","Business and Financial Operations Occupations","Office and Administrative Support Occupations" )country_var_count(data = south_cone_df %>%filter(major_group_title %in% top_occupations) %>%mutate(major_group_title=str_remove(major_group_title," Occupations")), country ="major_group_title",category ="firm") %>%country_region_table(country ="major_group_title",category ="firm",top_number =10)
rank
Business and Financial Operations
Computer and Mathematical
Office and Administrative Support
Sales and Related
1
Emprego, 251 (5.3%)
Emprego, 116 (4.6%)
Confidencial, 438 (4.9%)
Confidencial, 453 (4.8%)
2
Confidencial, 212 (4.5%)
Confidencial, 96 (3.8%)
Emprego, 417 (4.6%)
Emprego, 440 (4.7%)
3
Progestion Chile, 51 (1.1%)
Recruiting from Scratch, 37 (1.5%)
Progestion Chile, 124 (1.4%)
Progestion Chile, 176 (1.9%)
4
Adecco Chile, 47 (1%)
Buenos Aires, CABA, Argentina, 36 (1.4%)
Adecco Chile, 112 (1.2%)
Adecco Chile, 113 (1.2%)
5
Mendoza, Capital, Mendoza, Argentina, 45 (1%)
Mendoza, Capital, Mendoza, Argentina, 34 (1.4%)
Fundación Integra, 107 (1.2%)
Manpower Chile, 108 (1.1%)
6
Buenos Aires, CABA, Argentina, 40 (0.9%)
Fundación Integra, 25 (1%)
Cygnus, 101 (1.1%)
Cygnus, 89 (0.9%)
7
Manpower Chile, 37 (0.8%)
Progestion Chile, 24 (1%)
Manpower Chile, 100 (1.1%)
Fundación Integra, 83 (0.9%)
8
ACTIVOS CHILE, 34 (0.7%)
Manpower Chile, 23 (0.9%)
ACTIVOS CHILE, 67 (0.7%)
XinerLink, 70 (0.7%)
9
Cygnus, 33 (0.7%)
Adecco Chile, 20 (0.8%)
Eurofirms Chile, 63 (0.7%)
Eurofirms Chile, 56 (0.6%)
10
Adecco Argentina S.A., 28 (0.6%)
Eurofirms Chile, 18 (0.7%)
XinerLink, 59 (0.7%)
ManpowerGroup, 55 (0.6%)
11
Fundación Integra, 28 (0.6%)
Inclusion Cloud, 18 (0.7%)
NA
NA
Which are the most important firms in the most active sectors:
Code
top_sectors<-c("Professional Scientific And Technical Services","Finance And Insurance","Retail Trade","Manufacturing")country_var_count(data = south_cone_df %>%filter(main_sector %in% top_sectors), country ="main_sector",category ="firm") %>%country_region_table(country ="main_sector",category ="firm",top_number =10)
rank
Finance And Insurance
Manufacturing
Professional Scientific And Technical Services
Retail Trade
1
Emprego, 157 (5.2%)
Confidencial, 539 (4.9%)
Emprego, 402 (4.7%)
Confidencial, 485 (5.3%)
2
Confidencial, 128 (4.3%)
Emprego, 483 (4.4%)
Confidencial, 367 (4.3%)
Emprego, 340 (3.7%)
3
Mendoza, Capital, Mendoza, Argentina, 35 (1.2%)
Adecco Chile, 168 (1.5%)
Progestion Chile, 97 (1.1%)
Progestion Chile, 197 (2.1%)
4
Progestion Chile, 33 (1.1%)
Manpower Chile, 162 (1.5%)
Buenos Aires, CABA, Argentina, 95 (1.1%)
Adecco Chile, 113 (1.2%)
5
Adecco Chile, 31 (1%)
Progestion Chile, 149 (1.4%)
Adecco Chile, 90 (1.1%)
Manpower Chile, 108 (1.2%)
6
Cygnus, 23 (0.8%)
ACTIVOS CHILE, 121 (1.1%)
Manpower Chile, 83 (1%)
Cygnus, 106 (1.2%)
7
Buenos Aires, CABA, Argentina, 22 (0.7%)
Cygnus, 110 (1%)
Mendoza, Capital, Mendoza, Argentina, 81 (1%)
Fundación Integra, 106 (1.2%)
8
Manpower Chile, 22 (0.7%)
Fundación Integra, 85 (0.8%)
Fundación Integra, 65 (0.8%)
Eurofirms Chile, 74 (0.8%)
9
Fundación Integra, 21 (0.7%)
XinerLink, 81 (0.7%)
Eurofirms Chile, 56 (0.7%)
ACTIVOS CHILE, 71 (0.8%)
10
ManpowerGroup, 21 (0.7%)
Eurofirms Chile, 77 (0.7%)
Recruiting from Scratch, 56 (0.7%)
XinerLink, 71 (0.8%)
How concentrated are online vacancies within firms across different regions?
Code
south_cone_df %>%group_by(country_code,firm) %>%summarise(count=n()) %>%group_by(country_code) %>%mutate(share=count/sum(count)) %>%arrange(country_code,desc(count)) %>%mutate(cum_share=cumsum(share),rank=row_number()) %>%top_n(100,-rank) %>%ggplot(aes(x=rank,y=cum_share,group=country_code,,color=country_code))+geom_point()+geom_line()+scale_color_manual(values=country_colors)+geom_label_repel(aes(label=ifelse(rank %in%c(1,2,20, 50, 70, 100),substr(firm,1,20),NA)),size=2)+labs(title="Cummulative share of vacancies by in 100 largest firms",subtitle="Vacancies in Chile and Argentina are similarly\nconcentrated within the first 100 firms",color=NULL,y="Share of country vacancies",x="Firm ranking (from largest to smallest)")
Figure 51: ?(caption)
Representativity Assessment (Work in progress)
Which occupations and sectors are over(under)represented in each country? We’ll compare vacancies data to Employment estimates in employment or household surveys to figure it out.
Comparing against ILOSTAT data by occupation
ILOSTAT data contains tables of employment at the ISCO 08 2-digits level. Samples for Chile and Uruguay managed to classify all occupations from the original surveys, while the Argentina’s failed to assign an ISCO 08 code to 16% of employment in the original sample.
The table below shows the correlation between employment and online job vacancies distributions.
Code
correlations() %>%gt() %>%fmt_percent('estimate') %>%tab_header(title="Correlation between employment and online vacancies distributions",subtitle="Estimates correspond to Pearson's correlation coefficietns")
Correlation between employment and online vacancies distributions
Estimates correspond to Pearson's correlation coefficietns
estimate
statistic
group
41.28%
3.625998
Total
45.13%
2.261776
ARG
42.50%
2.099956
CHL
41.26%
2.025881
URY
These tables show the detailed distributions behind these correlations.
sector_emp<-latest_country_EC2d %>%left_join(naics_isic_2d_fixed ,by=c("EC2d"="isic_code")) %>%# there are many naics for the same isic. we avoid double counting by splitting employmentgroup_by(country_code,EC2d) %>%mutate(n_naics_outputs=n()) %>%# we calculate employment by country and naics.group_by(naics_2d, naics_2d_desc) %>%summarise(employment=sum(obs_value/n_naics_outputs,na.rm = T)) %>%# we calculate employment shareungroup() %>%mutate(employment_share=employment/sum(employment)) %>%# format variable in a specific way in order to match bid datamutate(main_sector=str_remove_all(naics_2d_desc,","),main_sector=str_remove_all(main_sector,"[()]"),main_sector=str_to_title(main_sector)) sector_country_emp<-latest_country_EC2d %>%left_join(naics_isic_2d_fixed ,by=c("EC2d"="isic_code")) %>%# there are many naics for the same isic. we avoid double counting by splitting employmentgroup_by(country_code,EC2d) %>%mutate(n_naics_outputs=n()) %>%# we calculate employment by country and naics.group_by(country_code,naics_2d, naics_2d_desc) %>%summarise(employment=sum(obs_value/n_naics_outputs,na.rm = T)) %>%# we calculate employment sharegroup_by(country_code) %>%mutate(employment_share=employment/sum(employment)) %>%ungroup() %>%# format variable in a specific way in order to match bid datamutate(main_sector=str_remove_all(naics_2d_desc,","),main_sector=str_remove_all(main_sector,"[()]"),main_sector=str_to_title(main_sector))c('total in ILOSTAT'=sum(latest_country_EC2d$obs_value,na.rm = T),'total after crosswalk'=sum(sector_emp$employment),'total after crosswalk (country)'=sum(sector_country_emp$employment))sector_country_emp<-sector_country_emp %>%left_join(country_var_count(data = south_cone_df,country ='country_code',category ='main_sector'), by=c("country_code","main_sector")) %>%mutate(gap=(group_in_country_share/employment_share))sector_emp<-sector_country_emp%>%group_by(naics_2d,main_sector) %>%summarise(employment=sum(employment,na.rm = T),count=sum(count)) %>%ungroup() %>%mutate(employment_share=employment/sum(employment,na.rm = T),group_in_country_share=count/sum(count,na.rm = T),gap=(group_in_country_share/employment_share))
The table below shows the correlation between employment and online job vacancies distributions.
Code
correlations(data = sector_country_emp) %>%gt() %>%fmt_percent('estimate') %>%tab_header(title="Correlation between employment and online vacancies distributions",subtitle="Estimates correspond to Pearson's correlation coefficietns")
Correlation between employment and online vacancies distributions
Estimates correspond to Pearson's correlation coefficietns
library(readxl)chile_raw <-read_excel("raw/chl_macro/Cuadro_18122023133746.xlsx", sheet ="Cuadro", skip =2)%>% janitor::clean_names()# CEPAL: Producto interno bruto (PIB) anual por actividad económica a precios corrientes en dólares (Millones de dólares)# https://statistics.cepal.org/portal/cepalstat/dashboard.html?theme=2&lang=es# CEPAL / Comisión Económica para América Latina y el Caribe / Estimaciones basadas en fuentes oficialescepal_raw <-read_excel("raw/cepal/data_1703074551.xlsx")%>% janitor::clean_names()%>%mutate(country_code=case_when(pais_estandar=="Argentina"~"ARG", pais_estandar=="Chile"~"CHL", pais_estandar=="Uruguay"~"URY"))%>%left_join(sector_rubro%>%distinct(rubro,rubro_resumen),c("rubro_sector_cuentas_nacionales_anuales"="rubro"))print("Uruguay tiene un sector menos: explotacion de minas y canteras (incluye extraccion de petroleo crudo y gas natural")
[1] "Uruguay tiene un sector menos: explotacion de minas y canteras (incluye extraccion de petroleo crudo y gas natural"
rubro_country_emp%>%filter(country_code=="CHL")%>%ggplot(aes(x=reorder(str_wrap(rubro_resumen,30),employment_share),y=employment_share))+geom_col(aes(fill=country_code))+coord_flip()+geom_text(aes(label=case_when(employment_share <1~paste0(round(employment_share,2)*100,"%"),TRUE~paste0(round(employment ) ," (",round(employment_share,2)*100,"%)")),y=employment_share/2),color="white",fontface="bold",size=3)+scale_fill_manual(values=country_colors, guide="none")+scale_y_continuous(labels=scales::percent_format())+labs(x=NULL,y="Porcentaje de empleo")
Code
rubro_country_emp%>%filter(country_code=="URY")%>%ggplot(aes(x=reorder(str_wrap(rubro_resumen,30),employment_share),y=employment_share))+geom_col(aes(fill=country_code))+coord_flip()+geom_text(aes(label=case_when(employment_share <1~paste0(round(employment_share,2)*100,"%"),TRUE~paste0(round(employment ) ," (",round(employment_share,2)*100,"%)")),y=employment_share/2),color="white",fontface="bold",size=3)+scale_fill_manual(values=country_colors, guide="none")+scale_y_continuous(labels=scales::percent_format())+labs(x=NULL,y="Porcentaje de empleo")
PIB y Empleo
Code
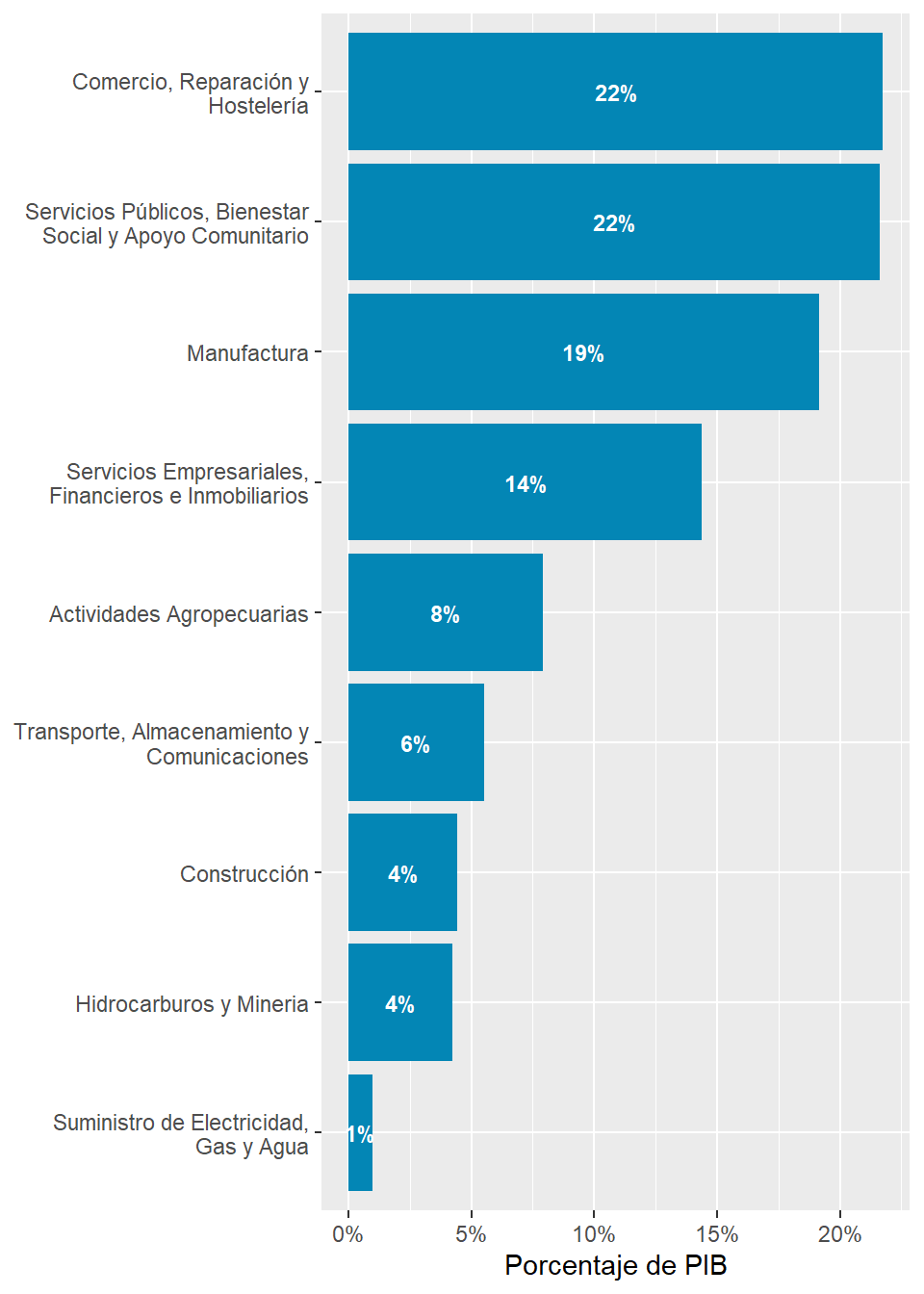
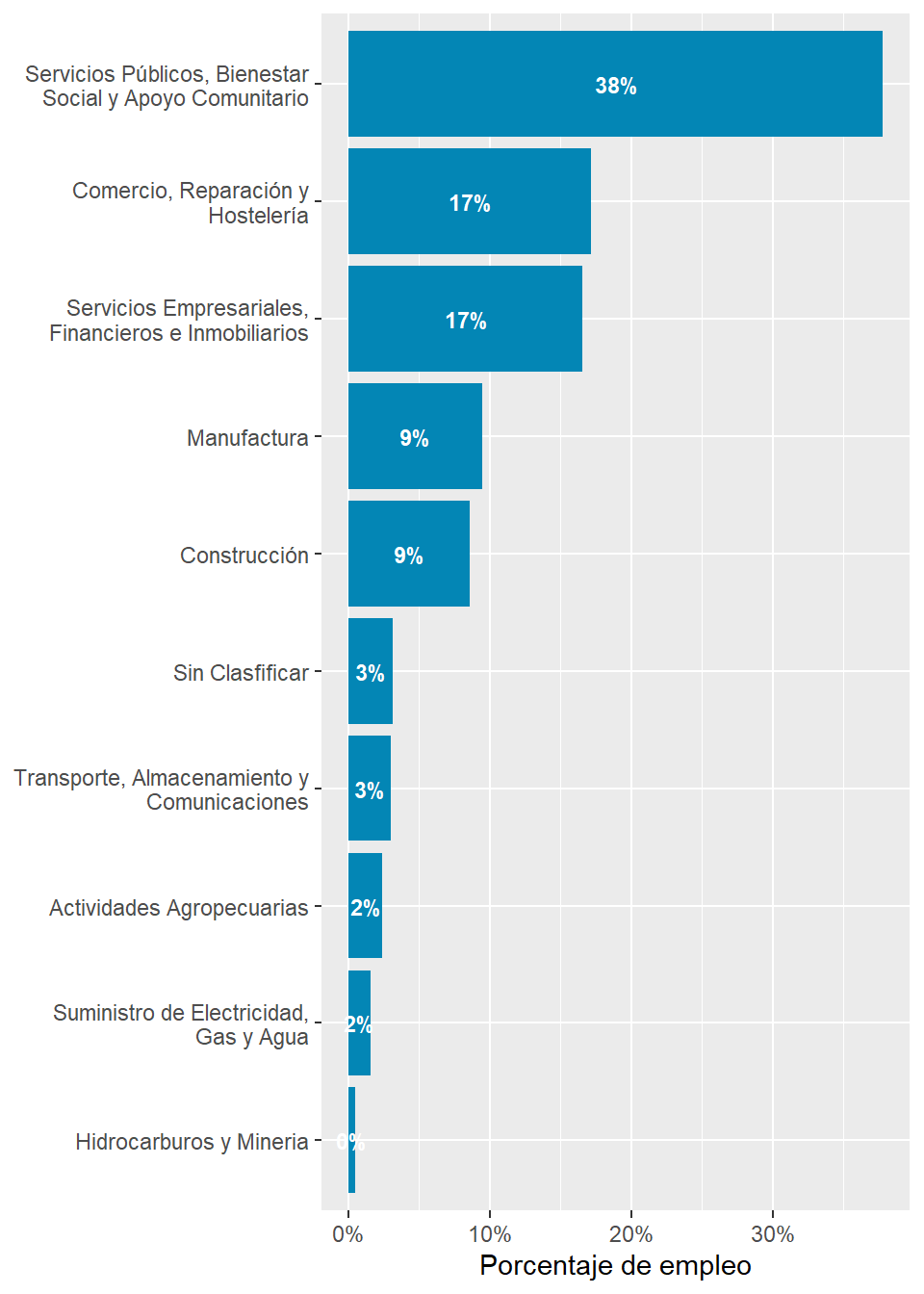
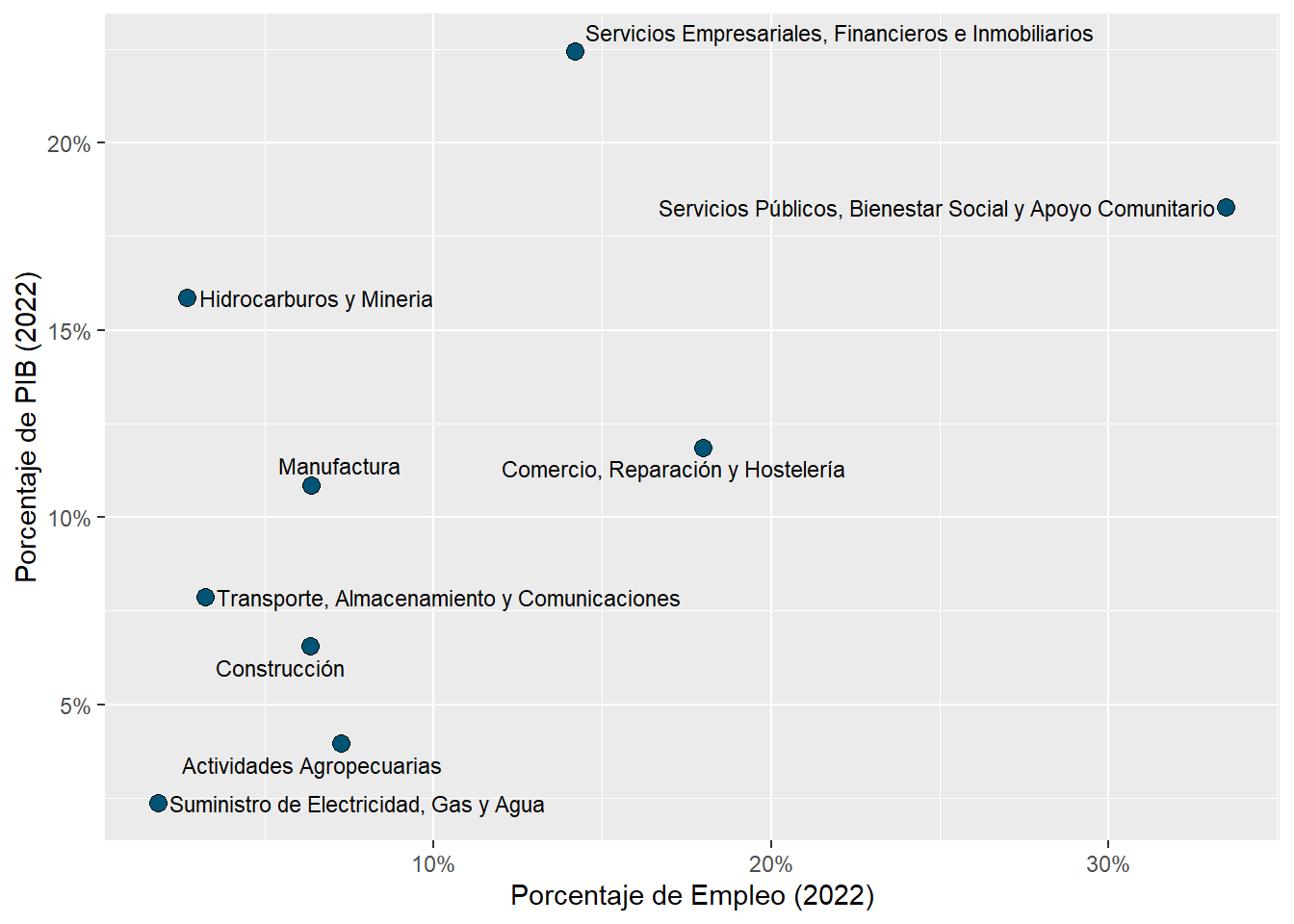
rubro_country_emp%>%ungroup()%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="ARG")%>%select(rubro_resumen,employment_share,share)%>%arrange(desc(share))%>% gt::gt()%>% gt::fmt_percent(columns =c("share","employment_share"))%>% gt::cols_label( .list =list("rubro_resumen"="Rubro","employment_share"="Porcentaje de Empleo","share"="Porcentaje de PIB" ))
Rubro
Porcentaje de Empleo
Porcentaje de PIB
Comercio, Reparación y Hostelería
17.12%
21.75%
Servicios Públicos, Bienestar Social y Apoyo Comunitario
37.78%
21.63%
Manufactura
9.44%
19.14%
Servicios Empresariales, Financieros e Inmobiliarios
16.56%
14.38%
Actividades Agropecuarias
2.41%
7.92%
Transporte, Almacenamiento y Comunicaciones
3.00%
5.51%
Construcción
8.59%
4.44%
Hidrocarburos y Mineria
0.46%
4.25%
Suministro de Electricidad, Gas y Agua
1.55%
0.98%
Sin Clasfificar
3.10%
NA
Code
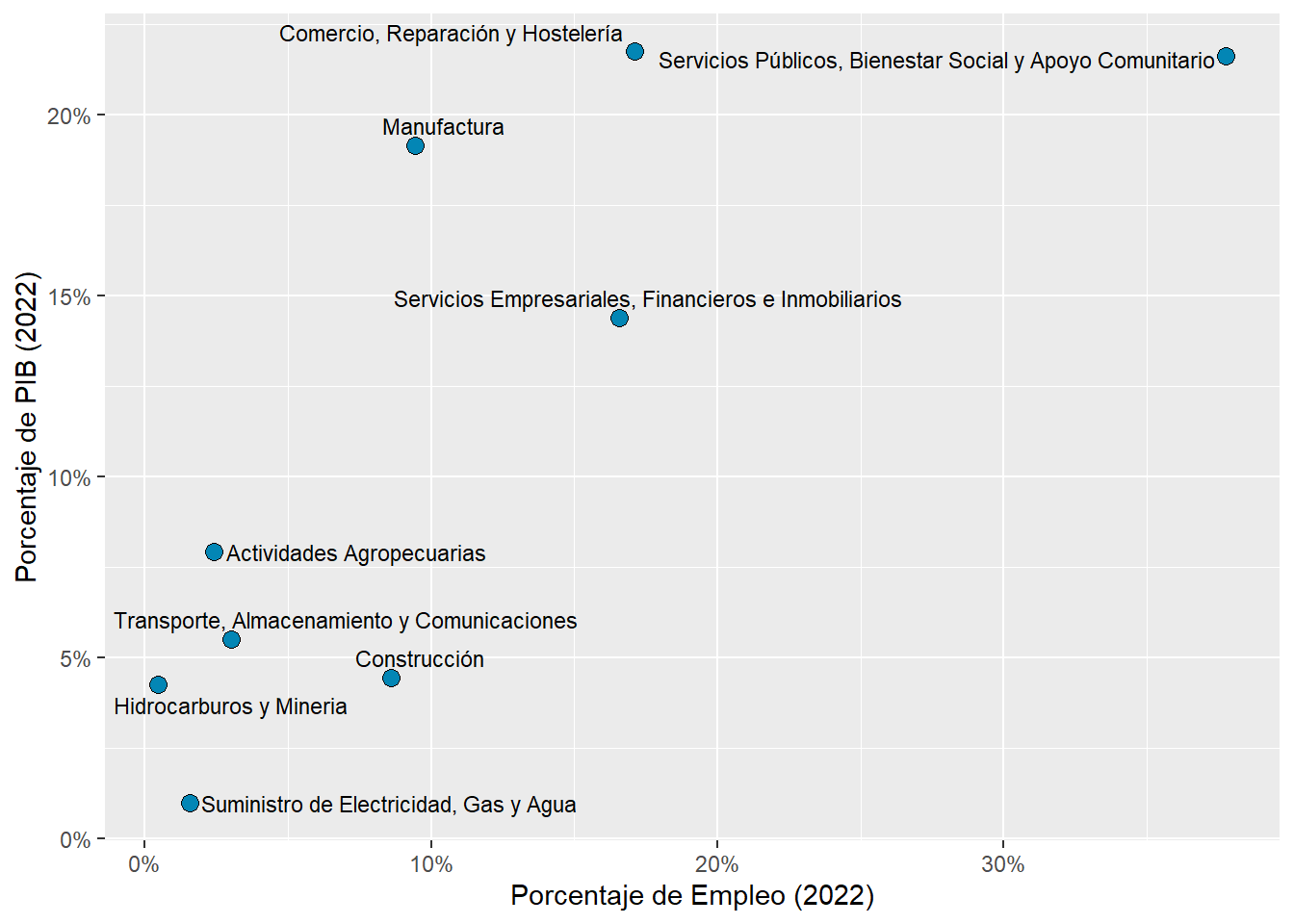
rubro_country_emp%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="ARG")%>%ggplot(aes(x=employment_share,y=share))+ ggrepel::geom_text_repel(aes(label=rubro_resumen),size=3)+geom_point(aes(fill=country_code),shape=21,size=3)+scale_fill_manual(values = country_colors, guide="none")+scale_y_continuous(labels=scales::percent_format())+scale_x_continuous(labels=scales::percent_format())+labs(y="Porcentaje de PIB (2022)",x="Porcentaje de Empleo (2022)")
Code
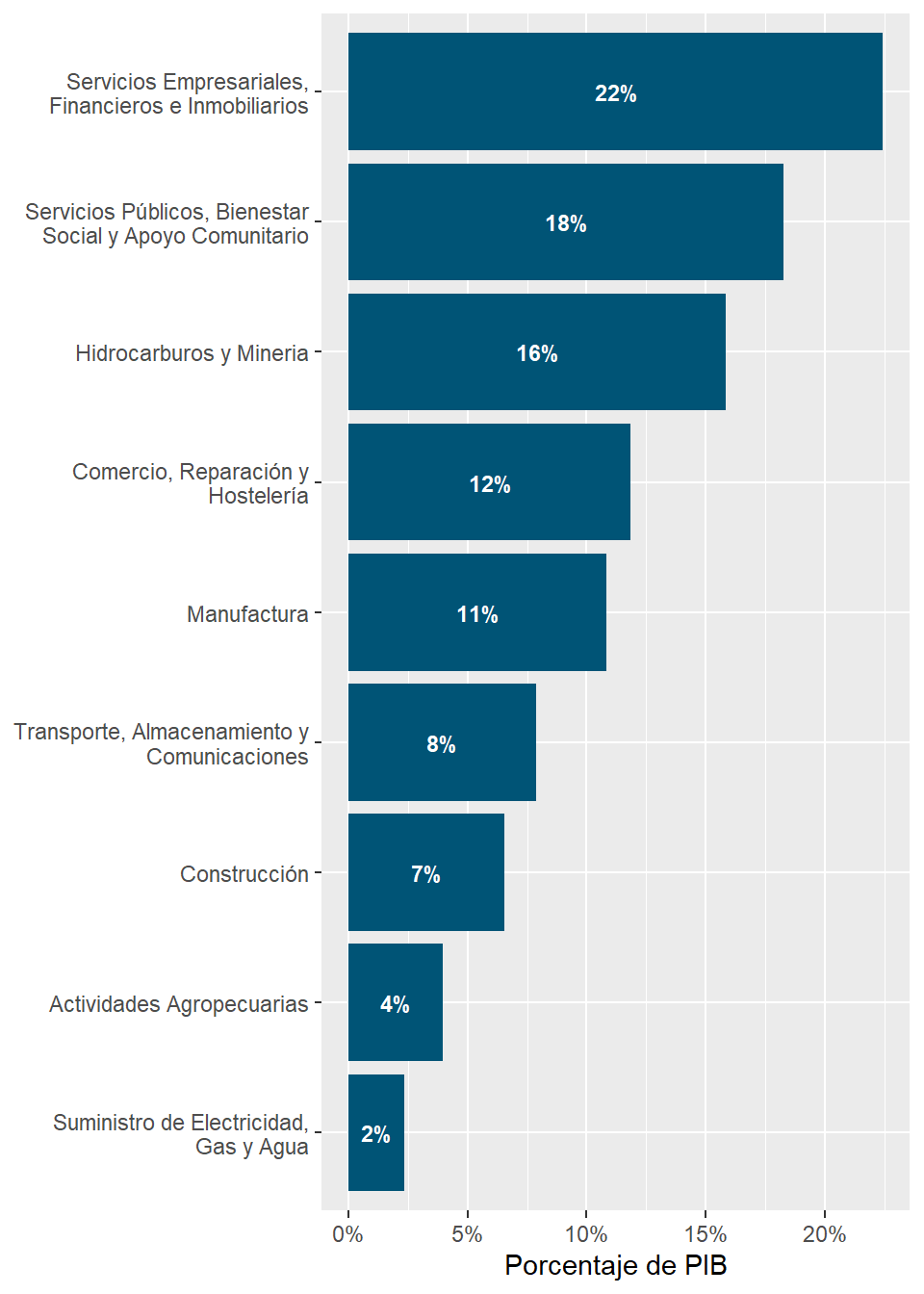
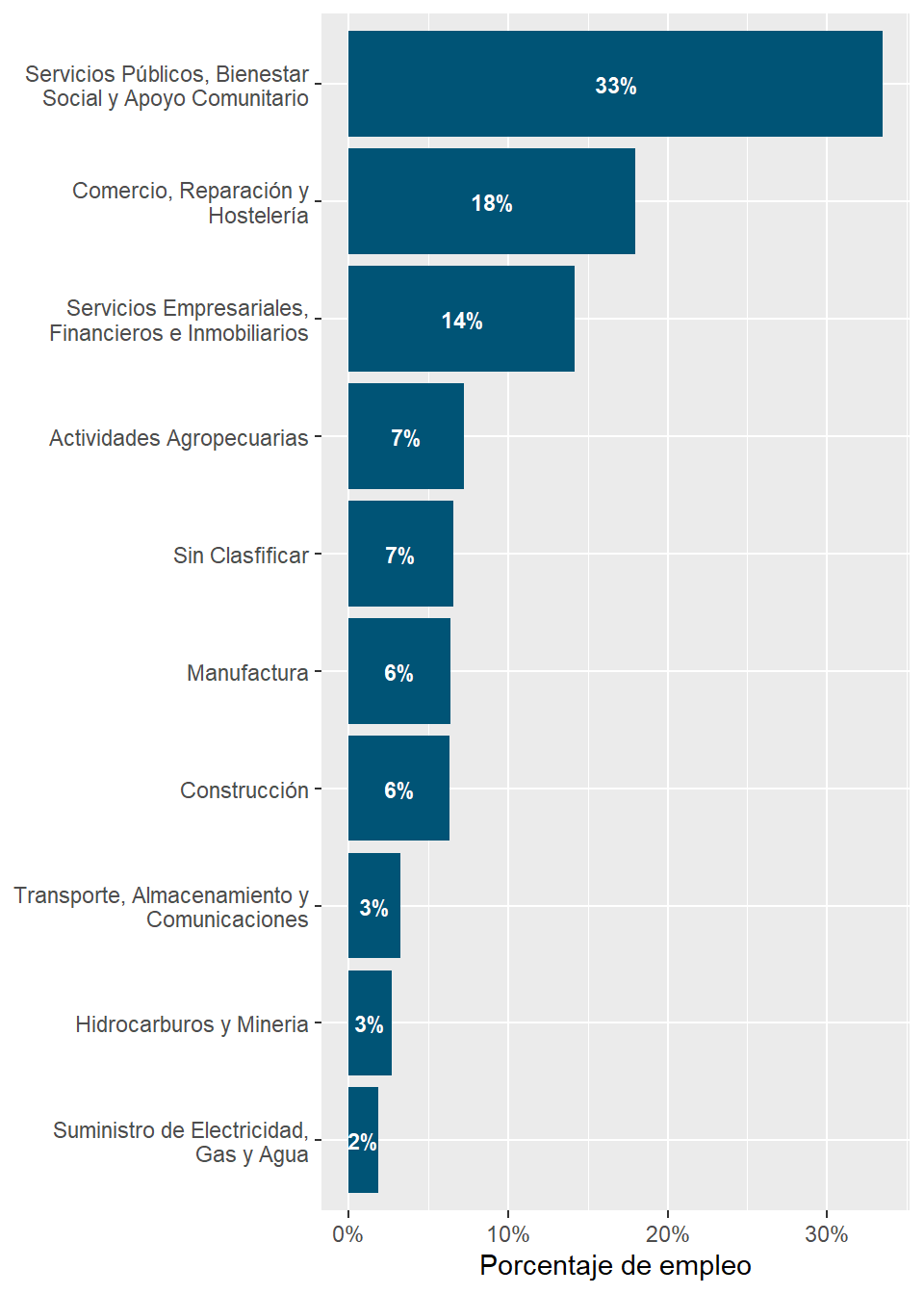
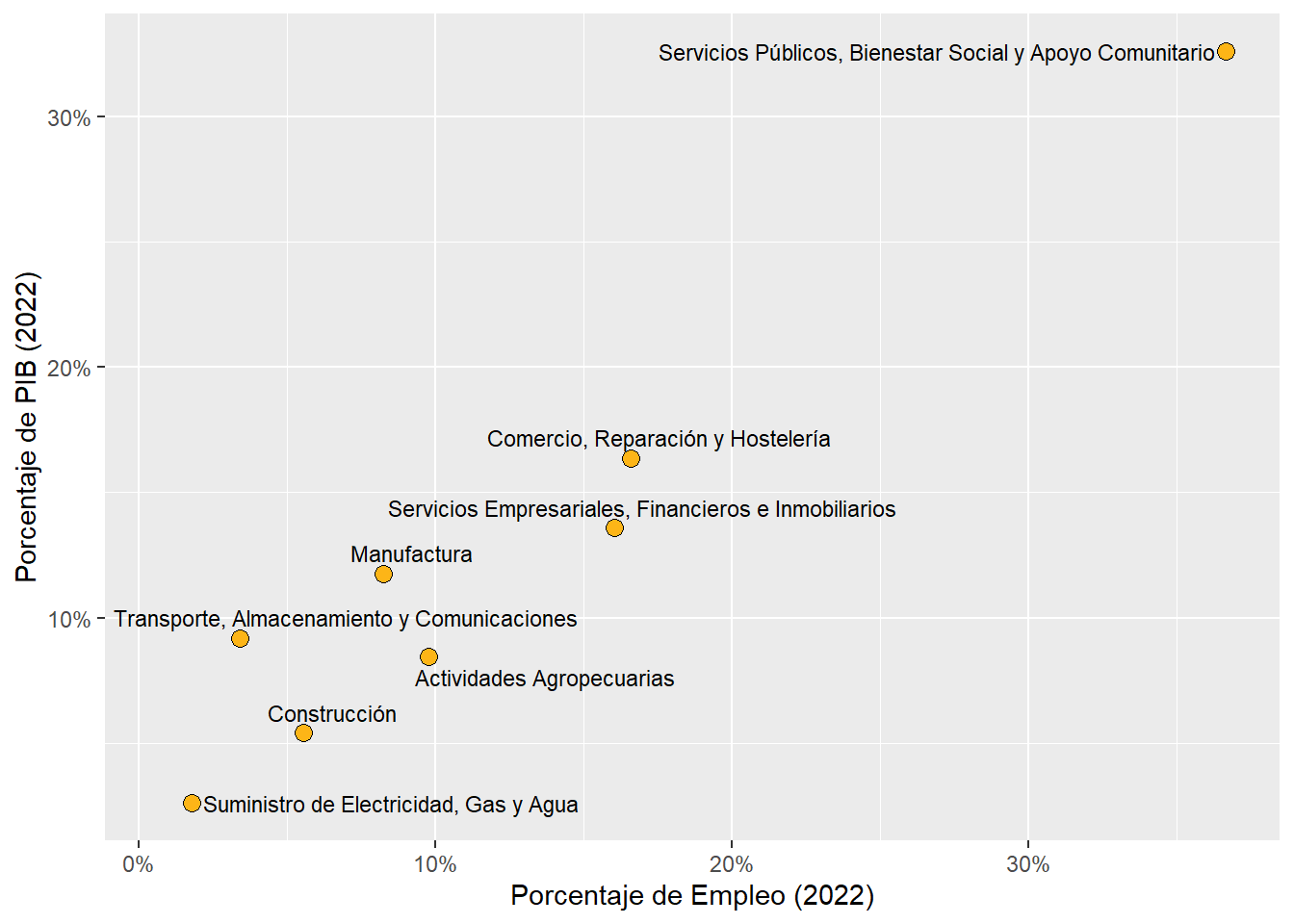
rubro_country_emp%>%ungroup()%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="CHL")%>%select(rubro_resumen,employment_share,share)%>%arrange(desc(share))%>% gt::gt()%>% gt::fmt_percent(columns =c("share","employment_share"))%>% gt::cols_label( .list =list("rubro_resumen"="Rubro","employment_share"="Porcentaje de Empleo","share"="Porcentaje de PIB" ))
Rubro
Porcentaje de Empleo
Porcentaje de PIB
Servicios Empresariales, Financieros e Inmobiliarios
14.19%
22.44%
Servicios Públicos, Bienestar Social y Apoyo Comunitario
33.49%
18.27%
Hidrocarburos y Mineria
2.71%
15.86%
Comercio, Reparación y Hostelería
17.99%
11.85%
Manufactura
6.38%
10.85%
Transporte, Almacenamiento y Comunicaciones
3.24%
7.88%
Construcción
6.34%
6.55%
Actividades Agropecuarias
7.26%
3.95%
Suministro de Electricidad, Gas y Agua
1.85%
2.36%
Sin Clasfificar
6.56%
NA
Code
rubro_country_emp%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="CHL")%>%ggplot(aes(x=employment_share,y=share))+ ggrepel::geom_text_repel(aes(label=rubro_resumen),size=3)+geom_point(aes(fill=country_code),shape=21,size=3)+scale_fill_manual(values = country_colors, guide="none")+scale_y_continuous(labels=scales::percent_format())+scale_x_continuous(labels=scales::percent_format())+labs(y="Porcentaje de PIB (2022)",x="Porcentaje de Empleo (2022)")
Code
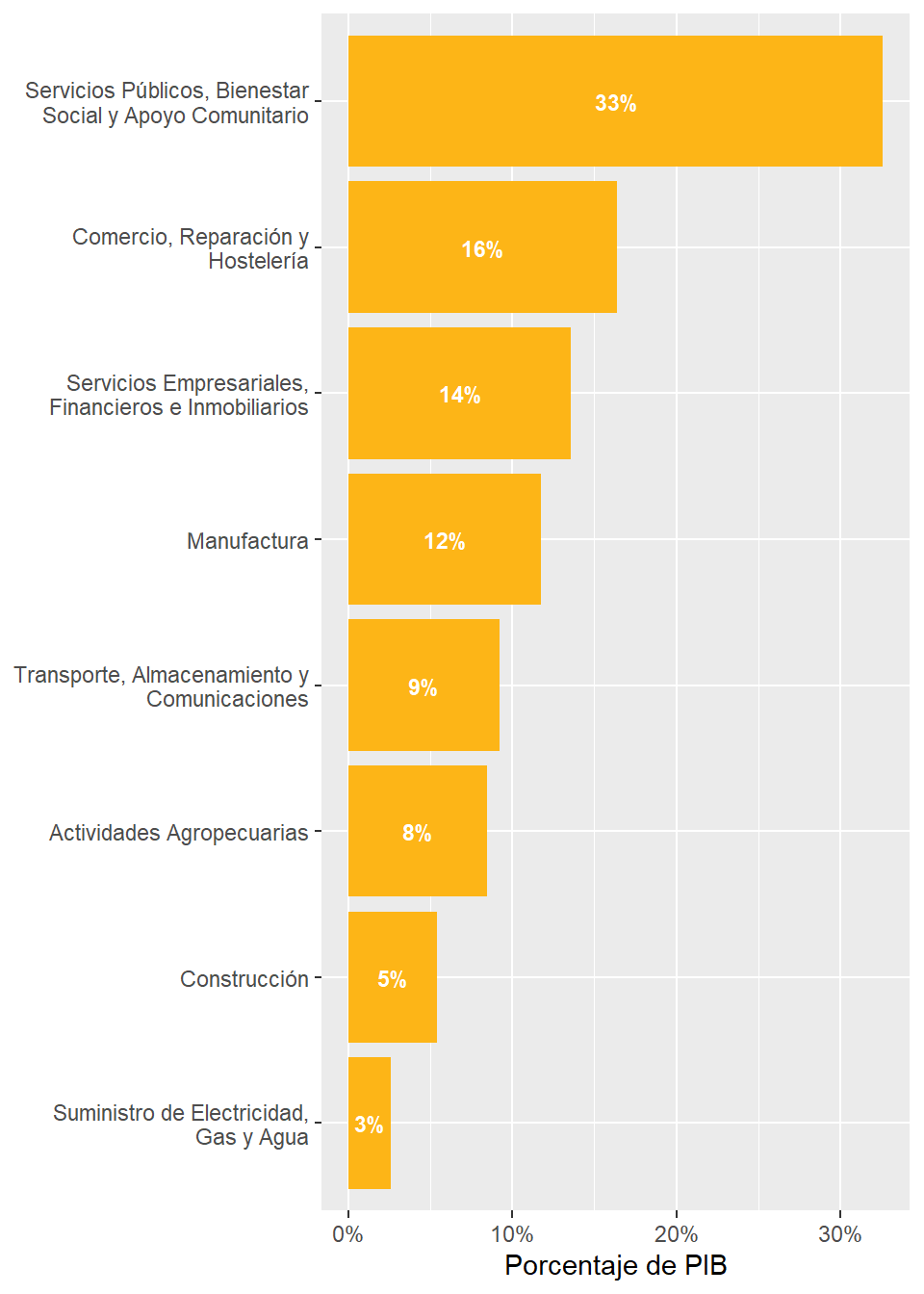
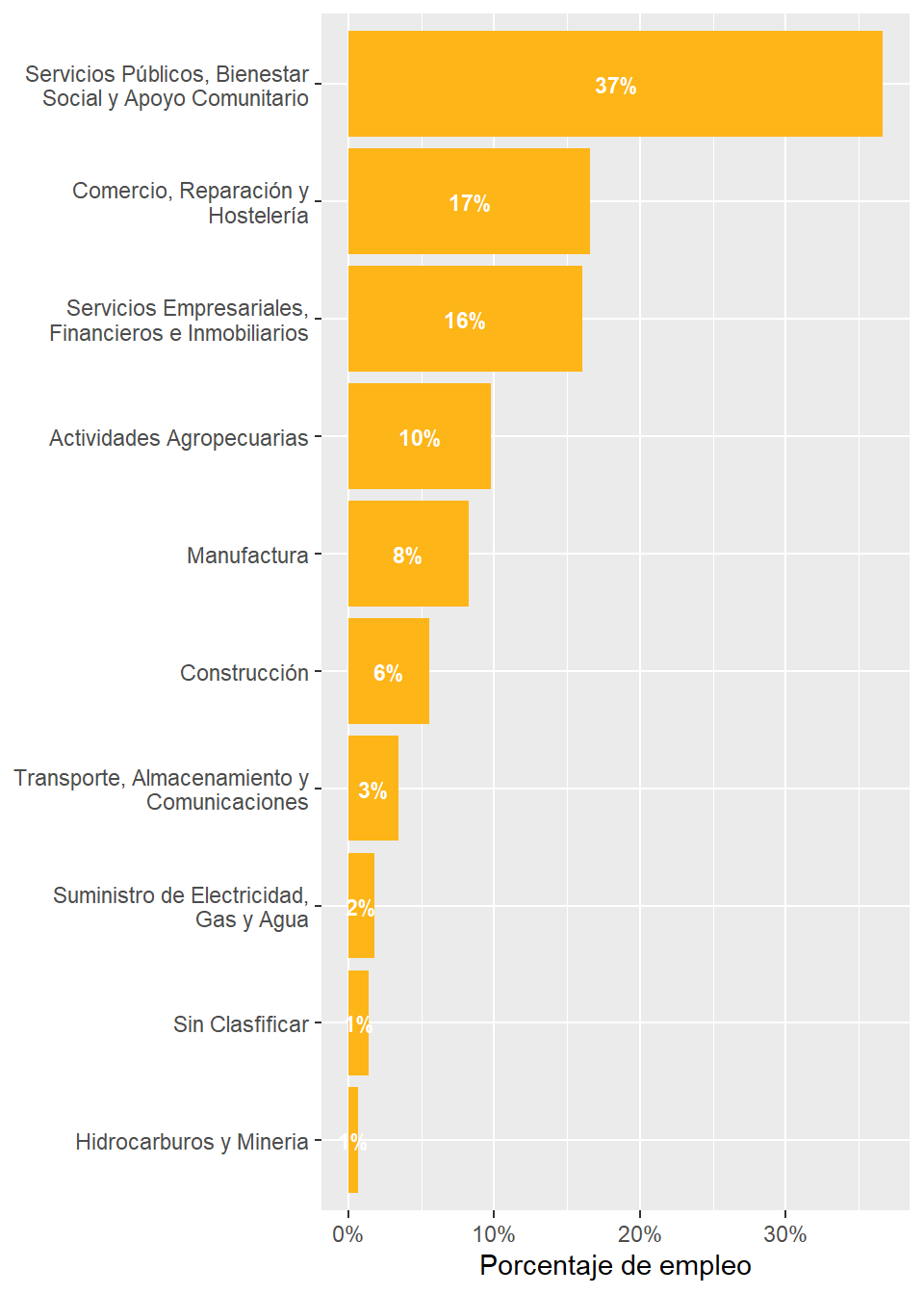
rubro_country_emp%>%ungroup()%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="URY")%>%select(rubro_resumen,employment_share,share)%>%arrange(desc(share))%>% gt::gt()%>% gt::fmt_percent(columns =c("share","employment_share"))%>% gt::cols_label( .list =list("rubro_resumen"="Rubro","employment_share"="Porcentaje de Empleo","share"="Porcentaje de PIB" ))
Rubro
Porcentaje de Empleo
Porcentaje de PIB
Servicios Públicos, Bienestar Social y Apoyo Comunitario
36.66%
32.60%
Comercio, Reparación y Hostelería
16.58%
16.37%
Servicios Empresariales, Financieros e Inmobiliarios
16.02%
13.59%
Manufactura
8.24%
11.77%
Transporte, Almacenamiento y Comunicaciones
3.41%
9.20%
Actividades Agropecuarias
9.75%
8.46%
Construcción
5.53%
5.41%
Suministro de Electricidad, Gas y Agua
1.78%
2.60%
Hidrocarburos y Mineria
0.64%
NA
Sin Clasfificar
1.39%
NA
Code
rubro_country_emp%>%left_join(cepal_pib,by=c("country_code","rubro_resumen"))%>%filter(country_code=="URY")%>%ggplot(aes(x=employment_share,y=share))+ ggrepel::geom_text_repel(aes(label=rubro_resumen),size=3)+geom_point(aes(fill=country_code),shape=21,size=3)+scale_fill_manual(values = country_colors, guide="none")+scale_y_continuous(labels=scales::percent_format())+scale_x_continuous(labels=scales::percent_format())+labs(y="Porcentaje de PIB (2022)",x="Porcentaje de Empleo (2022)")
Discussing occupational codes in online job postings data [DONE]
The occupation classification system is O*NET SOC 19.
O*NET SOC 19 is compatible with SOC 18.
SOC 18 allows us to classify jobs into occupational major and minor groups, as well as to use wage estimates of the US to categorize them into high, medium, and low wage occupations.
More importantly, SOC 18 groups are compatible with SOC 10 groups, and SOC 10 groups are compatible with IDB occupational groups
There are 9 occupations without the proper occupational title in English. That must be due to an error in the ETL process. Will notify Eric.
The Uruguay file doesn’t have the Dynamic Flexibility sub ability.
There are vacancies with null sector weights (don’t belong to any sector.) Will notify Eric.
**How we made sure O*NET SOC 19 was used to name the occupations?**
We load the list of occupational titles in Argentina, Urugay and Chile vacancies’ samples and compare it with the official O*NET SOC 19 catalog.
We find a perfect match.
Code
# load three files and keep occupations data. store in csv for lateridb_occupations<-rbind(read_parquet("raw/arg_new_dict.parquet")|>distinct(occupation,onet_job),read_parquet("raw/chl_new_dict.parquet")|>distinct(occupation,onet_job) ,read_parquet("raw/ury_new_dict.parquet")|>distinct(occupation,onet_job))|>distinct()write_csv(idb_occupations,"data/idb_occupations_in_data.csv")
Code
# load onet catelogonet_19<-read_csv("raw/catalogs_and_crosswalks/onet_2019_occupations.csv")# load the afore created list of occupations in vacancy dataidb_occupations<-read_csv("data/idb_occupations_in_data.csv")
Code
# isolate english titles (the official ones)ibd_occupations_en<-idb_occupations%>%distinct(occupation)# count how many occupations are in the vacancies dataar_occs<-nrow(ibd_occupations_en)# check if they match the onetsoc19 crosswalkoccs_in_onet_19<-ibd_occupations_en|>select(occupation)|>inner_join(onet_19, by=c("occupation"="onet_soc_title_19"))|>nrow()print(paste("There are ",ar_occs,"occupations in the arg, ury and chl data"))
[1] "There are 758 occupations in the arg, ury and chl data"
Code
print(paste(occs_in_onet_19,"of these occupations were found in SOC O*NET 19 catalog"))
[1] "757 of these occupations were found in SOC O*NET 19 catalog"
# A tibble: 15 × 3
occupation onet_soc_code_19 onet_soc_desc_19
<chr> <chr> <chr>
1 Labor Relations Specialists 13-1075.00 Resolve dispute…
2 Foreign Language and Literature Teachers, … 25-1124.00 Teach languages…
3 Construction and Building Inspectors 47-4011.00 Inspect structu…
4 Accountants and Auditors 13-2011.00 Examine, analyz…
5 Retail Salespersons 41-2031.00 Sell merchandis…
6 Cooks, Restaurant 35-2014.00 Prepare, season…
7 Cashiers 41-2011.00 Receive and dis…
8 Chefs and Head Cooks 35-1011.00 Direct and may …
9 Executive Secretaries and Executive Admini… 43-6011.00 Provide high-le…
10 Industrial Engineering Technologists and T… 17-3026.00 Apply engineeri…
11 First-Line Supervisors of Production and O… 51-1011.00 Directly superv…
12 Waiters and Waitresses 35-3031.00 Take orders and…
13 Potters, Manufacturing 51-9195.05 Operate product…
14 Aircraft Mechanics and Service Technicians 49-3011.00 Diagnose, adjus…
15 Multiple Machine Tool Setters, Operators, … 51-4081.00 Set up, operate…
Every occupation in spanish should have its’ english counterpart. Some doesn’t
Code
# There are occupation titles in spanish (onet_job) with no occupation title in english (occupation)print('There are occupation titles in spanish (onet_job) with no occupation title in english (occupation)')
[1] "There are occupation titles in spanish (onet_job) with no occupation title in english (occupation)"
# A tibble: 27 × 2
occupation onet_job
<chr> <chr>
1 <NA> Conductores de Vehículos de Servicios de Transporte y Choferes
2 <NA> Analistas Financieros y de Inversiones
3 <NA> Diseñadores de Programas Software
4 <NA> Auxiliares Docentes de Educación Especial
5 <NA> Técnicos de Emergencias Médicas
6 <NA> Científico de Datos
7 <NA> Maestros de Educación Especial de Jardín de Infantes
8 <NA> Gerentes de Instalaciones
9 <NA> Analistas Forenses Digitales
10 <NA> Administradores de Seguridad
# ℹ 17 more rows
We are able to map these O*NET SOC 19 to SOC 18 detailed, and major occupations
Code
# read onet_soc19 to soc18 crosswalkonetsoc19_soc18_crosswalk<-read_csv("raw/catalogs_and_crosswalks/onet_2019_to_soc_18_crosswalk.csv")|> janitor::clean_names()# attach soc18 broad, minor groups datasoc18_groups<-read_csv("raw/catalogs_and_crosswalks/soc_structure_2018_clean.csv")|> janitor::clean_names()%>%rename( x2018_soc_code=1 ,x2018_soc_title=2)# there is an almost perfect match ( no duplicates, only one missing)onetsoc19_soc18_full_crosswalk<-onetsoc19_soc18_crosswalk %>%inner_join(soc18_groups)# this is the resulthead(onetsoc19_soc18_full_crosswalk)
# this is the occupation without soc 18 informationonetsoc19_soc18_crosswalk %>%anti_join(soc18_groups)
# A tibble: 2 × 4
o_net_soc_2019_code o_net_soc_2019_title x2018_soc_code x2018_soc_title
<chr> <chr> <chr> <chr>
1 33-3051.00 Police and Sheriff's Patro… 33-3051 Police and She…
2 33-3051.04 Customs and Border Protect… 33-3051 Police and She…
Understanding Uruguay demand by occupation
There is demand for personal service, but not so much for healthcare highly technical services. However, sample size is so small one needs to be cautions when drawing conclusions about these sectors. Specially for Uruguay, it’s best to focus on larger sample occupational groups like “Sales and Related”, “Office and Administrative Support” etc.
Code
contratictory_major_soc<-c("Personal Care and Service Occupations","Healthcare Support Occupations","Healthcare Practitioners and Technical Occupations")south_cone_df %>%filter(country_code=="URY") %>%filter(major_group_title %in% contratictory_major_soc) %>%group_by(major_group_title, occupation) %>%summarise(postings=n()) %>%group_by(major_group_title) %>%top_n(5,postings) %>%left_join(south_cone_df %>%filter(country_code=="URY") %>%group_by(occupation) %>%summarize(mean_zones=mean(zones))) %>%ungroup() %>%head(15) %>%gt()
major_group_title
occupation
postings
mean_zones
Healthcare Practitioners and Technical Occupations
Acupuncturists
3
5
Healthcare Practitioners and Technical Occupations
Dentists, General
3
5
Healthcare Practitioners and Technical Occupations
Ophthalmologists, Except Pediatric
6
5
Healthcare Practitioners and Technical Occupations
Orthodontists
3
5
Healthcare Practitioners and Technical Occupations
Pharmacists
5
5
Healthcare Practitioners and Technical Occupations
Registered Nurses
3
4
Healthcare Support Occupations
Home Health Aides
1
2
Healthcare Support Occupations
Nursing Assistants
4
3
Healthcare Support Occupations
Personal Care Aides
7
2
Healthcare Support Occupations
Pharmacy Aides
2
2
Personal Care and Service Occupations
Childcare Workers
6
2
Personal Care and Service Occupations
Costume Attendants
3
2
Personal Care and Service Occupations
First-Line Supervisors of Personal Service Workers
15
3
Personal Care and Service Occupations
Manicurists and Pedicurists
3
2
Personal Care and Service Occupations
Nannies
13
2
Google jobs abilities compared to O*NET’s
The prevalence of subabilities in online job vacancies can by grouped by occupation and contrasted with the level and importance scores O*NET Analysts assigned to each subability in each occupation profile.
If we find that online vacancies in the South Cone require different skills than what O*NET experts said is important to perform at a job we’ll have an interesting discussion about what the Vacancies Minning algorithm is doing and how different are the same occupations across different countries.
Code
# how important is that they have acceptable proficiency in this abilityabilties_importance<-read_delim("raw/ONET_28_0/Abilities.txt") %>% janitor::clean_names() %>%filter(scale_id=="IM")# How good people must be at this abilityabilties_level<-read_delim("raw/ONET_28_0/Abilities.txt") %>% janitor::clean_names() %>%filter(scale_id=="LV")# How many abilities in our vacancies data are in ONETtable(str_replace_all(subabilities,"_"," ") %in%unique(abilties_importance$element_name))# How many onet abilities are in our vacancies data?table(unique(abilties_importance$element_name) %in%str_replace_all(subabilities,"_"," "))
Code
# I average subabilities weights in job vacancies data by occupation (ONETsoc19)onet_soc_19_df<-south_cone_df %>%select(doc_id, occupation,o_net_soc_2019_code, subabilities) %>%group_by(o_net_soc_2019_code) %>%summarise(across(subabilities, mean)) %>%# traspose the datapivot_longer(cols = subabilities,names_to ="element_name",values_to ="idb_value") %>%# remove _ in element_namemutate(element_name=str_replace_all(element_name,"_"," ")) %>%# I join the importance and level scores in onetleft_join(abilties_importance %>%select(o_net_soc_code,element_name,importance_value=data_value,importance_sd=standard_error,importance_n=n),by=c("o_net_soc_2019_code"="o_net_soc_code","element_name"="element_name")) %>%left_join(abilties_level %>%select(o_net_soc_code,element_name,level_value=data_value,level_sd=standard_error,level_n=n),by=c("o_net_soc_2019_code"="o_net_soc_code","element_name"="element_name")) library(GGally)onet_soc_19_df %>%select(ends_with("value")) %>%ggpairs()+labs(title ="There is a strong correlation between IDB abilities scores and O*NET importance and level indicators",subtitle ="Each dot is an occupation-ability combination")
Figure 70: ?(caption)
Discussing the sector (rama) information available in online job postings data (DONE)
The names of the 20 presented ramas coincide with NAICS 2-digits classifications. Most LAC data sources show employment estimates by industry in ISIC or ISIC-related codes.
Interestingly, the sector or “Rama” is across multiple columns and each doc_id can have multiple values. There isn’t a categorical classification of the rama each firm belongs to, but rather a continuous one, where there are wegiths representing the chances a firm belongs to each sector.
They don’t assing a category, but rather a 20 positions vector that gives probabilities from 0 to 1 to each vacancy.
I found a couple of puzzling things in the data.:
There are doc_ids with no prediction. They don’t belong to any sector.
There are (ties) doc_ids with the same positive prediciton. This turns makes any attempt to assign only one sector to each posting a little polemic.
test1<-df_ar |>select(doc_id,sectors)|>pivot_longer(cols=2:21,names_to="sector",values_to="value")|># Assume zero means not in this sector.# filter(value!=0) mutate(is_zero=ifelse(value==0,"Is zero","Not zero"))%>%group_by(doc_id,is_zero) %>%count()%>%ungroup()# lo guardo como referenciawrite_csv(test1,"data/pregunta_ramas_per_doc_id_arg.csv")# The representative document has a value different than 0 in 2.24 industries test1%>%group_by(is_zero)%>%summarise(mean_casos=mean(n))
# A tibble: 2 × 2
is_zero mean_casos
<chr> <dbl>
1 Is zero 17.8
2 Not zero 2.24
Code
# If I keep the max value for each document I see that max_total_rama<-df_ar |>select(doc_id,sectors)|>pivot_longer(cols=2:21,names_to="sector",values_to="value")|>group_by(doc_id)|>mutate(total=sum(value))%>%filter(value==max(value))%>%mutate(n=n())%>%ungroup()head(max_total_rama)
# A tibble: 6 × 5
doc_id sector value total n
<chr> <chr> <dbl> <dbl> <int>
1 IcBBOjuXZT8BiD2XAAAAAA== other_services_except_public_admin… 79 79 1
2 ct1JrwQ54xivPQpxAAAAAA== educational_services 99 99 1
3 bo7X77th8vwAAAAAAAAAAA government 43 78 1
4 72DNO-KNkrEAAAAAAAAAAA government 43 78 1
5 kqPOGYOTJTYAAAAAAAAAAA professional_scientific_and_techni… 31 31 1
6 If6uaYoqh6CHO4dpAAAAAA== other_services_except_public_admin… 79 79 1